- 거리 벡터 알고리즘은 동적 알고리즘입니다.
- 주로 ARPANET, RIP에서 사용됩니다.
- 각 라우터는 다음과 같은 거리 테이블을 유지합니다. 벡터 .
거리 벡터 라우팅 알고리즘의 작동을 이해하기 위한 세 가지 열쇠:
거리 벡터 라우팅 알고리즘
하자엑스(y) 노드 x에서 노드 y까지의 최소 비용 경로의 비용입니다. 최소 비용은 Bellman-Ford 방정식과 관련이 있습니다.
d<sub>x</sub>(y) = min<sub>v</sub>{c(x,v) + d<sub>v</sub>(y)} 어디 minv는 모든 x 이웃에 대해 취해진 방정식입니다. x에서 v로 이동한 후 v에서 y로의 최소 비용 경로를 고려하면 경로 비용은 c(x,v)+d가 됩니다.~에(와이). x에서 y까지의 최소 비용은 c(x,v)+d의 최소값입니다.~에(y) 모든 이웃을 점령했습니다.
거리 벡터 라우팅 알고리즘을 사용하면 노드 x에는 다음 라우팅 정보가 포함됩니다.
- 각 이웃 v에 대해 비용 c(x,v)는 x에서 직접 연결된 이웃 v까지의 경로 비용입니다.
- 거리 벡터 x, 즉 D엑스= [ 디엑스(y) : y in N ], N의 모든 목적지 y에 대한 비용을 포함합니다.
- 각 이웃의 거리 벡터, 즉 D~에= [ 디~에(y) : x의 각 이웃 v에 대한 y in N ]입니다.
거리 벡터 라우팅은 노드 x가 거리 벡터의 복사본을 모든 이웃에게 보내는 비동기 알고리즘입니다. 노드 x가 이웃 벡터 v 중 하나로부터 새 거리 벡터를 수신하면 v의 거리 벡터를 저장하고 Bellman-Ford 방정식을 사용하여 자체 거리 벡터를 업데이트합니다. 방정식은 다음과 같습니다.
오토캐드 늘이기 명령
d<sub>x</sub>(y) = min<sub>v</sub>{ c(x,v) + d<sub>v</sub>(y)} for each node y in N 노드 x는 위의 방정식을 사용하여 자신의 거리 벡터 테이블을 업데이트하고 업데이트된 테이블을 모든 이웃에게 전송하여 자신의 거리 벡터를 업데이트할 수 있도록 합니다.
연산
At each node x, <p> <strong>Initialization</strong> </p> for all destinations y in N: D<sub>x</sub>(y) = c(x,y) // If y is not a neighbor then c(x,y) = ∞ for each neighbor w D<sub>w</sub>(y) = ? for all destination y in N. for each neighbor w send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to w <strong>loop</strong> <strong>wait</strong> (until I receive any distance vector from some neighbor w) for each y in N: D<sub>x</sub>(y) = minv{c(x,v)+D<sub>v</sub>(y)} If D<sub>x</sub>(y) is changed for any destination y Send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to all neighbors <strong>forever</strong> 참고: 거리 벡터 알고리즘에서 노드 x는 직접 연결된 하나의 노드에서 비용 변화를 확인하거나 일부 이웃으로부터 벡터 업데이트를 받을 때 테이블을 업데이트합니다.
예를 통해 이해해 봅시다:
정보 공유
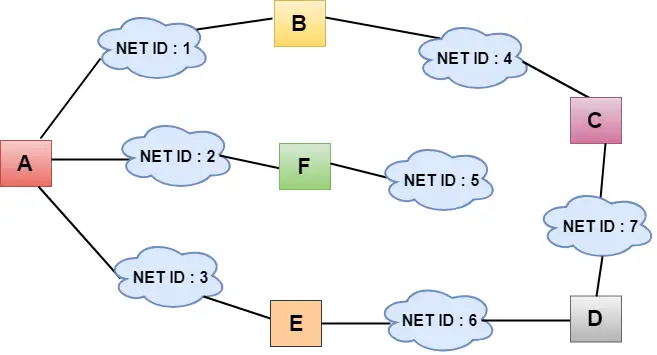
- 위 그림에서 각 구름은 네트워크를 나타내고, 구름 안의 숫자는 네트워크 ID를 나타냅니다.
- 모든 LAN은 라우터로 연결되며 A, B, C, D, E, F로 표시된 상자에 표시됩니다.
- 거리 벡터 라우팅 알고리즘은 모든 링크의 비용을 1단위로 가정하여 라우팅 프로세스를 단순화합니다. 따라서 전송 효율은 목적지에 도달하기까지의 링크 수로 측정할 수 있습니다.
- 거리 벡터 라우팅에서 비용은 홉 수를 기준으로 합니다.

위 그림에서 우리는 라우터가 바로 이웃에게 지식을 보내는 것을 관찰합니다. 이웃은 이 지식을 자신의 지식에 추가하고 업데이트된 테이블을 자신의 이웃에게 보냅니다. 이러한 방식으로 라우터는 자체 정보와 이웃에 대한 새로운 정보를 얻습니다.
라우팅 테이블
두 가지 프로세스가 발생합니다.
- 테이블 만들기
- 테이블 업데이트
테이블 만들기
처음에는 네트워크 ID, 비용, 다음 홉 등 최소한 세 가지 유형의 정보를 포함하는 각 라우터에 대해 라우팅 테이블이 생성됩니다.


- 위 그림에서는 모든 라우터의 원래 라우팅 테이블이 표시됩니다. 라우팅 테이블에서 첫 번째 열은 네트워크 ID를 나타내고, 두 번째 열은 링크 비용을 나타내며, 세 번째 열은 비어 있습니다.
- 이 라우팅 테이블은 모든 이웃에게 전송됩니다.
예를 들어:
A sends its routing table to B, F & E. B sends its routing table to A & C. C sends its routing table to B & D. D sends its routing table to E & C. E sends its routing table to A & D. F sends its routing table to A.
테이블 업데이트
- A는 B로부터 라우팅 테이블을 받으면 해당 정보를 사용하여 테이블을 업데이트합니다.
- B의 라우팅 테이블은 패킷이 네트워크 1과 네트워크 4로 어떻게 이동할 수 있는지 보여줍니다.
- B는 A 라우터의 이웃이며 A에서 B로의 패킷은 한 홉에 도달할 수 있습니다. 따라서 B의 표에 제공된 모든 비용에 1이 추가되고 그 합계는 특정 네트워크에 도달하는 데 드는 비용이 됩니다.

- 조정 후 A는 이 테이블을 자신의 테이블과 결합하여 결합된 테이블을 만듭니다.

- 결합된 테이블에는 중복된 데이터가 일부 포함되어 있을 수 있습니다. 위 그림에서 라우터 A의 결합 테이블에는 중복된 데이터가 포함되어 있으므로 비용이 가장 낮은 데이터만 유지합니다. 예를 들어 A는 두 가지 방법으로 네트워크 1에 데이터를 보낼 수 있습니다. 첫 번째는 다음 라우터를 사용하지 않으므로 1홉 비용이 듭니다. 두 번째에는 두 개의 홉(A에서 B로, B에서 네트워크 1로)이 필요합니다. 첫 번째 옵션의 비용이 가장 낮으므로 유지되고 두 번째 옵션은 삭제됩니다.

- 라우팅 테이블 생성 프로세스는 모든 라우터에 대해 계속됩니다. 모든 라우터는 이웃으로부터 정보를 수신하고 라우팅 테이블을 업데이트합니다.
모든 라우터의 최종 라우팅 테이블은 다음과 같습니다.
