현실 세계에서 기계 학습 응용 프로그램에는 많은 관련 기능이 있는 것이 일반적이지만 그 중 일부만 관찰할 수 있습니다. 때로는 관찰 가능하고 때로는 그렇지 않은 변수를 다룰 때, 해당 변수가 관찰 가능하지 않은 인스턴스를 학습하고 예측하기 위해 해당 변수가 표시되거나 관찰되는 인스턴스를 활용하는 것이 실제로 가능합니다. 이 접근 방식을 종종 누락된 데이터 처리라고 합니다. 변수를 관찰할 수 있는 사용 가능한 인스턴스를 사용함으로써 기계 학습 알고리즘은 관찰된 데이터로부터 패턴과 관계를 학습할 수 있습니다. 이렇게 학습된 패턴은 변수가 없거나 관찰할 수 없는 경우 변수 값을 예측하는 데 사용될 수 있습니다.
기대값 최대화 알고리즘은 변수가 부분적으로 관찰 가능한 상황을 처리하는 데 사용할 수 있습니다. 특정 변수가 관찰 가능하면 해당 인스턴스를 사용하여 해당 값을 학습하고 추정할 수 있습니다. 그런 다음 관찰할 수 없는 경우 이러한 변수의 값을 예측할 수 있습니다.
EM 알고리즘은 Arthur Dempster, Nan Laird 및 Donald Rubin이 1977년에 발표한 세미나 논문에서 제안되고 명명되었습니다. 그들의 작업은 알고리즘을 공식화하고 통계 모델링 및 추정에 대한 유용성을 입증했습니다.
EM 알고리즘은 직접적으로 관찰할 수는 없지만 다른 관찰된 변수의 값으로부터 유추되는 변수인 잠재변수에 적용 가능합니다. 이러한 잠재 변수를 지배하는 확률 분포의 알려진 일반적인 형태를 활용함으로써 EM 알고리즘은 해당 값을 예측할 수 있습니다.
EM 알고리즘은 기계 학습 분야의 많은 비지도 클러스터링 알고리즘의 기초 역할을 합니다. 통계 모델의 로컬 최대 우도 매개변수를 찾고 데이터가 누락되거나 불완전한 경우 잠재 변수를 추론하는 프레임워크를 제공합니다.
기대 최대화(EM) 알고리즘
EM(Expectation-Maximization) 알고리즘은 다양한 비지도 학습을 결합하는 반복 최적화 방법입니다. 기계 학습 관찰되지 않은 잠재 변수를 포함하는 통계 모델에서 매개변수의 최대 우도 또는 최대 사후 추정치를 찾는 알고리즘입니다. EM 알고리즘은 잠재 변수 모델에 일반적으로 사용되며 누락된 데이터를 처리할 수 있습니다. 추정 단계(E-step)와 최대화 단계(M-step)로 구성되어 모델 적합도를 향상시키기 위한 반복 프로세스를 구성합니다.
- E 단계에서 알고리즘은 현재 매개변수 추정치를 사용하여 잠재 변수, 즉 로그 우도의 기대치를 계산합니다.
- M 단계에서는 알고리즘이 E 단계에서 얻은 기대 로그 우도를 최대화하는 매개변수를 결정하고, 해당 모델 매개변수는 추정된 잠재 변수를 기반으로 업데이트됩니다.

EM 알고리즘의 기대 최대화
이러한 단계를 반복적으로 반복함으로써 EM 알고리즘은 관찰된 데이터의 가능성을 최대화하려고 합니다. 이는 잠재 변수를 추론하는 클러스터링과 같은 비지도 학습 작업에 일반적으로 사용되며 기계 학습, 컴퓨터 비전 및 자연어 처리를 포함한 다양한 분야에 적용됩니다.
기대 최대화(EM) 알고리즘의 주요 용어
기대-최대화(EM) 알고리즘에서 가장 일반적으로 사용되는 주요 용어는 다음과 같습니다.
