ㅏ CNN(컨벌루션 신경망) 컴퓨터 비전에서 일반적으로 사용되는 딥러닝 신경망 아키텍처의 한 유형입니다. 컴퓨터 비전은 컴퓨터가 이미지나 시각적 데이터를 이해하고 해석할 수 있도록 하는 인공 지능 분야입니다.
머신러닝의 경우, 인공 신경망 정말 잘한다. 신경망은 이미지, 오디오, 텍스트와 같은 다양한 데이터세트에 사용됩니다. 다양한 유형의 신경망은 우리가 사용하는 단어의 순서를 예측하는 등 다양한 목적으로 사용됩니다. 순환 신경망 더 정확하게는 LSTM , 유사하게 이미지 분류를 위해 Convolution Neural Network를 사용합니다. 이 블로그에서는 CNN의 기본 빌딩 블록을 구축하겠습니다.
일반 신경망에는 세 가지 유형의 레이어가 있습니다.
- 입력 레이어: 이는 모델에 입력을 제공하는 레이어입니다. 이 레이어의 뉴런 수는 데이터의 전체 특징 수(이미지의 경우 픽셀 수)와 같습니다.
- 숨겨진 레이어: 그런 다음 입력 레이어의 입력이 숨겨진 레이어로 공급됩니다. 모델과 데이터 크기에 따라 숨겨진 레이어가 많이 있을 수 있습니다. 각 은닉층에는 일반적으로 특징 수보다 더 많은 다양한 수의 뉴런이 있을 수 있습니다. 각 계층의 출력은 이전 계층의 출력과 해당 계층의 학습 가능한 가중치를 행렬로 곱한 다음 학습 가능한 편향과 네트워크를 비선형으로 만드는 활성화 함수를 추가하여 계산됩니다.
- 출력 레이어: 그런 다음 숨겨진 레이어의 출력은 각 클래스의 출력을 각 클래스의 확률 점수로 변환하는 시그모이드 또는 소프트맥스와 같은 로지스틱 함수에 공급됩니다.
데이터는 모델에 입력되고 각 레이어의 출력은 위 단계에서 얻어집니다. 피드포워드 그런 다음 오류 함수를 사용하여 오류를 계산합니다. 일반적인 오류 함수로는 교차 엔트로피, 제곱 손실 오류 등이 있습니다. 오류 함수는 네트워크가 얼마나 잘 수행되는지 측정합니다. 그 후, 도함수를 계산하여 모델로 역전파합니다. 이 단계를 CNN(Convolutional Neural Network)은 CNN의 확장 버전입니다. 인공 신경망(ANN) 이는 주로 그리드형 행렬 데이터세트에서 기능을 추출하는 데 사용됩니다. 예를 들어 데이터 패턴이 광범위한 역할을 하는 이미지나 비디오와 같은 시각적 데이터 세트입니다.
CNN 아키텍처
Convolutional Neural Network는 입력 레이어, Convolutional 레이어, Pooling 레이어 및 완전 연결 레이어와 같은 여러 레이어로 구성됩니다.

간단한 CNN 아키텍처
컨벌루션 계층은 입력 이미지에 필터를 적용하여 특징을 추출하고, 풀링 계층은 이미지를 다운샘플링하여 계산을 줄이며, 완전 연결 계층은 최종 예측을 수행합니다. 네트워크는 역전파와 경사하강법을 통해 최적의 필터를 학습합니다.
컨볼루셔널 레이어의 작동 방식
컨볼루션 신경망(Covnet)은 매개변수를 공유하는 신경망입니다. 이미지가 있다고 상상해보세요. 길이, 너비(이미지의 크기) 및 높이(즉, 이미지의 채널은 일반적으로 빨간색, 녹색 및 파란색 채널을 가짐)를 갖는 직육면체로 표현될 수 있습니다.
이제 이 이미지의 작은 패치를 가져와 그 위에 필터 또는 커널이라고 하는 작은 신경망을 실행하고 K 출력을 수직으로 표시한다고 상상해 보세요. 이제 전체 이미지에 걸쳐 신경망을 슬라이드하면 너비, 높이, 깊이가 다른 또 다른 이미지를 얻을 수 있습니다. 이제 R, G, B 채널 대신 더 많은 채널이 있지만 너비와 높이는 더 작아졌습니다. 이 작업을 회선 . 패치 크기가 이미지의 크기와 동일하면 일반 신경망이 됩니다. 이 작은 패치로 인해 가중치가 더 적습니다.
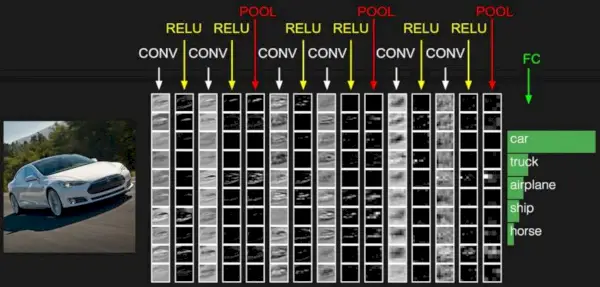
이미지 출처: Deep Learning Udacity
이제 전체 컨볼루션 프로세스와 관련된 약간의 수학에 대해 이야기해 보겠습니다.
자바 문자열을 정수로
- 컨볼루션 레이어는 너비와 높이가 작고 입력 볼륨과 동일한 깊이(입력 레이어가 이미지 입력인 경우 3)를 갖는 학습 가능한 필터(또는 커널) 세트로 구성됩니다.
- 예를 들어, 34x34x3 크기의 이미지에서 컨볼루션을 실행해야 한다고 가정해 보겠습니다. 가능한 필터 크기는 axax3일 수 있습니다. 여기서 'a'는 3, 5, 7과 같을 수 있지만 이미지 크기에 비해 작습니다.
- 순방향 패스 동안 우리는 각 단계가 호출되는 전체 입력 볼륨에 걸쳐 각 필터를 단계별로 밀어 넣습니다. 보폭 (고차원 이미지의 경우 2, 3 또는 4의 값을 가질 수 있음) 커널 가중치와 입력 볼륨의 패치 사이의 내적을 계산합니다.
- 필터를 슬라이드하면 각 필터에 대한 2D 출력을 얻을 수 있고 결과적으로 필터를 쌓을 수 있으며 필터 수와 동일한 깊이를 갖는 출력 볼륨을 얻을 수 있습니다. 네트워크는 모든 필터를 학습합니다.
ConvNet을 구축하는 데 사용되는 레이어
완전한 Convolution Neural Networks 아키텍처는 covnet이라고도 합니다. 코브넷은 일련의 레이어이며, 모든 레이어는 미분 가능한 함수를 통해 한 볼륨을 다른 볼륨으로 변환합니다.
레이어 유형: 데이터세트
32 x 32 x 3 크기의 이미지에 대해 covnet을 실행하는 예를 들어보겠습니다.
- 입력 레이어: 이는 모델에 입력을 제공하는 레이어입니다. CNN에서는 일반적으로 입력은 이미지 또는 이미지 시퀀스입니다. 이 레이어는 너비가 32, 높이가 32, 깊이가 3인 이미지의 원시 입력을 보유합니다.
- 컨벌루션 레이어: 입력 데이터 세트에서 기능을 추출하는 데 사용되는 레이어입니다. 커널이라고 알려진 학습 가능한 필터 세트를 입력 이미지에 적용합니다. 필터/커널은 일반적으로 2×2, 3×3 또는 5×5 모양의 더 작은 행렬입니다. 입력 이미지 데이터 위로 이동하여 커널 가중치와 해당 입력 이미지 패치 사이의 내적을 계산합니다. 이 레이어의 출력을 특징 맵이라고 합니다. 이 레이어에 총 12개의 필터를 사용한다고 가정하면 32 x 32 x 12 차원의 출력 볼륨을 얻게 됩니다.
- 활성화 레이어: 이전 계층의 출력에 활성화 함수를 추가함으로써 활성화 계층은 네트워크에 비선형성을 추가합니다. 컨볼루션 레이어의 출력에 요소별 활성화 함수를 적용합니다. 몇 가지 일반적인 활성화 함수는 다음과 같습니다. 재개하다 : 최대(0, x), 수상한 , 누출 RELU 등. 볼륨은 변경되지 않고 유지되므로 출력 볼륨의 크기는 32 x 32 x 12입니다.
- 풀링 레이어: 이 레이어는 주기적으로 코브넷에 삽입되며 주요 기능은 볼륨 크기를 줄이는 것입니다. 이를 통해 계산 속도가 빨라지고 메모리가 줄어들며 과적합도 방지됩니다. 풀링 레이어의 두 가지 일반적인 유형은 다음과 같습니다. 최대 풀링 그리고 평균 풀링 . 2 x 2 필터와 스트라이드 2가 있는 최대 풀을 사용하면 결과 볼륨의 크기는 16x16x12가 됩니다.
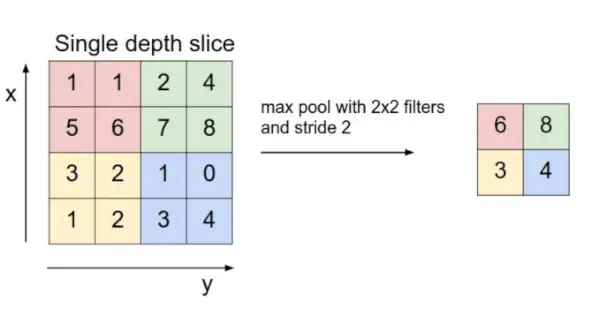
이미지 출처: cs231n.stanford.edu
- 편평화: 결과 기능 맵은 컨볼루션 및 풀링 레이어 이후 1차원 벡터로 평면화되므로 분류 또는 회귀를 위해 완전히 연결된 레이어로 전달될 수 있습니다.
- 완전히 연결된 레이어: 이전 레이어에서 입력을 가져와 최종 분류 또는 회귀 작업을 계산합니다.
이미지 출처: cs231n.stanford.edu
- 출력 레이어: 그런 다음 완전히 연결된 레이어의 출력은 각 클래스의 출력을 각 클래스의 확률 점수로 변환하는 Sigmoid 또는 Softmax와 같은 분류 작업을 위한 로지스틱 함수에 공급됩니다.
예:
이미지를 생각하고 컨볼루션 레이어, 활성화 레이어, 풀링 레이어 연산을 적용하여 내부 특징을 추출해 보겠습니다.
입력 이미지:
입력 이미지
단계:
- 필요한 라이브러리를 가져옵니다
- 매개변수를 설정하다
- 커널 정의
- 이미지를 로드하고 플롯합니다.
- 이미지 다시 포맷하기
- 컨볼루션 계층 작업을 적용하고 출력 이미지를 플로팅합니다.
- 활성화 계층 작업을 적용하고 출력 이미지를 플로팅합니다.
- 풀링 계층 작업을 적용하고 출력 이미지를 플로팅합니다.
파이썬3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
CSS 굵은 텍스트
>
산출 :

원본 회색조 이미지
산출
CNN(컨볼루션 신경망)의 장점:
- 이미지, 비디오, 오디오 신호의 패턴과 특징을 감지하는 데 능숙합니다.
- 변환, 회전 및 크기 조정 불변성에 강력합니다.
- 엔드 투 엔드 교육으로 수동 특징 추출이 필요하지 않습니다.
- 대량의 데이터를 처리하고 높은 정확도를 달성할 수 있습니다.
CNN(컨볼루셔널 신경망)의 단점:
- 훈련하는 데 계산 비용이 많이 들고 많은 메모리가 필요합니다.
- 데이터가 충분하지 않거나 적절한 정규화가 사용되지 않으면 과적합이 발생할 수 있습니다.
- 대량의 레이블이 지정된 데이터가 필요합니다.
