LRU 캐시란 무엇입니까?
캐시 교체 알고리즘은 공간이 가득 차면 캐시를 교체하도록 효율적으로 설계되었습니다. 그만큼 가장 최근에 사용됨 (LRU)는 이러한 알고리즘 중 하나입니다. 이름에서 알 수 있듯이 캐시 메모리가 가득 찼을 때, LRU 가장 최근에 사용되지 않은 데이터를 선택하고 새 데이터를 위한 공간을 확보하기 위해 이를 제거합니다. 캐시에 있는 데이터의 우선순위는 해당 데이터의 필요에 따라 변경됩니다. 즉, 최근에 일부 데이터를 가져오거나 업데이트한 경우 해당 데이터의 우선순위가 변경되어 가장 높은 우선순위에 할당되고, 작업 후 사용되지 않은 작업으로 남아 있습니다.
내용의 테이블
- LRU 캐시란 무엇입니까?
- LRU 캐시에 대한 작업:
- LRU 캐시 작동:
- LRU 캐시를 구현하는 방법:
- 대기열 및 해싱을 사용한 LRU 캐시 구현:
- 이중 연결 목록 및 해싱을 사용한 LRU 캐시 구현:
- Deque 및 Hashmap을 사용한 LRU 캐시 구현:
- 스택 및 해시맵을 사용한 LRU 캐시 구현:
- 카운터 구현을 사용한 LRU 캐시:
- 지연 업데이트를 사용한 LRU 캐시 구현:
- LRU 캐시의 복잡성 분석:
- LRU 캐시의 장점:
- LRU 캐시의 단점:
- LRU 캐시의 실제 적용:
LRU 알고리즘은 표준 문제이며 운영 체제 등 필요에 따라 변형될 수 있습니다. LRU 페이지 결함을 최소화하기 위한 페이지 교체 알고리즘으로 사용될 수 있으므로 중요한 역할을 합니다.
LRU 캐시에 대한 작업:
- LRUCache(용량 c): 양수 크기 용량으로 LRU 캐시 초기화 씨.
- (열쇠)를 얻으세요 : Key '의 값을 반환합니다. 케이' 캐시에 있으면 그렇지 않으면 -1을 반환합니다. 또한 LRU 캐시에 있는 데이터의 우선순위를 업데이트합니다.
- 넣다(키, 값): 해당 키가 존재하는 경우 키 값을 업데이트하고, 그렇지 않으면 캐시에 키-값 쌍을 추가합니다. 키 수가 LRU 캐시 용량을 초과한 경우 가장 최근에 사용된 키를 닫습니다.
LRU 캐시 작동:
용량 3의 LRU 캐시가 있고 다음 작업을 수행한다고 가정해 보겠습니다.
- (키=1, 값=A)를 캐시에 넣습니다.
- (키=2, 값=B)를 캐시에 넣습니다.
- (키=3, 값=C)를 캐시에 넣습니다.
- 캐시에서 (key=2) 가져오기
- 캐시에서 (key=4) 가져오기
- (키=4, 값=D)를 캐시에 넣습니다.
- (key=3, value=E)를 캐시에 넣습니다.
- 캐시에서 (key=4) 가져오기
- (키=1, 값=A)를 캐시에 넣습니다.
위의 작업은 아래 이미지와 같이 차례로 수행됩니다.
각 작업에 대한 자세한 설명:
- Put(키 1, 값 A) : LRU 캐시의 빈 용량은 3이므로 교체할 필요가 없으며 {1 : A}를 맨 위에 둡니다. 즉, {1 : A}가 가장 높은 우선순위를 갖습니다.
- Put(키 2, 값 B) : LRU 캐시의 빈 용량=2이므로 다시 교체할 필요가 없지만 이제 {2:B}가 가장 높은 우선순위를 갖고 {1:A}의 우선순위가 감소합니다.
- Put(키 3, 값 C) : 여전히 캐시에 빈 공간이 1개 있으므로 교체 없이 {3 : C}를 입력합니다. 이제 캐시가 가득 차고 현재 우선순위가 가장 높은 것부터 가장 낮은 것 순으로 {3:C}, {2:B입니다. }, {1:A}.
- 가져오기(키 2) : 이제 이 작업 중에 key=2의 값을 반환합니다. 또한 key=2가 사용되었으므로 이제 새 우선순위 순서는 {2:B}, {3:C}, {1:A}입니다.
- 가져오기(키 4): 키 4가 캐시에 없는 것을 확인하고 이 작업에 대해 '-1'을 반환합니다.
