ㅏ 해시 테이블 데이터를 빠르게 삽입, 삭제, 검색할 수 있는 데이터 구조입니다. 해시 함수를 사용하여 키를 배열의 인덱스에 매핑하는 방식으로 작동합니다. 이 기사에서는 충돌을 처리하기 위해 별도의 연결을 사용하여 Python에서 해시 테이블을 구현합니다.
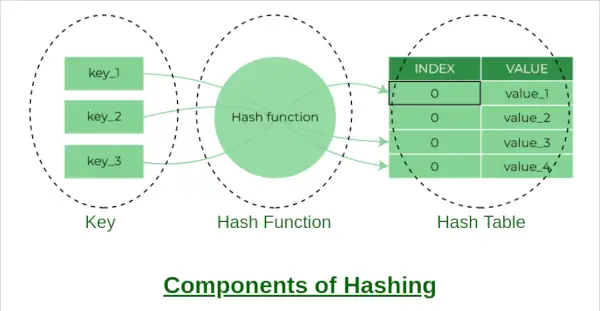
해싱의 구성요소
배열로 나열
별도의 연결은 해시 테이블의 충돌을 처리하는 데 사용되는 기술입니다. 두 개 이상의 키가 배열의 동일한 인덱스에 매핑되면 해당 인덱스의 연결된 목록에 키를 저장합니다. 이를 통해 동일한 인덱스에 여러 값을 저장하고 해당 키를 사용하여 해당 값을 검색할 수 있습니다.
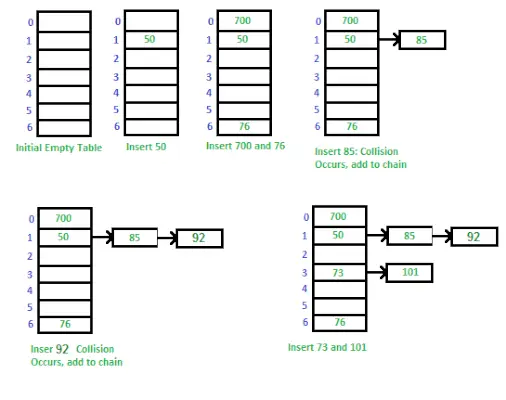
Separate Chaining을 이용한 Hash Table 구현 방법
별도의 연결을 사용하여 해시 테이블을 구현하는 방법:
두 개의 클래스를 생성합니다: ' 마디 ' 그리고 ' 해시테이블 '.
' 마디 ' 클래스는 연결리스트의 노드를 나타냅니다. 각 노드에는 키-값 쌍과 목록의 다음 노드에 대한 포인터가 포함됩니다.
파이썬3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> |
>
>
'HashTable' 클래스에는 연결된 목록을 보관할 배열과 해시 테이블에서 데이터를 삽입, 검색 및 삭제하는 메서드가 포함됩니다.
파이썬3
class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> |
>
>
' __더운__ ' 메소드는 주어진 용량으로 해시 테이블을 초기화합니다. '를 설정합니다. 용량 ' 그리고 ' 크기 ' 변수를 사용하고 배열을 'None'으로 초기화합니다.
다음 방법은 ' _해시시 ' 방법. 이 메서드는 키를 가져와서 키-값 쌍이 저장되어야 하는 배열의 인덱스를 반환합니다. Python에 내장된 해시 함수를 사용하여 키를 해시한 다음 모듈로 연산자를 사용하여 배열의 인덱스를 가져옵니다.
파이썬3
def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> |
>
>
그만큼 '끼워 넣다' 메소드는 해시 테이블에 키-값 쌍을 삽입합니다. '를 사용하여 쌍을 저장해야 하는 인덱스를 가져옵니다. _해시시 ' 방법. 해당 인덱스에 연결된 목록이 없으면 키-값 쌍으로 새 노드를 만들고 이를 목록의 헤드로 설정합니다. 해당 인덱스에 연결된 목록이 있는 경우 마지막 노드를 찾거나 키가 이미 존재할 때까지 목록을 반복하고 키가 이미 있으면 값을 업데이트합니다. 키를 찾으면 값을 업데이트합니다. 키를 찾지 못하면 새 노드를 생성하여 목록의 헤드에 추가합니다.
파이썬3
Java에서 while 루프를 수행하십시오.
def> insert(>self>, key, value):> >index>=> self>._hash(key)> >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> |
>
>
그만큼 찾다 메소드는 주어진 키와 연관된 값을 검색합니다. 먼저 다음을 사용하여 키-값 쌍이 저장되어야 하는 인덱스를 가져옵니다. _해시시 방법. 그런 다음 해당 인덱스에서 연결된 목록에서 키를 검색합니다. 키를 찾으면 관련 값을 반환합니다. 키를 찾지 못하면 키 오류 .
