Pandas.apply를 사용하면 사용자가 함수를 전달하고 Pandas 시리즈의 모든 단일 값에 적용할 수 있습니다. 이 기능은 데이터 과학 및 기계 학습에서 효율적으로 사용되기 때문에 필요한 조건에 따라 데이터를 분리하는 데 도움이 되므로 Pandas 라이브러리에 큰 개선이 이루어졌습니다.
설치:
자바 8 기능
터미널에서 다음 명령을 사용하여 Pandas 모듈을 Python 파일로 가져옵니다.
pip install pandas>
csv 파일을 읽고 이를 팬더 시리즈로 압축하려면 다음 명령을 사용합니다.
import pandas as pd s = pd.read_csv('stock.csv', squeeze=True)> 통사론:
s.apply(func, convert_dtype=True, args=())>
매개변수:
기능: .apply는 함수를 가져와서 pandas 시리즈의 모든 값에 적용합니다. 변환_d유형: 함수의 연산에 따라 dtype을 변환합니다. 인수=(): 계열 대신 함수에 전달할 추가 인수입니다. 반환 유형: 기능/작동 적용 후 Pandas 시리즈.
예시 #1:
다음 예에서는 함수를 전달하고 계열의 각 요소 값을 확인한 후 그에 따라 low, Normal 또는 High를 반환합니다.
파이썬3
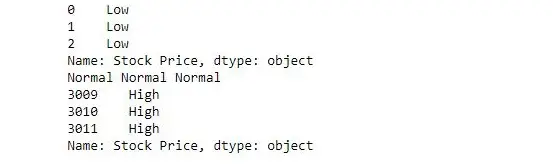
import> pandas as pd> # reading csv> s>=> pd.read_csv('stock.csv', squeeze>=> True>)> # defining function to check price> def> fun(num):> >if> num<>200>:> >return> 'Low'> >elif> num>>=> 200> and> num<>400>:> >return> 'Normal'> >else>:> >return> 'High'> # passing function to apply and storing returned series in new> new>=> s.>apply>(fun)> # printing first 3 element> print>(new.head(>3>))> # printing elements somewhere near the middle of series> print>(new[>1400>], new[>1500>], new[>1600>])> # printing last 3 elements> print>(new.tail(>3>))> |
>
>
산출:
예시 #2:
다음 예에서는 람다를 사용하여 .apply 자체에서 임시 익명 함수를 만듭니다. 계열의 각 값에 5를 더하고 새 계열을 반환합니다.
파이썬3
import> pandas as pd> s>=> pd.read_csv('stock.csv', squeeze>=> True>)> # adding 5 to each value> new>=> s.>apply>(>lambda> num : num>+> 5>)> # printing first 5 elements of old and new series> print>(s.head(),>'
'>, new.head())> # printing last 5 elements of old and new series> print>(>'
'>, s.tail(),>'
'>, new.tail())> |
>
잠을 자다
>
산출:
0 50.12 1 54.10 2 54.65 3 52.38 4 52.95 Name: Stock Price, dtype: float64 0 55.12 1 59.10 2 59.65 3 57.38 4 57.95 Name: Stock Price, dtype: float64 3007 772.88 3008 771.07 3009 773.18 3010 771.61 3011 782.22 Name: Stock Price, dtype: float64 3007 777.88 3008 776.07 3009 778.18 3010 776.61 3011 787.22 Name: Stock Price, dtype: float64>
관찰된 바와 같이, 새 값 = 이전 값 + 5