- Put(키 4, 값 D) : 캐시가 FULL인지 확인하고 이제 LRU 알고리즘을 사용하여 가장 최근에 사용된 키를 확인합니다. {1:A}의 우선순위가 가장 낮으므로 캐시에서 {1:A}를 제거하고 {4:D}를 캐시에 넣습니다. 새로운 우선순위 순서는 {4:D}, {2:B}, {3:C}입니다.
- Put(키 3, 값 E) : key=3은 값=C를 갖는 캐시에 이미 존재하므로 이 작업으로 인해 키가 제거되지 않고 오히려 key=3의 값이 '로 업데이트됩니다. 그리고' . 이제 새로운 우선순위는 {3:E}, {4:D}, {2:B}가 됩니다.
- 가져오기(키 4) : 키=4의 값을 반환합니다. 이제 새 우선순위는 {4:D}, {3:E}, {2:B}가 됩니다.
- Put(키 1, 값 A) : 캐시가 FULL이므로 LRU 알고리즘을 사용하여 가장 최근에 사용된 키를 확인하고 {2:B}의 우선순위가 가장 낮으므로 캐시에서 {2:B}를 제거하고 {1:A}를 은닉처. 이제 새로운 우선순위 순서는 {1:A}, {4:D}, {3:E}입니다.
LRU 캐시를 구현하는 방법:
LRU 캐시는 다양한 방식으로 구현될 수 있으며 각 프로그래머는 서로 다른 접근 방식을 선택할 수 있습니다. 그러나 일반적으로 사용되는 접근 방식은 다음과 같습니다.
- 큐와 해싱을 사용하는 LRU
- LRU를 사용하는 이중 연결리스트 + 해싱
- Deque를 사용하는 LRU
- 스택을 사용하는 LRU
- LRU를 사용하는 카운터 구현
- 지연 업데이트를 사용하는 LRU
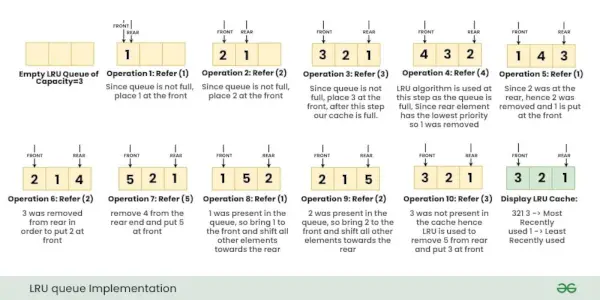
대기열 및 해싱을 사용한 LRU 캐시 구현:
우리는 LRU 캐시를 구현하기 위해 두 가지 데이터 구조를 사용합니다.
- 대기줄 이중 연결 리스트를 사용하여 구현됩니다. 대기열의 최대 크기는 사용 가능한 총 프레임 수(캐시 크기)와 같습니다. 가장 최근에 사용한 페이지는 프런트 엔드 근처에 있고 가장 최근에 사용된 페이지는 뒤쪽 엔드 근처에 있습니다.
- 해시 페이지 번호를 키로, 해당 대기열 노드의 주소를 값으로 사용합니다.
페이지를 참조할 때 필요한 페이지가 메모리에 있을 수 있습니다. 메모리에 있는 경우 목록의 노드를 분리하여 대기열 앞으로 가져와야 합니다.
필요한 페이지가 메모리에 없으면 해당 페이지를 메모리로 가져옵니다. 간단히 말해서 대기열 앞에 새 노드를 추가하고 해시에서 해당 노드 주소를 업데이트합니다. 큐가 꽉 차면, 즉 모든 프레임이 꽉 차면 큐 뒤쪽에서 노드를 제거하고 새 노드를 큐 앞쪽에 추가합니다.
삽화:
작업을 고려해 보겠습니다. 추천 열쇠 엑스 LRU 캐시에: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
메모: 처음에는 메모리에 페이지가 없습니다.아래 이미지는 LRU 캐시에서 위 작업의 단계별 실행을 보여줍니다.
연산:
- 순서가 지정되지 않은 맵인 int 유형의 목록을 선언하여 LRUCache 클래스를 만듭니다.
- LRUCache의 참조 기능에서
- 이 값이 대기열에 없으면 이 값을 대기열 앞에 푸시하고 대기열이 가득 차면 마지막 값을 제거합니다.
- 값이 이미 존재하는 경우 대기열에서 해당 값을 제거하고 대기열 맨 앞으로 푸시합니다.
- 디스플레이 기능 인쇄에서 LRUCache는 앞에서 시작하는 대기열을 사용합니다.
다음은 위의 접근 방식을 구현한 것입니다.
