Linux의 cut 명령은 파일의 각 줄에서 섹션을 잘라내어 그 결과를 표준 출력에 쓰는 명령입니다. 바이트 위치, 문자 및 필드별로 줄의 일부를 자르는 데 사용할 수 있습니다. cut 명령은 한 줄을 자르고 텍스트를 추출합니다. 명령과 함께 옵션을 지정해야 합니다. 그렇지 않으면 오류가 발생합니다. 파일 이름이 두 개 이상 제공되면 각 파일의 데이터 앞에 해당 파일 이름이 붙지 않습니다.
내용의 테이블
- cut 명령의 구문
- 절단 명령에서 사용 가능한 옵션
- Cut 명령의 실제 예
- cut 명령을 사용하여 특정 바이트 추출(-b)
- 문자별 잘라내기(-c) 잘라내기 명령 사용
- 필드별 잘라내기(-f) 잘라내기 명령 사용
- 출력 보완(–complement) cut 명령 사용
- 출력 구분 기호(-output-delimiter) cut 명령 사용
- 버전 표시(–version) cut 명령 사용
- 컷 명령에서 파이프(|)와 함께 꼬리를 사용하는 방법
- Linux의 cut 명령에 대해 자주 묻는 질문 – FAQ
cut 명령의 구문
기본 구문은cut>명령은 다음과 같습니다
cut OPTION... [FILE]...>
어디
`OPTION`> 원하는 동작을 지정합니다.
` FILE> `>입력 파일을 나타냅니다.
메모 : 만약에FILE>지정되지 않았습니다. ` cut`> 표준 입력(stdin)에서 읽습니다.
절단 명령에서 사용 가능한 옵션
다음은 `와 함께 가장 일반적으로 사용되는 옵션 목록입니다. cut`> 명령:
| 옵션 | 설명 |
|---|---|
| -b, –바이트=LIST | 다음에 지정된 바이트만 선택합니다. |
| -c, –문자=LIST | 에 지정된 문자만 선택합니다. |
| -d, –구분자=분할 | 용도 |
| -f, –필드=LIS | 다음에 지정된 필드만 선택합니다. |
| -N | 멀티바이트 문자를 분할하지 마십시오. |
| -보어 | 필드/문자 선택을 반전합니다. 선택하지 않은 필드/문자를 인쇄합니다. |
Cut 명령의 실제 예
이름이 있는 두 개의 파일을 고려해 보겠습니다. 상태.txt 그리고 자본금.txt 인도의 주와 수도의 이름이 각각 5개 포함되어 있습니다.
$ cat state.txt Andhra Pradesh Arunachal Pradesh Assam Bihar Chhattisgarh>
옵션을 지정하지 않으면 오류가 표시됩니다.
$ cut state.txt cut: you must specify a list of bytes, characters, or fields Try 'cut --help' for more information.>
특정 바이트 추출(-b>) cut 명령 사용
-b(바이트): 특정 바이트를 추출하려면 쉼표로 구분된 바이트 번호 목록과 함께 -b 옵션을 따라야 합니다. 하이픈(-)을 사용하여 바이트 범위를 지정할 수도 있습니다. 바이트 번호 목록을 지정해야 합니다. 그렇지 않으면 오류가 발생합니다.
탭과 백스페이스 1바이트의 문자처럼 취급됩니다.
범위가 없는 목록 :
cut -b 1,2,3 state.txt>
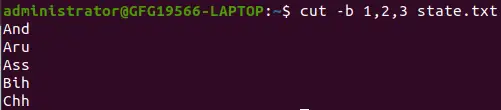
범위가 없는 목록
범위가 포함된 목록:
cut -b 1-3,5-7 state.txt>
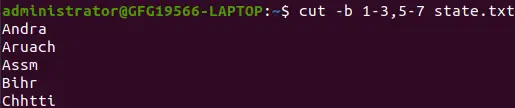
범위가 있는 목록
줄의 처음부터 끝까지 바이트를 선택하기 위해 특별한 형식을 사용합니다.
특수 형식: 줄의 처음부터 끝까지 바이트 선택
여기서 1-은 라인의 첫 번째 바이트부터 끝 바이트까지를 나타냅니다.
cut -b 1- state.txt>
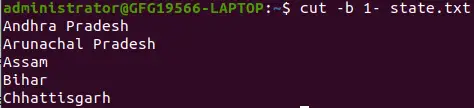
-b 옵션을 사용한 특수 형식