- 잠재 변수: 잠재 변수는 관찰 가능한 변수에 대한 영향을 통해 간접적으로만 추론할 수 있는 통계 모델에서 관찰되지 않는 변수입니다. 직접 측정할 수는 없지만 관찰 가능한 변수에 미치는 영향을 통해 감지할 수 있습니다. 가능성(Likelihood): 모델의 매개변수가 주어지면 주어진 데이터를 관찰할 확률입니다. EM 알고리즘의 목표는 우도를 최대화하는 매개변수를 찾는 것입니다. 로그 우도(Log-Likelihood): 관측된 데이터와 모델 간의 적합도를 측정하는 우도 함수의 로그입니다. EM 알고리즘은 로그 가능성을 최대화하려고 합니다. 최대 우도 추정(MLE) : MLE는 모델이 관찰된 데이터를 얼마나 잘 설명하는지 측정하는 우도 함수를 최대화하는 모수 값을 찾아 통계 모델의 모수를 추정하는 방법입니다. 사후 확률: 베이지안 추론의 맥락에서 EM 알고리즘은 최대 사후(MAP) 추정치를 추정하도록 확장될 수 있습니다. 여기서 매개변수의 사후 확률은 사전 분포 및 우도 함수를 기반으로 계산됩니다. 기대(E) 단계: EM 알고리즘의 E-단계는 관찰된 데이터와 현재 매개변수 추정값을 바탕으로 잠재 변수의 기대값 또는 사후 확률을 계산합니다. 여기에는 각 데이터 포인트에 대한 각 잠재 변수의 확률을 계산하는 작업이 포함됩니다. 최대화(M) 단계: EM 알고리즘의 M-단계는 E-단계에서 얻은 예상 로그 우도를 최대화하여 모수 추정치를 업데이트합니다. 일반적으로 수치 최적화 방법을 통해 우도 함수를 최적화하는 매개변수 값을 찾는 작업이 포함됩니다. 수렴: 수렴은 EM 알고리즘이 안정적인 솔루션에 도달한 조건을 나타냅니다. 이는 일반적으로 로그 우도 또는 모수 추정치의 변화가 사전 정의된 임계값 아래로 떨어지는지 확인하여 결정됩니다.
기대 최대화(EM) 알고리즘의 작동 방식:
기대값 최대화 알고리즘의 핵심은 데이터세트에서 사용 가능한 관찰 데이터를 사용하여 누락된 데이터를 추정한 다음 해당 데이터를 사용하여 매개변수 값을 업데이트하는 것입니다. EM 알고리즘을 자세히 이해해 봅시다.
EM 알고리즘 흐름도
- 초기화:
- 처음에는 매개변수의 초기값 세트가 고려됩니다. 관측된 데이터가 특정 모델에서 나온다는 가정 하에 불완전한 관측 데이터 세트가 시스템에 제공됩니다.
- 관측된 데이터와 현재 매개변수 추정치를 바탕으로 각 잠재 변수의 사후 확률 또는 책임을 계산합니다.
- 현재 모수 추정치를 사용하여 누락되거나 불완전한 데이터 값을 추정합니다.
- 현재 모수 추정치와 추정된 누락 데이터를 기반으로 관측 데이터의 로그 우도를 계산합니다.
- E-단계에서 얻은 예상 전체 데이터 로그 가능성을 최대화하여 모델의 매개변수를 업데이트합니다.
- 여기에는 일반적으로 로그 우도를 최대화하는 매개변수 값을 찾기 위해 최적화 문제를 해결하는 작업이 포함됩니다.
- 사용되는 특정 최적화 기술은 문제의 성격과 사용되는 모델에 따라 다릅니다.
- 반복 간 로그 우도 또는 모수 값의 변화를 비교하여 수렴을 확인합니다.
- 변경 사항이 미리 정의된 임계값보다 낮으면 중지하고 알고리즘이 수렴된 것으로 간주합니다.
- 그렇지 않으면 E-단계로 돌아가서 수렴이 달성될 때까지 프로세스를 반복합니다.
기대-최대화 알고리즘 단계별 구현
필요한 라이브러리 가져오기
파이썬3
모델 예입니다
import> numpy as np> import> matplotlib.pyplot as plt> from> scipy.stats>import> norm> |
>
>
두 개의 가우스 구성요소를 사용하여 데이터 세트 생성
파이썬3
# Generate a dataset with two Gaussian components> mu1, sigma1>=> 2>,>1> mu2, sigma2>=> ->1>,>0.8> X1>=> np.random.normal(mu1, sigma1, size>=>200>)> X2>=> np.random.normal(mu2, sigma2, size>=>600>)> X>=> np.concatenate([X1, X2])> # Plot the density estimation using seaborn> sns.kdeplot(X)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.show()> |
자바 int를 두 배로 늘리기
>
>
산출 :
밀도 도표
매개변수 초기화
파이썬3
# Initialize parameters> mu1_hat, sigma1_hat>=> np.mean(X1), np.std(X1)> mu2_hat, sigma2_hat>=> np.mean(X2), np.std(X2)> pi1_hat, pi2_hat>=> len>(X1)>/> len>(X),>len>(X2)>/> len>(X)> |
>
>
EM 알고리즘 수행
- 지정된 에포크 수(이 경우 20) 동안 반복합니다.
- 각 에포크에서 E-단계는 각 구성 요소에 대한 가우스 확률 밀도를 평가하고 해당 비율로 가중치를 부여하여 책임(감마 값)을 계산합니다.
- M-단계는 각 구성 요소에 대한 가중 평균과 표준 편차를 계산하여 매개변수를 업데이트합니다.
