단일 관계로 정의된 대규모 데이터베이스는 데이터 중복을 초래할 수 있습니다. 이러한 데이터 반복으로 인해 다음이 발생할 수 있습니다.
- 관계를 매우 크게 만듭니다.
- 관련된 많은 기록을 검색해야 하기 때문에 데이터를 유지하고 업데이트하는 것은 쉽지 않습니다.
- 디스크 공간과 리소스가 낭비되고 활용도가 떨어집니다.
- 오류와 불일치가 발생할 가능성이 높아집니다.
따라서 이러한 문제를 해결하려면 중복된 데이터와의 관계를 원하는 속성을 만족하는 더 작고 단순하며 잘 구조화된 관계로 분석하고 분해해야 합니다. 정규화는 관계를 더 적은 속성을 가진 관계로 분해하는 프로세스입니다.
정규화란 무엇입니까?
- 정규화는 데이터베이스의 데이터를 구성하는 프로세스입니다.
- 정규화는 관계 또는 관계 집합의 중복을 최소화하는 데 사용됩니다. 또한 삽입, 업데이트 및 삭제 이상과 같은 바람직하지 않은 특성을 제거하는 데에도 사용됩니다.
- 정규화는 더 큰 테이블을 더 작은 테이블로 나누고 관계를 사용하여 연결합니다.
- 일반 형식은 데이터베이스 테이블의 중복을 줄이는 데 사용됩니다.
정규화가 필요한 이유는 무엇입니까?
int를 문자열로 C++
관계를 정규화하는 주된 이유는 이러한 이상 현상을 제거하는 것입니다. 이상 현상을 제거하지 못하면 데이터 중복이 발생하고 데이터베이스가 커짐에 따라 데이터 무결성 및 기타 문제가 발생할 수 있습니다. 정규화는 좋은 데이터베이스 구조를 만드는 데 도움이 되는 일련의 지침으로 구성됩니다.
데이터 수정 이상은 세 가지 유형으로 분류될 수 있습니다.
정규형의 유형:
정규화는 정규 형식이라는 일련의 단계를 통해 작동됩니다. 정규형은 개별 관계에 적용됩니다. 관계가 제약 조건을 만족하면 특정 정규 형식이라고 합니다.
다음은 다양한 유형의 정규 형식입니다.
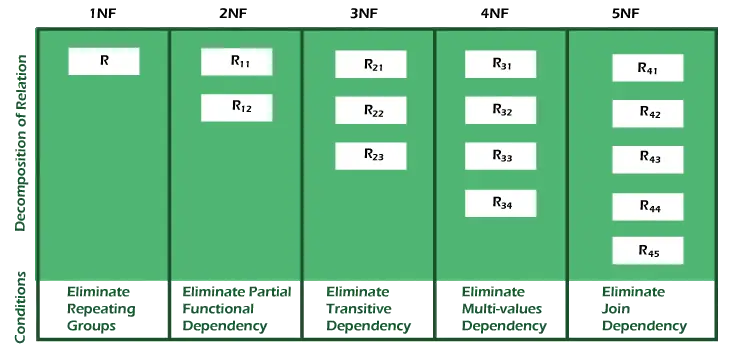
| 일반형 | 설명 |
|---|---|
| 1NF | 원자 값을 포함하는 관계는 1NF에 속합니다. |
| 2NF | 관계가 1NF이고 키가 아닌 모든 속성이 기본 키에 따라 완전히 기능하는 경우 관계는 2NF가 됩니다. |
| 3NF | 관계가 2NF이고 전환 종속성이 존재하지 않으면 관계는 3NF가 됩니다. |
| BCNF | 3NF에 대한 보다 강력한 정의는 Boyce Codd의 정규형으로 알려져 있습니다. |
| 4NF | 관계가 Boyce Codd의 정규 형식이고 다중 값 종속성이 없는 경우 관계는 4NF가 됩니다. |
| 5NF | 관계는 5NF에 있습니다. 4NF이고 조인 종속성을 포함하지 않는 경우 조인은 무손실이어야 합니다. |
정규화의 장점
- 정규화는 데이터 중복을 최소화하는 데 도움이 됩니다.
- 전체 데이터베이스 구성이 더 커졌습니다.
- 데이터베이스 내의 데이터 일관성.
- 훨씬 더 유연한 데이터베이스 설계.
- 관계 무결성의 개념을 적용합니다.
정규화의 단점
- 사용자에게 필요한 것이 무엇인지 알기 전에는 데이터베이스 구축을 시작할 수 없습니다.
- 관계를 더 높은 정규 형식(예: 4NF, 5NF)으로 정규화하면 성능이 저하됩니다.
- 더 높은 수준의 관계를 정상화하는 것은 매우 시간이 많이 걸리고 어렵습니다.
- 부주의하게 분해하면 데이터베이스 설계가 잘못되어 심각한 문제가 발생할 수 있습니다.