여기서 -3은 라인의 첫 번째 바이트부터 세 번째 바이트까지를 나타냅니다.
cut -b -3 state.txt>
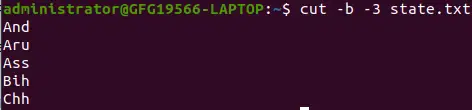
특수 형식 -b 옵션
문자별로 잘라내기(-c>) cut 명령 사용
-c(열): 문자별로 잘라내려면 -c 옵션을 사용하십시오. -c 옵션에 지정된 문자를 선택합니다. 이는 쉼표로 구분된 숫자 목록이거나 하이픈(-)으로 구분된 숫자 범위일 수 있습니다.
탭과 백스페이스 캐릭터로 취급됩니다. 문자 번호 목록을 지정해야 합니다. 그렇지 않으면 이 옵션을 사용하면 오류가 발생합니다.
통사론:
cut -c [(k)-(n)/(k),(n)/(n)] filename>
여기, 케이 문자의 시작 위치를 나타냅니다. N 다음과 같은 경우 각 줄의 문자 끝 위치를 나타냅니다. 케이 그리고 N 로 구분됩니다. 그렇지 않으면 입력으로 사용되는 파일의 각 줄에 있는 문자 위치일 뿐입니다.
특정 문자 추출:
cut -c 2,5,7 state.txt>
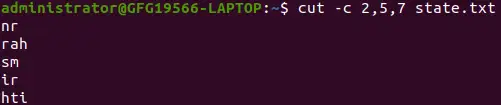
특정 문자 추출
위의 잘라내기 명령은 파일의 각 줄에서 두 번째, 다섯 번째, 일곱 번째 문자를 인쇄합니다.
처음 7자를 추출합니다.
cut -c 1-7 state.txt>
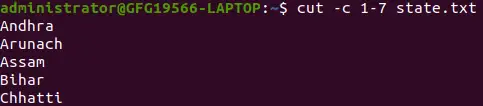
처음 7자를 추출합니다.
위의 잘라내기 명령은 파일에서 각 줄의 처음 7자를 인쇄합니다. Cut은 줄의 처음부터 끝까지 문자를 선택하기 위해 특별한 형식을 사용합니다.
특수 형식: 줄의 처음부터 끝까지 문자 선택
cut -c 1- state.txt>
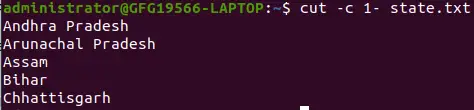
-c 옵션을 사용하여 줄의 처음부터 끝까지 문자 선택
위 명령은 첫 번째 문자부터 끝까지 인쇄합니다. 여기 명령에서는 시작 위치만 지정하고 끝 위치는 생략합니다.
cut -c -5 state.txt>
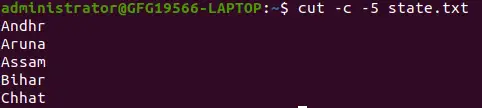
-c 옵션을 사용하여 줄의 처음부터 끝까지 문자 선택
위 명령은 시작 위치를 다섯 번째 문자로 인쇄합니다. 여기서는 시작 위치를 생략하고 종료 위치를 지정합니다.
필드별로 잘라내기(-f>) cut 명령 사용
-f(필드): -c 옵션은 고정 길이 라인에 유용합니다. 대부분의 유닉스 파일에는 고정 길이 줄이 없습니다. 유용한 정보를 추출하려면 열이 아닌 필드별로 잘라야 합니다. 지정된 필드 번호 목록은 쉼표로 구분되어야 합니다. 범위는 -f 옵션으로 설명되지 않습니다. . 자르다 용도 탭 기본 필드 구분 기호로 사용되지만 다음을 사용하여 다른 구분 기호와 함께 사용할 수도 있습니다. -디 옵션.
메모: UNIX에서는 공백이 구분 기호로 간주되지 않습니다.
통사론:
cut -d 'delimiter' -f (field number) file.txt>
첫 번째 필드 추출:
파일에 있는 것처럼 상태.txt -d 옵션을 사용하지 않으면 필드가 공백으로 구분되며 전체 줄이 인쇄됩니다.
cut -f 1 state.txt>
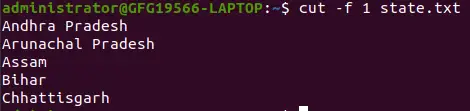
-f 옵션을 사용하여 첫 번째 필드 추출
만약 ` -d` 옵션을 사용하면 공백을 필드 구분 기호 또는 구분 기호로 간주합니다.
cut -d ' ' -f 1 state.txt>
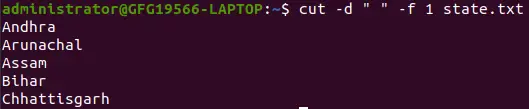
필드 구분 기호 또는 구분 기호로 사용되는 공백
필드 1~4를 추출합니다.
명령은 파일 각 줄의 첫 번째부터 네 번째까지 필드를 인쇄합니다.
cut -d ' ' -f 1-4 state.txt>