- 해석 가능성이 제한되어 있어 네트워크가 학습한 내용을 이해하기 어렵습니다.
자주 묻는 질문(FAQ)
1: CNN(컨벌루션 신경망)이란 무엇입니까?
CNN(Convolutional Neural Network)은 이미지 및 비디오 분석에 적합한 딥러닝 신경망의 한 유형입니다. CNN은 일련의 컨볼루션 및 풀링 레이어를 사용하여 이미지와 비디오에서 특징을 추출한 다음 이러한 특징을 사용하여 객체나 장면을 분류하거나 감지합니다.
2: CNN은 어떻게 작동하나요?
CNN은 입력 이미지나 비디오에 일련의 컨볼루션 및 풀링 레이어를 적용하는 방식으로 작동합니다. 컨볼루션 레이어는 이미지나 비디오 위에 작은 필터 또는 커널을 삽입하고 필터와 입력 사이의 내적을 계산하여 입력에서 특징을 추출합니다. 그런 다음 풀링 레이어는 컨볼루션 레이어의 출력을 다운샘플링하여 데이터의 차원을 줄이고 계산 효율성을 높입니다.
3: CNN에서 사용되는 일반적인 활성화 함수는 무엇입니까?
CNN에서 사용되는 몇 가지 일반적인 활성화 기능은 다음과 같습니다.
- ReLU(Rectified Linear Unit): ReLU는 계산적으로 효율적이고 훈련하기 쉬운 비포화 활성화 함수입니다.
- Leaky Rectified Linear Unit(Leaky ReLU): Leaky ReLU는 네트워크를 통해 소량의 음의 기울기가 흐르도록 허용하는 ReLU의 변형입니다. 이는 훈련 중에 네트워크가 죽는 것을 방지하는 데 도움이 될 수 있습니다.
- PReLU(Parametric Rectified Linear Unit): PReLU는 음의 기울기의 기울기를 학습할 수 있는 Leaky ReLU의 일반화입니다.
4: CNN에서 다중 컨볼루션 레이어를 사용하는 목적은 무엇입니까?
CNN에서 여러 컨볼루션 레이어를 사용하면 네트워크가 입력 이미지나 비디오에서 점점 더 복잡한 기능을 학습할 수 있습니다. 첫 번째 컨볼루션 레이어는 가장자리와 모서리와 같은 간단한 기능을 학습합니다. 더 깊은 컨볼루션 레이어는 모양 및 개체와 같은 더 복잡한 기능을 학습합니다.
5: CNN에서 사용되는 일반적인 정규화 기술은 무엇입니까?
정규화 기술은 CNN이 훈련 데이터에 과적합되는 것을 방지하는 데 사용됩니다. CNN에 사용되는 몇 가지 일반적인 정규화 기술은 다음과 같습니다.
- 드롭아웃(Dropout): 드롭아웃은 훈련 중에 네트워크에서 뉴런을 무작위로 제거합니다. 이로 인해 네트워크는 단일 뉴런에 의존하지 않는 보다 강력한 기능을 학습하게 됩니다.
- L1 정규화: L1 정규화는 정규화합니다. 네트워크에 있는 가중치의 절대값입니다. 이는 가중치 수를 줄이고 네트워크를 보다 효율적으로 만드는 데 도움이 될 수 있습니다.
- L2 정규화: L2 정규화는 정규화합니다. 네트워크 가중치의 제곱입니다. 이는 또한 가중치 수를 줄이고 네트워크를 보다 효율적으로 만드는 데 도움이 될 수 있습니다.
6: 컨볼루션 레이어와 풀링 레이어의 차이점은 무엇인가요?
컨볼루션 계층은 입력 이미지나 비디오에서 특징을 추출하는 반면 풀링 계층은 컨볼루션 계층의 출력을 다운샘플링합니다. 컨볼루션 레이어는 일련의 필터를 사용하여 특징을 추출하는 반면, 풀링 레이어는 최대 풀링, 평균 풀링과 같은 다양한 기술을 사용하여 데이터를 다운샘플링합니다.