파이썬3
def> search(>self>, key):> >index>=> self>._hash(key)> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> >raise> KeyError(key)> |
>
>
그만큼 '제거하다' 메소드는 해시 테이블에서 키-값 쌍을 제거합니다. 먼저 `를 사용하여 쌍을 저장해야 하는 인덱스를 가져옵니다. _해시시 `` 방법. 그런 다음 해당 인덱스에서 연결된 목록에서 키를 검색합니다. 키를 찾으면 목록에서 해당 노드를 제거합니다. 키를 찾지 못하면 ` 키 오류 `.
파이썬3
def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> |
>
>
'__str__' 해시 테이블의 문자열 표현을 반환하는 메서드입니다.
파이썬3
def> __str__(>self>):> >elements>=> []> >for> i>in> range>(>self>.capacity):> >current>=> self>.table[i]> >while> current:> >elements.append((current.key, current.value))> >current>=> current.>next> >return> str>(elements)> |
>
>
다음은 'HashTable' 클래스의 전체 구현입니다.
수학 펑 자바
파이썬3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> > > class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> > >def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> > >def> insert(>self>, key, value):> >index>=> self>._hash(key)> > >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> > >def> search(>self>, key):> >index>=> self>._hash(key)> > >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> > >raise> KeyError(key)> > >def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> > >def> __len__(>self>):> >return> self>.size> > >def> __contains__(>self>, key):> >try>:> >self>.search(key)> >return> True> >except> KeyError:> >return> False> > > # Driver code> if> __name__>=>=> '__main__'>:> > ># Create a hash table with> ># a capacity of 5> >ht>=> HashTable(>5>)> > ># Add some key-value pairs> ># to the hash table> >ht.insert(>'apple'>,>3>)> >ht.insert(>'banana'>,>2>)> >ht.insert(>'cherry'>,>5>)> > ># Check if the hash table> ># contains a key> >print>(>'apple'> in> ht)># True> >print>(>'durian'> in> ht)># False> > ># Get the value for a key> >print>(ht.search(>'banana'>))># 2> > ># Update the value for a key> >ht.insert(>'banana'>,>4>)> >print>(ht.search(>'banana'>))># 4> > >ht.remove(>'apple'>)> ># Check the size of the hash table> >print>(>len>(ht))># 3> |
>
>산출
True False 2 4 3>
시간 복잡도와 공간 복잡도:
- 그만큼 시간 복잡도 ~의 끼워 넣다 , 찾다 그리고 제거하다 별도의 체인을 사용하는 해시 테이블의 메서드는 해시 테이블의 크기, 해시 테이블의 키-값 쌍 수 및 각 인덱스의 연결 목록 길이에 따라 달라집니다.
- 좋은 해시 함수와 균일한 키 분포를 가정하면 이러한 방법의 예상 시간 복잡도는 다음과 같습니다. 오(1) 각 작업마다. 그러나 최악의 경우에는 시간복잡도가 커질 수 있다. 에) , 여기서 n은 해시 테이블의 키-값 쌍 수입니다.
- 그러나 충돌 가능성을 최소화하고 좋은 성능을 보장하려면 좋은 해시 함수와 해시 테이블의 적절한 크기를 선택하는 것이 중요합니다.
- 그만큼 공간 복잡도 별도의 체인을 사용하는 해시 테이블의 구성은 해시 테이블의 크기와 해시 테이블에 저장된 키-값 쌍의 수에 따라 달라집니다.
- 해시 테이블 자체는 오(m) 여기서 m은 해시 테이블의 용량입니다. 각 연결리스트 노드는 오(1) 공간, 연결된 목록에는 최대 n개의 노드가 있을 수 있습니다. 여기서 n은 해시 테이블에 저장된 키-값 쌍의 수입니다.
- 따라서 전체 공간 복잡도는 O(m + n) .
결론:
실제로는 공간 사용량과 충돌 가능성의 균형을 맞추기 위해 해시 테이블에 적절한 용량을 선택하는 것이 중요합니다. 용량이 너무 작으면 충돌 가능성이 높아져 성능 저하가 발생할 수 있습니다. 반면, 용량이 너무 크면 해시 테이블이 필요 이상으로 많은 메모리를 소비할 수 있습니다.