- 드놈()
dnorm(x, mean, sd)>피놈()
pnorm(x, mean, sd)>큐놈()
qnorm(p, mean, sd)>r표준()
rnorm(n, mean, sd)>어디,
– 엑스 값의 데이터 세트를 나타냅니다. 평균(x) 데이터 세트의 평균을 나타냅니다. 엑스 . 기본값은 0입니다.>– SD(x) 데이터 세트의 표준 편차를 나타냅니다. 엑스 . 기본값은 1입니다.>– N 관측치 수입니다. – 피 확률의 벡터입니다
R에서 정규분포를 생성하는 함수
드놈()
dnorm()> R 프로그래밍의 함수는 분포의 밀도 함수를 측정합니다. 통계에서는 아래 공식으로 측정됩니다.>어디,
 의미가 있고
의미가 있고 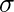 표준편차입니다. 구문:
표준편차입니다. 구문: dnorm(x, mean, sd)>예:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x>=> seq(>->15>,>15>, by>=>0.1>)> > y>=> dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file>=>'dnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>산출:
피놈()
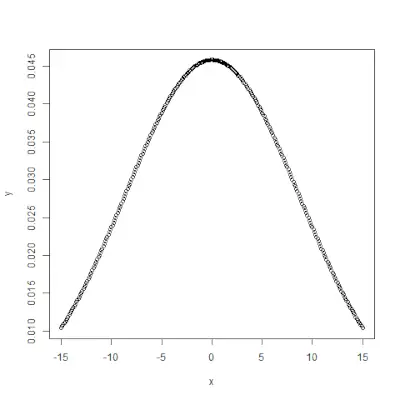
pnorm()> 함수는 난수 X가 x보다 작거나 같은 값을 가질 확률을 측정하는 누적 분포 함수입니다. 즉, 통계에서는 다음과 같이 표현됩니다.>통사론:
pnorm(x, mean, sd)>예:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <>-> seq(>->10>,>10>, by>=>0.1>)> > y <>-> pnorm(x, mean>=> 2.5>, sd>=> 2>)> > # output to be present as PNG file> png(>file>=>'pnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>출력 :
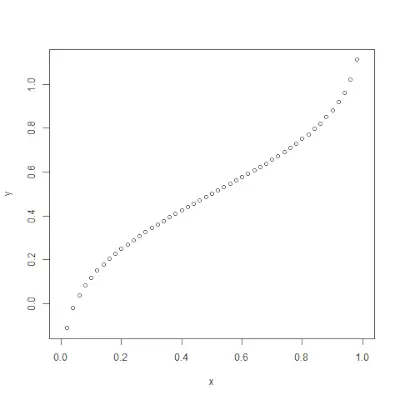
큐놈()
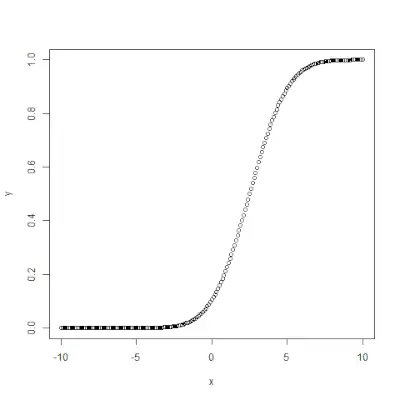
qnorm()> 기능은 반대이다 pnorm()>기능. 확률 값을 취하고 확률 값에 해당하는 출력을 제공합니다. 정규분포의 백분위수를 찾는 데 유용합니다. 통사론: qnorm(p, mean, sd)>예:
# Create a sequence of probability values> # incrementing by 0.02.> x <>-> seq(>0>,>1>, by>=> 0.02>)> > y <>-> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file> => 'qnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |
>
>산출:
r표준()
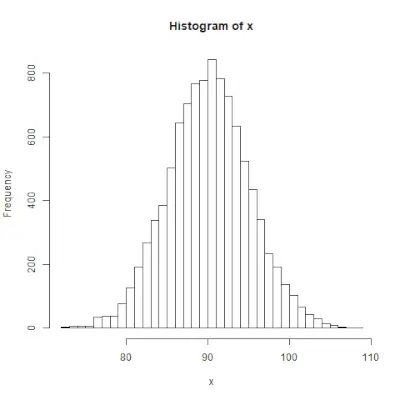
rnorm()> R 프로그래밍의 함수는 정규 분포를 따르는 난수 벡터를 생성하는 데 사용됩니다. 통사론: rnorm(x, mean, sd)>예:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <>-> rnorm(>10000>, mean>=>90>, sd>=>5>)> > # output to be present as PNG file> png(>file> => 'rnormExample.webp'>)> > # Create the histogram with 50 bars> hist(x, breaks>=>50>)> > # Save the file.> dev.off()> |
>
>출력 :