이전 섹션에서는 Apache Kafka, 메시징 시스템 및 스트리밍 프로세스에 대해 간략하게 소개했습니다. 여기에서는 Kafka의 기본 개념과 역할에 대해 설명합니다.
주제
일반적으로 주제는 특정 제목이나 상호 관련된 특정 아이디어에 부여된 이름을 나타냅니다. Kafka에서 주제라는 단어는 특정 데이터 스트림을 저장하고 게시하는 데 사용되는 카테고리 또는 일반 이름을 나타냅니다. 기본적으로 Kafka의 항목은 데이터베이스의 테이블과 유사하지만 모든 제약 조건을 포함하지는 않습니다. Kafka에서는 원하는 만큼 n개의 주제를 만들 수 있습니다. 이는 사용자의 선택에 따라 이름으로 식별됩니다. 생산자는 주제에 데이터를 게시하고 소비자는 구독을 통해 주제에서 해당 데이터를 읽습니다.
파티션
주제는 주제의 파티션으로 알려진 여러 부분으로 나뉩니다. 이러한 파티션은 순서대로 구분됩니다. 데이터 콘텐츠는 주제 내의 파티션에 저장됩니다. 따라서 토픽을 생성할 때 파티션 수를 지정해야 합니다(이 수는 임의적이며 나중에 변경될 수 있음). 각 메시지는 오프셋 값으로 알려진 증분 ID를 사용하여 파티션에 저장됩니다. 순서는 오프셋 값 파티션 전체가 아닌 파티션 내에서만 보장됩니다. 파티션의 오프셋은 무한합니다.
메모:파티션에 한번 기록된 데이터는 절대 변경할 수 없습니다. 그것은 불변이다. 오프셋 값은 항상 증분 상태로 유지되며 결코 빈 공간으로 돌아가지 않습니다. 또한 데이터는 제한된 시간 동안만 파티션에 보관됩니다.
파티션이 있는 주제를 이해하기 위한 예를 살펴보겠습니다.
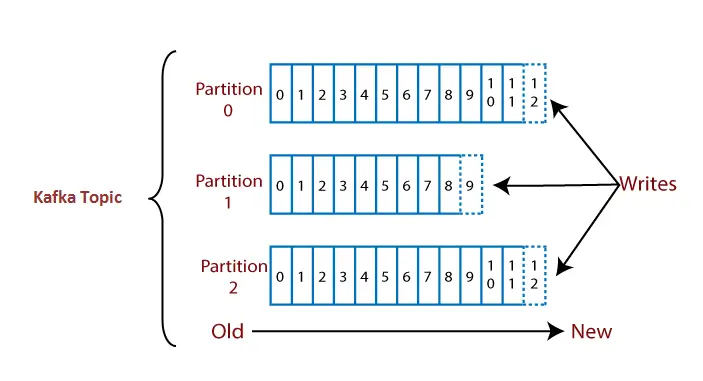
세 개의 파티션 0, 1, 2가 포함된 토픽을 가정해 보겠습니다. 각 파티션에는 서로 다른 오프셋 번호가 있습니다. 데이터는 파티션 0의 오프셋 1에 있는 데이터가 파티션 1의 오프셋 1에 있는 데이터와 아무런 관련이 없는 각 파티션의 각 오프셋에 분산됩니다. 그러나 Partition 0의 오프셋 1에 있는 데이터는 Partition0의 오프셋 2에 포함된 데이터와 상호 연관되어 있습니다.
브로커
여기에 Apache Kafka의 역할이 있습니다.
Kafka 클러스터는 브로커 또는 Kafka 브로커로 알려진 하나 이상의 서버로 구성됩니다. 브로커는 여러 파티션으로 구성된 여러 주제를 보유하는 컨테이너입니다. 클러스터의 브로커는 정수 ID로만 식별됩니다. Kafka 브로커라고도 합니다. 부트스트랩 브로커 왜냐하면 어느 하나의 브로커와의 연결은 전체 클러스터와의 연결을 의미하기 때문입니다. 브로커에는 전체 데이터가 포함되어 있지 않지만 클러스터의 각 브로커는 다른 모든 브로커, 파티션 및 주제에 대해 알고 있습니다.

이는 n개의 파티션이 있는 주제가 포함된 그림에서 브로커의 모습입니다.
예: 브로커 및 주제
Broker 1, Broker 2, Broker 3이라는 세 개의 브로커로 구성된 Kafka 클러스터를 가정해 보겠습니다.

각 브로커는 세 개의 파티션 0, 1, 2가 있는 Topic-x라는 주제를 보유하고 있습니다. 모든 파티션은 하나의 브로커에만 속하지 않고 항상 각 브로커에 분산됩니다(수량에 따라 다름). 브로커 1과 브로커 2에는 두 개의 파티션 0과 1이 있는 또 다른 topic-y가 포함되어 있습니다. 따라서 Broker 3은 Topic-y의 데이터를 보유하지 않습니다. 또한 브로커 번호와 파티션 번호 사이에는 아무런 관계도 존재하지 않는 것으로 결론지었습니다.