분산이란 무엇입니까?
분산은 데이터 세트의 확산 또는 분산을 설명하는 데 사용되는 통계적 측정입니다. 세트의 각 데이터 포인트가 세트의 평균(평균)에서 벗어나는 평균 양을 측정합니다. 분산은 각 데이터 포인트 간의 스쿼드 차이의 합과 평균을 데이터 포인트 수로 나누어 계산됩니다. 분산 값이 클수록 데이터가 더 많이 분산되어 있음을 나타내고, 분산이 작을수록 데이터 세트가 더 작거나 촘촘하게 클러스터되어 있음을 나타냅니다. 분산은 특히 금융, 경제, 엔지니어링 등 다양한 분야에서 데이터 세트의 변동성을 설명하고 분석하는 데 사용됩니다.
Excel의 차이
Microsoft Excel에서 분산은 데이터 세트의 개별 숫자가 세트의 평균(평균)에서 벗어나는 평균 양을 계산하는 통계 측정입니다. 단일 숫자로 표현되며 데이터의 분산이나 퍼짐을 측정하는 데 사용됩니다. 분산은 VAR.S 또는 VAR.P 함수를 사용하여 Excel에서 계산할 수 있습니다.
Excel에서 분산을 계산하는 이유는 무엇입니까?
Excel에서 분산을 계산하면 다음과 같은 이점이 있습니다.
향상된 데이터 분석 - 분산은 데이터 분석에 중요한 데이터 분산을 이해하는 데 도움이 됩니다.
더 나은 의사 결정 - 분산은 이상값을 식별하고 데이터 포인트가 평균과 크게 다른지 확인하는 데 도움이 되며, 이를 통해 더 나은 의사 결정을 내릴 수 있습니다.
사용 용이성 - Excel은 대규모 데이터 세트의 분산을 쉽게 계산할 수 있는 VAR 및 STDEV와 같은 기본 제공 기능을 제공합니다.
향상된 정확도 - Excel의 분산 계산을 자동화하면 수동 계산 오류의 위험이 줄어들어 정확도가 향상됩니다.
시간 절약 - Excel에서 분산을 계산하면 특히 대규모 데이터 세트의 경우 수동 계산에 비해 시간과 노력이 절약됩니다.
분산 함수의 조건
Excel의 분산 함수의 경우 다음 조건을 따릅니다.
데이터 세트: 이 함수에는 셀 범위 또는 배열의 숫자 데이터 세트가 필요합니다.
데이터 개수: 단일 값의 분산은 정의되지 않으므로 데이터 세트에는 최소 두 개의 값이 포함되어야 합니다.
자바스크립트 튜토리얼
데이터 유형: 데이터 세트의 값은 숫자여야 합니다. 텍스트 또는 빈 셀과 같은 숫자가 아닌 값은 오류를 발생시킵니다.
계산 방법: Excel에서 분산을 계산하는 방법에는 VAR.S와 VAR.P의 두 가지 방법이 있으며, VAR.S는 표본 분산을 계산하고 VAR.P는 모집단 분산을 계산합니다.
분산의 예
Variance의 간단한 예는 다음과 같습니다.
주어진 데이터 세트 5, 6, 7,8,10에 대한 분산을 찾습니다.
1단계: 분산을 계산하려면 평균값을 계산해야 합니다. 따라서,
5+5+7+8+10/5=7. 평균값은 7입니다.
2단계: 각 값과 평균의 차이를 계산하고 그 차이의 제곱을 구해야 합니다.
(5-7)^ 2=4
(5-7)^ 2=4
(7-7)^2=0
(8-7)^2=1
(10-7)^2=9
3단계: 제곱값에 대한 평균은 다음과 같이 계산됩니다.
4+4+0+1+9/5= 3.6
따라서 숫자 집합의 분산은 3.6이며, 이는 개별 숫자가 평균에서 평균 3.6 단위 벗어남을 나타냅니다. 0 값은 변동성이 없음을 나타냅니다. 분산 값은 데이터 분산에 대한 일반적인 아이디어를 제공합니다.
Excel에서 차이를 계산하는 방법은 무엇입니까?
Excel에서는 분산을 계산하기 위해 6가지 기본 함수를 제공합니다. 기본 기능은 다음과 같습니다.
자바 문자열 형식화
- 였다
- 누구
- 마지막
- 경사
- BE
- 던지다
사용자는 다음과 같은 여러 요소를 기반으로 원하는 공식을 선택할 수 있습니다.