C++
스캔.다음 자바
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::반복자> ma;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
씨
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->페이지번호 = 페이지번호;> > >// Initialize prev and next as NULL> >temp->이전 = 임시->다음 = NULL;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->개수 = 0;> >queue->전면 = 대기열-> 후면 = NULL;> > >// Number of frames that can be stored in memory> >queue->numberOfFrames = numberOfFrames;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->용량 = 용량;> > >// Create an array of pointers for referring queue nodes> >hash->배열> >= (QNode**)>malloc>(hash->용량 *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->배열[i] = NULL;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->개수 == 대기열->numberOfFrames;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->후면 == NULL;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->앞 == 대기열->뒤)> >queue->앞 = NULL;> > >// Change rear and remove the previous rear> >QNode* temp = queue->뒤쪽;> >queue->후면 = 대기열->후면->이전;> > >if> (queue->후면)> >queue->후면->다음 = NULL;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->세다--;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->배열[queue->rear->pageNumber] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->다음 = 대기열->앞;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->후면 = 대기열->전면 = 임시;> >else> // Else change the front> >{> >queue->앞->이전 = 임시;> >queue->전면 = 온도;> >}> > >// Add page entry to hash also> >hash->배열[페이지번호] = 임시;> > >// increment number of full frames> >queue->카운트++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->배열[페이지번호];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->앞) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->이전->다음 = reqPage->다음;> >if> (reqPage->다음)> >reqPage->다음->이전 = reqPage->이전;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->후면) {> >queue->후면 = reqPage->prev;> >queue->후면->다음 = NULL;> >}> > >// Put the requested page before current front> >reqPage->다음 = 대기열->앞;> >reqPage->이전 = NULL;> > >// Change prev of current front> >reqPage->다음->이전 = reqPage;> > >// Change front to the requested page> >queue->앞 = reqPage;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->앞->페이지번호);> >printf>(>'%d '>, q->앞->다음->페이지번호);> >printf>(>'%d '>, q->앞->다음->다음->페이지번호);> >printf>(>'%d '>, q->앞->다음->다음->다음->페이지번호);> > >return> 0;> }> |
>
>
자바
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
파이썬3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
씨#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>이중 대기열;> > >// store references of key in cache> >private> HashSet<>int>>해시세트;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
자바스크립트
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
이중 연결 목록 및 해싱을 사용한 LRU 캐시 구현 :
아이디어는 매우 기본적입니다. 즉, 요소를 머리 부분에 계속 삽입하는 것입니다.
- 요소가 목록에 없으면 목록의 머리 부분에 추가하십시오.
- 요소가 목록에 있으면 해당 요소를 헤드로 이동하고 목록의 나머지 요소를 이동합니다.
노드의 우선순위는 헤드에서 해당 노드까지의 거리에 따라 달라지며, 노드가 헤드에 가까울수록 우선순위가 높습니다. 따라서 캐시 크기가 가득 차서 일부 요소를 제거해야 하는 경우 이중 연결 목록의 꼬리에 인접한 요소를 제거합니다.
Deque 및 Hashmap을 사용한 LRU 캐시 구현:
Deque 데이터 구조는 앞과 끝에서 삽입 및 삭제를 허용합니다. 이 속성을 사용하면 앞 요소가 높은 우선 순위 요소를 나타낼 수 있고 끝 요소가 낮은 우선 순위 요소, 즉 가장 최근에 사용된 요소가 될 수 있으므로 LRU 구현이 가능합니다.
일하고 있는:
- 작업 받기 : 캐시의 해시 맵에 키가 존재하는지 확인하고 데크에 대해서는 다음과 같은 경우를 따릅니다.
- 열쇠가 발견된 경우:
- 해당 항목은 최근에 사용한 것으로 간주되어 데크 앞으로 이동됩니다.
- 키와 관련된 값은 다음의 결과로 반환됩니다.
get>작업.- 키를 찾을 수 없는 경우:
- 해당 키가 없음을 나타내려면 -1을 반환합니다.
- 풋 작업: 먼저 캐시의 해시 맵에 키가 이미 존재하는지 확인하고 데크에 대해 아래 사례를 따릅니다.
- 키가 존재하는 경우:
- 키와 연결된 값이 업데이트됩니다.
- 해당 항목은 현재 가장 최근에 사용된 항목이므로 데크 앞으로 이동됩니다.
- 키가 존재하지 않는 경우:
- 캐시가 가득 차면 새 항목을 삽입해야 하고 가장 최근에 사용한 항목을 제거해야 함을 의미합니다. 이는 데크 끝의 항목과 해시 맵의 해당 항목을 제거하여 수행됩니다.