파이썬3
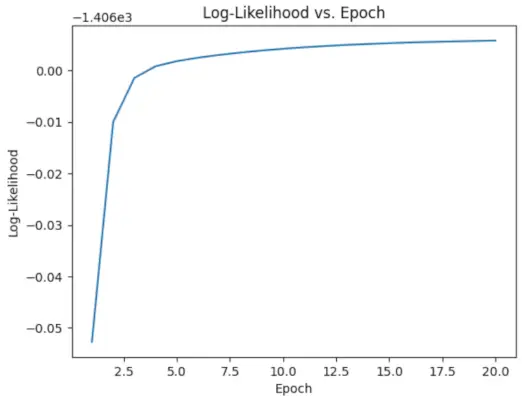
# Perform EM algorithm for 20 epochs> num_epochs>=> 20> log_likelihoods>=> []> for> epoch>in> range>(num_epochs):> ># E-step: Compute responsibilities> >gamma1>=> pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >gamma2>=> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)> >total>=> gamma1>+> gamma2> >gamma1>/>=> total> >gamma2>/>=> total> > ># M-step: Update parameters> >mu1_hat>=> np.>sum>(gamma1>*> X)>/> np.>sum>(gamma1)> >mu2_hat>=> np.>sum>(gamma2>*> X)>/> np.>sum>(gamma2)> >sigma1_hat>=> np.sqrt(np.>sum>(gamma1>*> (X>-> mu1_hat)>*>*>2>)>/> np.>sum>(gamma1))> >sigma2_hat>=> np.sqrt(np.>sum>(gamma2>*> (X>-> mu2_hat)>*>*>2>)>/> np.>sum>(gamma2))> >pi1_hat>=> np.mean(gamma1)> >pi2_hat>=> np.mean(gamma2)> > ># Compute log-likelihood> >log_likelihood>=> np.>sum>(np.log(pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >+> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)))> >log_likelihoods.append(log_likelihood)> # Plot log-likelihood values over epochs> plt.plot(>range>(>1>, num_epochs>+>1>), log_likelihoods)> plt.xlabel(>'Epoch'>)> plt.ylabel(>'Log-Likelihood'>)> plt.title(>'Log-Likelihood vs. Epoch'>)> plt.show()> |
카잘 아가르왈
>
>
산출 :
에포크 대 로그 가능성
최종 추정 밀도를 플롯합니다.
파이썬3
# Plot the final estimated density> X_sorted>=> np.sort(X)> density_estimation>=> pi1_hat>*>norm.pdf(X_sorted,> >mu1_hat,> >sigma1_hat)>+> pi2_hat>*> norm.pdf(X_sorted,> >mu2_hat,> >sigma2_hat)> plt.plot(X_sorted, gaussian_kde(X_sorted)(X_sorted), color>=>'green'>, linewidth>=>2>)> plt.plot(X_sorted, density_estimation, color>=>'red'>, linewidth>=>2>)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.legend([>'Kernel Density Estimation'>,>'Mixture Density'>])> plt.show()> |
>
>
산출 :
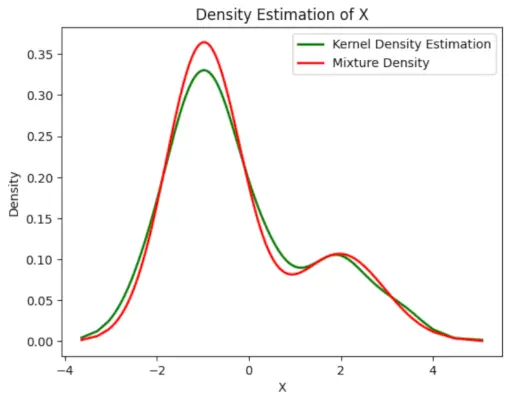
예상 밀도
응용 프로그램 EM 알고리즘
- 샘플에서 누락된 데이터를 채우는 데 사용할 수 있습니다.
- 이는 클러스터의 비지도 학습의 기초로 사용될 수 있습니다.
- HMM(Hidden Markov Model)의 매개변수를 추정하는 목적으로 사용될 수 있습니다.
- 잠재 변수의 값을 발견하는 데 사용할 수 있습니다.
EM 알고리즘의 장점
- 각 반복마다 가능성이 증가한다는 것은 항상 보장됩니다.
- E-단계와 M-단계는 구현 측면에서 많은 문제에 대해 매우 쉬운 경우가 많습니다.
- M단계에 대한 솔루션은 닫힌 형태로 존재하는 경우가 많습니다.
EM 알고리즘의 단점
- 수렴 속도가 느립니다.
- 로컬 최적값으로만 수렴합니다.
- 이는 순방향 및 역방향 확률이 모두 필요합니다(수치 최적화에는 순방향 확률만 필요함).