명령은 첫 번째부터 네 번째까지 필드를 인쇄합니다.
보완 출력(--complement>) cut 명령 사용
-보어: 이름에서 알 수 있듯이 출력을 보완합니다. 이 옵션은 다음과 같은 다른 옵션과 조합하여 사용할 수 있습니다. -에프 또는 -씨 .
cut --complement -d ' ' -f 1 state.txt>

-보어
cut --complement -c 5 state.txt>

-보어
출력 구분 기호(--output-delimiter>) cut 명령 사용
– 출력 구분 기호: 기본적으로 출력 구분 기호는 컷에서 지정한 입력 구분 기호와 동일합니다. -디 옵션. 출력 구분 기호를 변경하려면 옵션을 사용하십시오. –출력 구분 기호=구분 기호 .
cut -d ' ' -f 1,2 state.txt --output-delimiter='%'>

여기서 cut 명령은 -f 옵션을 사용하여 지정된 필드 사이의 표준 출력에서 구분 기호(%)를 변경합니다.
디스플레이 버전(--version>) cut 명령 사용
-버전: 이 옵션은 현재 시스템에서 실행 중인 컷 버전을 표시하는 데 사용됩니다.
cut --version>

잘라내기 명령의 버전 표시
컷 명령에서 파이프(|)와 함께 꼬리를 사용하는 방법
cut 명령은 유닉스의 다른 많은 명령과 함께 파이프될 수 있습니다. 다음 예제 출력에서는 고양이 명령은 입력으로 제공됩니다. 자르다 명령하다 -에프 state.txt 파일에서 나오는 상태 이름을 역순으로 정렬하는 옵션입니다.
cat state.txt | cut -d ' ' -f 1 | sort -r>

Cut 명령에서 파이프(|)와 함께 꼬리 사용
추가 처리를 위해 하나 이상의 필터를 파이프로 연결할 수도 있습니다. 다음 예에서와 같이 cat, head 및 cut 명령을 사용하고 있으며 그 출력은 directive(>)를 사용하여 list.txt 파일 이름에 저장됩니다.
cat state.txt | head -n 3 | cut -d ' ' -f 1>목록.txt>
cat list.txt>

굵은 글씨용 CSS
다른 파일로 출력 리디렉션
Linux의 cut 명령에 대해 자주 묻는 질문 – FAQ
어떻게 사용하나요? cut> 파일에서 특정 열을 추출하는 명령?
예: `라는 CSV 파일에서 첫 번째와 세 번째 열을 추출하려면 data.csv`> .
cut -d',' -f1,3 data.csv>
사용해도 되나요 cut> 각 줄에서 다양한 문자를 추출하려면?
그래 넌 할수있어. 이름이 지정된 파일의 각 줄에서 문자 5~10을 추출하려면text.txt>.
cut -c5-10 text.txt>
사용되는 구분 기호를 어떻게 변경할 수 있습니까? cut> 명령?
`를 사용하세요. -d`> 옵션 뒤에 구분 기호 문자가 옵니다. 예를 들어 콜론(:>)를 구분 기호로 사용합니다.
cut -d':' -f1,3 data.txt>
사용이 가능한가요? cut> 문자 위치를 기준으로 필드를 추출하려면?
예, `를 사용하여 문자 위치를 지정할 수 있습니다. -c`> 옵션. 예를 들어, 각 줄에서 1~5 및 10~15의 문자를 추출합니다.
cut -c1-5,10-15 data.txt>
어떻게 사용하나요? cut> 특정 구분 기호를 기반으로 필드를 추출하여 새 파일에 저장하려면?
쉼표로 구분된 필드를 추출하여 `라는 새 파일에 저장하려면 output.tx> t`>
cut -d',' -f1,3 data.csv>출력.txt>
결론
이 기사에서 우리는 다음에 대해 논의했습니다. ` cut`> 바이트 위치, 문자 또는 필드를 기반으로 파일에서 특정 섹션을 추출하는 다목적 도구인 Linux의 명령입니다. 텍스트 줄을 분할하고 추출된 데이터를 출력합니다. 옵션을 지정하지 못한 경우cut>명령으로 인해 오류가 발생합니다. 여러 파일을 처리할 수 있지만 출력에는 파일 이름이 포함되지 않습니다. `와 같은 옵션 -b`> , ` -c`> , 그리고 ` -f`> 각각 바이트, 문자, 필드별로 추출할 수 있습니다. 그만큼--complement>옵션은 선택 항목을 반전시켜 선택되지 않은 항목을 인쇄하고--output-delimiter>출력 구분 기호를 변경합니다. 이 명령에는 버전 표시 옵션도 포함되어 있으며 추가 처리를 위해 파이프를 통해 다른 명령과 함께 사용할 수 있습니다.
?list=PLqM7alHXFySFc4KtwEZTAngmyJm3NqS_L