분할 정복(Divide and Conquer)은 알고리즘 패턴입니다. 알고리즘 방법에서 설계는 대규모 입력에 대해 논쟁을 벌이고 입력을 작은 조각으로 나누고 각 작은 조각에 대한 문제를 결정한 다음 조각별 솔루션을 글로벌 솔루션으로 병합하는 것입니다. 이러한 문제 해결 메커니즘을 분할 정복 전략이라고 합니다.
분할 정복 알고리즘은 다음 세 단계를 사용하는 분쟁으로 구성됩니다.
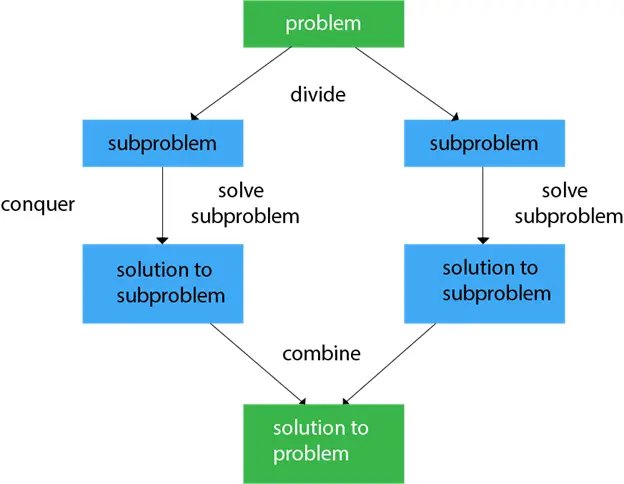
일반적으로 우리는 다음을 따를 수 있습니다. 분할 정복 3단계 과정으로 접근합니다.
예: 특정 컴퓨터 알고리즘은 Divide & Conquer 접근 방식을 기반으로 합니다.
- 최대 및 최소 문제
- 이진 검색
- 정렬(병합 정렬, 퀵 정렬)
- 하노이 타워.
분할 정복 전략의 기본:
분할 정복 전략에는 두 가지 기본 원칙이 있습니다.
- 관계식
- 정지상태
1. 관계식: 이것은 주어진 기술로부터 우리가 생성한 공식입니다. 공식을 생성한 후 D&C 전략을 적용합니다. 즉, 문제를 재귀적으로 분해하고 깨진 하위 문제를 해결합니다.
2. 정지 조건: Divide & Conquer 전략을 사용하여 문제를 해결할 때, 얼마만큼의 시간 동안 Divide & Conquer를 적용해야 하는지 알아야 합니다. 따라서 D&C의 재귀 단계를 중지해야 하는 조건을 중지 조건이라고 합니다.
분할 정복 접근법의 적용:
다음 알고리즘은 분할 및 정복 기법의 개념을 기반으로 합니다.
분할 정복의 장점
- Divide and Conquer는 수학 퍼즐인 하노이 탑과 같은 가장 큰 문제 중 하나를 성공적으로 해결하는 경향이 있습니다. 기본적인 아이디어가 없는 복잡한 문제를 해결하는 것은 어려운 일이지만, 분할 정복 접근 방식을 사용하면 주요 문제를 두 부분으로 나눈 다음 재귀적으로 해결하므로 노력이 줄어듭니다. 이 알고리즘은 다른 알고리즘보다 훨씬 빠릅니다.
- 속도가 느린 메인 메모리에 액세스하는 대신 캐시 메모리 내의 간단한 하위 문제를 해결하기 때문에 많은 공간을 차지하지 않고 캐시 메모리를 효율적으로 사용합니다.
- 이는 상대 Brute Force 기술보다 더 능숙합니다.
- 이러한 알고리즘은 병렬성을 금지하므로 수정이 필요하지 않으며 병렬 처리 기능이 통합된 시스템에서 처리됩니다.
분할 정복의 단점
- 대부분의 알고리즘은 재귀를 통합하여 설계되었으므로 높은 메모리 관리가 필요합니다.
- 명시적 스택은 공간을 과도하게 사용할 수 있습니다.
- CPU에 있는 스택보다 엄격하게 재귀가 수행되면 시스템이 충돌할 수도 있습니다.