- 그런 다음 새 키-값 쌍이 해시 맵과 데크 전면에 삽입되어 가장 최근에 사용된 항목임을 나타냅니다.
스택 및 해시맵을 사용한 LRU 캐시 구현:
스택 데이터 구조와 해싱을 사용하여 LRU(Least Recent Used) 캐시를 구현하는 것은 간단한 스택이 가장 최근에 사용되지 않은 항목에 대한 효율적인 액세스를 제공하지 않기 때문에 약간 까다로울 수 있습니다. 그러나 스택을 해시 맵과 결합하여 이를 효율적으로 달성할 수 있습니다. 이를 구현하기 위한 높은 수준의 접근 방식은 다음과 같습니다.
- 해시 맵 사용 : 해시 맵은 캐시의 키-값 쌍을 저장합니다. 키는 스택의 해당 노드에 매핑됩니다.
- 스택 사용 : 스택은 사용법에 따라 키의 순서를 유지합니다. 가장 최근에 사용한 항목은 스택의 맨 아래에 배치되고 가장 최근에 사용한 항목은 맨 위에 배치됩니다.
이 접근 방식은 그다지 효율적이지 않으므로 자주 사용되지 않습니다.
특수문자 이름
카운터 구현을 사용한 LRU 캐시:
캐시의 각 블록에는 카운터 값이 속하는 자체 LRU 카운터가 있습니다. {0 ~ n-1} , 여기 ' N '는 캐시의 크기를 나타냅니다. 블록 교체 시 변경된 블록은 MRU 블록이 되며, 그 결과 카운터 값은 n – 1로 변경됩니다. 액세스한 블록의 카운터 값보다 큰 카운터 값은 1씩 감소합니다. 나머지 블록은 변경되지 않습니다.
| 콘터의 가치 | 우선 사항 | 중고상태 |
|---|---|---|
| 0 | 낮은 | 가장 최근에 사용됨 |
| n-1 | 높은 | 가장 최근에 사용됨 |
지연 업데이트를 사용한 LRU 캐시 구현:
지연 업데이트를 사용하여 LRU(Least Recent Used) 캐시를 구현하는 것은 캐시 작업의 효율성을 향상시키는 일반적인 기술입니다. 지연 업데이트에는 전체 데이터 구조를 즉시 업데이트하지 않고 항목에 액세스하는 순서를 추적하는 작업이 포함됩니다. 캐시 누락이 발생하면 일부 기준에 따라 전체 업데이트를 수행할지 여부를 결정할 수 있습니다.
LRU 캐시의 복잡성 분석:
- 시간 복잡도:
- Put() 작업: O(1) 즉, 새 키-값 쌍을 삽입하거나 업데이트하는 데 필요한 시간이 일정합니다.
- Get() 작업: O(1) 즉, 키 값을 가져오는 데 필요한 시간이 일정합니다.
- 보조 공간: O(N) 여기서 N은 캐시 용량입니다.
LRU 캐시의 장점:
- 빠른 액세스 : LRU 캐시에서 데이터에 접근하는데 O(1) 시간이 걸린다.
- 빠른 업데이트 : LRU 캐시에서 키-값 쌍을 업데이트하는 데 O(1) 시간이 걸립니다.
- 가장 최근에 사용된 데이터의 빠른 제거 : 최근에 사용하지 않은 것을 삭제하려면 O(1)이 필요합니다.
- 스래싱 없음: LRU는 페이지 사용 내역을 고려하므로 FIFO에 비해 스래싱에 덜 취약합니다. 자주 사용되는 페이지를 감지하고 메모리 할당에 대한 우선순위를 지정하여 페이지 오류 수와 디스크 I/O 작업을 줄일 수 있습니다.
LRU 캐시의 단점:
- 효율성을 높이려면 큰 캐시 크기가 필요합니다.
- 구현하려면 추가 데이터 구조가 필요합니다.
- 하드웨어 지원이 높습니다.
- LRU에서는 오류 감지가 다른 알고리즘에 비해 어렵습니다.
- 수용 가능성이 제한되어 있습니다.
LRU 캐시의 실제 적용:
- 빠른 쿼리 결과를 위한 데이터베이스 시스템.
- 운영 체제에서 페이지 오류를 최소화합니다.
- 자주 사용하는 파일이나 코드 조각을 저장하는 텍스트 편집기 및 IDE
- 네트워크 라우터와 스위치는 LRU를 사용하여 컴퓨터 네트워크의 효율성을 높입니다.
- 컴파일러 최적화에서
- 텍스트 예측 및 자동 완성 도구