- 엑셀 버전
- 표본 버전을 계산할지 모집단 버전을 계산할지 여부
- 텍스트와 논리값을 평가하거나 무시하려면<
Excel 분산 함수
Excel Variance 함수는 아래와 같이 차별화되어 있으며 요구 사항에 따라 수식을 선택하기 쉽습니다.
| 이름 | 엑셀 버전 | 데이터 형식 | 텍스트 및 논리 |
| 였다 | 2000-2019 | 견본 | 무시됨 |
| 누구 | 2010-2019 | 견본 | 무시됨 |
| BE | 2000-2019 | 견본 | 평가됨 |
| 마지막 | 2000-2019 | 인구 | 무시됨 |
| 경사 | 2010-2019 | 인구 | 무시됨 |
| 던지다 | 2000-2019 | 인구 | 평가됨 |
VARA 및 VARPA는 참조의 논리값과 텍스트 값을 처리한다는 점에서 다른 분산 함수와 다릅니다. 다음은 숫자와 논리값의 텍스트 표현에 관한 표입니다.
| 인수 유형 | 어디서, 어디서.S, 어디서, 어디서.P | 스페어&토 |
| 배열 및 참조 내의 논리값 | 무시됨 | 평가됨(TRUE=1,FALSE=0) |
| 배열 및 참조 내 숫자의 텍스트 표현 | 무시됨 | 0으로 평가됨 |
| 인수에 직접 입력된 숫자의 논리값 및 텍스트 표현 | 평가됨(TRUE=1,FALSE=0) | 평가됨(TRUE=1,FALSE=0) |
| 빈 셀 | 무시됨 | 무시됨 |
표본분산이란 무엇인가?
Excel의 표본 분산은 =VAR.S(값 범위) 공식을 사용하여 계산됩니다. 'VAR.S' 함수는 표본을 기반으로 한 모집단의 변동성의 추정치인 값 집합의 표본 분산을 계산합니다. 표본 분산은 표본의 각 값과 표본 평균 간의 차이 제곱을 더한 후 (n-1)로 나눈 후 제곱근을 취하여 계산됩니다.
Excel에서 표본 차이를 계산하는 방법은 무엇입니까?
앞서 언급했듯이 분산 함수는 다음과 같은 유형으로 분류됩니다.
표본 분산의 경우 VAR, VAR.S 또는 VARA
모집단 분산을 위한 VARP, VAR.P 또는 VARPA
이들 함수 중 VAR 및 VARP 함수는 VAR.S 및 VAR.P로 대체됩니다. VAR, VARP, VAR.S 및 VAR.P는 수치 데이터를 계산하는 데 사용됩니다.
예시 1: 주어진 데이터에 대한 표본 분산을 계산합니다.
여기에는 다양한 학생들의 점수가 주어집니다. 마크는 숫자, 텍스트 및 TRUE, FALSE, 0, 1과 같은 논리값을 결합합니다. 데이터 조합에 대한 분산을 계산하기 위해 VARA 및 VARPA 함수가 사용됩니다.
표본 분산을 계산하기 위해 따라야 할 단계는 다음과 같습니다.
1단계: 워크시트에 A1:C12라는 데이터를 입력합니다.
2단계: C1:C15의 셀 범위에 있는 데이터의 분산을 계산하려면 사용자가 결과를 표시하려는 새 셀을 선택합니다.
마크다운에 밑줄
3단계: 여기서는 D1 셀을 선택하고 수식을 =VAR.S (C2:C9)로 입력합니다.
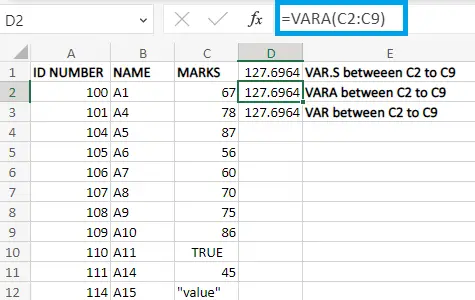
VAR.S, VARA 및 VAR 함수는 D1, D2 및 D3 셀의 값을 표시합니다.
인구 분산이란 무엇입니까?
Excel의 모집단 분산은 모집단 내 분산된 데이터의 통계적 측정을 나타냅니다. 이는 각 데이터 포인트와 모집단 평균 사이의 평균 제곱 차이를 취하여 계산됩니다. 엑셀에서 모집단 분산을 계산하는 수식은 'VAR.P(배열)'인데, 여기서 '배열'은 데이터의 범위를 의미한다.
Excel에서 인구 분산을 계산하는 방법은 무엇입니까?
모집단 분산을 계산하기 위해 따라야 할 단계는 다음과 같습니다.
1단계: 워크시트에 A1:C12라는 데이터를 입력합니다.
2단계: 사용자가 결과를 표시하려는 새 셀 D3을 선택합니다.
3단계: 모집단 분산을 계산하기 위해 사용되는 함수는 VARP, VAR.P 및 VARPA입니다.

VARP, VAR.P 및 VARPA라는 함수는 모집단 분산을 계산하는 데 사용됩니다. 워크시트에서 텍스트와 논리 문자열이 동등한 숫자 값으로 변환됩니다. 텍스트 문자열은 0 또는 FALSE로 변환되고, 논리값은 0이 FALSE이고 하나가 TRUE인 수치로 변환됩니다.
요약
결론적으로, 분산은 평균으로부터 데이터 분산을 나타내는 통계적 척도입니다. Microsoft Excel에서는 VAR 또는 VAR.S와 같은 내장 함수를 사용하여 쉽게 분산을 계산할 수 있습니다. VAR.S 함수는 표본 분산을 계산하고, VAR 함수는 모집단 분산을 계산합니다. 두 함수 모두 다양한 데이터를 입력으로 사용하고 결과로 Variance를 반환합니다. 분산을 이해하고 사용하면 데이터를 기반으로 현명한 결정을 내리는 데 도움이 되며 Excel에서는 쉽게 계산할 수 있습니다.