전제 조건 – 데이터 마이닝, 유사성 측정은 데이터 세트에서 데이터 개체의 기능을 나타내는 차원과의 거리를 나타냅니다. 이 거리가 가까우면 유사도가 높지만, 거리가 멀면 유사도가 낮습니다. 널리 사용되는 유사성 측정 중 일부는 다음과 같습니다.
- 유클리드 거리.
- 맨해튼 거리.
- 자카드 유사성.
- 민코프스키 거리.
- 코사인 유사성.
코사인 유사성 크기에 관계없이 데이터 객체가 얼마나 유사한지 결정하는 데 도움이 되는 측정항목입니다. 코사인 유사성을 사용하여 Python에서 두 문장 간의 유사성을 측정할 수 있습니다. 코사인 유사성에서는 데이터세트의 데이터 객체가 벡터로 처리됩니다. 두 벡터 사이의 코사인 유사성을 찾는 공식은 다음과 같습니다.
(x, y) = x . y / ||x|| ||y||>
어디,
- x . y = 벡터 'x'와 'y'의 곱(점).||x|| 그리고 ||그리고|| = 두 벡터 'x'와 'y'의 길이(크기).||x||
 ||그리고|| = 두 벡터 'x'와 'y'의 정규 곱.
||그리고|| = 두 벡터 'x'와 'y'의 정규 곱. 예 : 두 벡터 사이의 유사성을 찾는 예를 생각해보십시오. '엑스' 그리고 '그리고' , 코사인 유사성을 사용합니다. 'x' 벡터에는 값이 있습니다. x = { 3, 2, 0, 5 } 'y' 벡터에는 값이 있습니다. y = { 1, 0, 0, 0 } 코사인 유사성을 계산하는 공식은 다음과 같습니다.  (x, y) = x. y / ||x|| ||그리고||
(x, y) = x. y / ||x|| ||그리고||
x . y = 3*1 + 2*0 + 0*0 + 5*0 = 3 ||x|| = √ (3)^2 + (2)^2 + (0)^2 + (5)^2 = 6.16 ||y|| = √ (1)^2 + (0)^2 + (0)^2 + (0)^2 = 1 ∴ (x, y) = 3 / (6.16 * 1) = 0.49>
두 벡터 'x'와 'y' 사이의 차이점은 다음과 같습니다.
∴ (x, y) = 1 - (x, y) = 1 - 0.49 = 0.51>
- 두 벡터 사이의 코사인 유사성은 'θ'로 측정됩니다.
- θ = 0°이면 'x'와 'y' 벡터가 겹쳐서 유사하다는 것을 증명합니다.
- θ = 90°이면 'x'와 'y' 벡터는 서로 다릅니다.
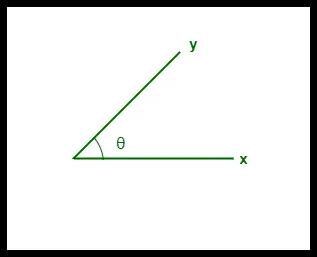
두 벡터 간의 코사인 유사성
장점:
- 코사인 유사성은 두 개의 유사한 데이터 객체가 크기 때문에 유클리드 거리만큼 멀리 떨어져 있더라도 여전히 그들 사이의 각도가 더 작을 수 있기 때문에 유용합니다. 각도가 작을수록 유사성이 높아집니다.
- 다차원 공간에 플롯할 때 코사인 유사성은 크기가 아닌 데이터 개체의 방향(각도)을 캡처합니다.