Python은 데이터 중심의 환상적인 생태계 덕분에 데이터 분석을 수행하는 데 훌륭한 언어입니다. 파이썬 패키지. 팬더 이러한 패키지 중 하나이며 데이터를 훨씬 쉽게 가져오고 분석할 수 있습니다.
팬더 데이터프레임 평균()
팬더 데이터프레임.평균() 함수는 요청된 축에 대한 값의 평균을 반환합니다. 메소드가 pandas 시리즈 객체에 적용되면 메소드는 모든 관측치의 평균값인 스칼라 값을 반환합니다. 팬더 데이터프레임 . 메소드가 Pandas Dataframe 객체에 적용되면 메소드는 팬더 시리즈 지정된 축에 대한 값의 평균을 포함하는 객체입니다.
통사론: DataFrame.mean(축=0, 건너뛰기=True, 수준=없음, 숫자_만=False, **kwargs)
매개변수:
- 축 : {색인(0), 열(1)}
- 주문하다 : 결과 계산 시 NA/null 값 제외
- 수준 : 축이 MultiIndex(계층적)인 경우 특정 수준을 따라 계산하여 시리즈로 축소합니다.
- 숫자만 : float, int, boolean 열만 포함합니다. 없음인 경우 모든 것을 사용하려고 시도한 다음 숫자 데이터만 사용합니다. 시리즈에는 구현되지 않았습니다.
반품 : 평균: 시리즈 또는 DataFrame(레벨이 지정된 경우)
중요한
팬더 DataFrame.mean() 예
예시 1:
평균() 함수를 사용하여 인덱스 축에 대한 모든 관측치의 평균을 찾습니다.
파이썬 # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 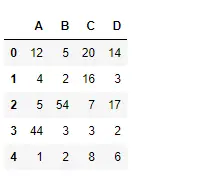
Dataframe.mean() 함수를 사용하여 인덱스 축에 대한 평균을 찾아보겠습니다.
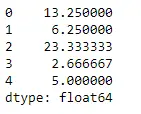
파이썬 # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
산출:
예시 2:
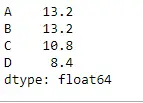
None 값이 있는 데이터 프레임에서는 평균() 함수를 사용합니다. 또한 열 축에 대한 평균을 찾습니다.
파이썬 # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> 산출: