회귀 및 분류 알고리즘은 지도 학습 알고리즘입니다. 두 알고리즘 모두 기계 학습의 예측에 사용되며 레이블이 지정된 데이터 세트와 함께 작동합니다. 그러나 둘 사이의 차이점은 서로 다른 기계 학습 문제에 사용되는 방식입니다.
회귀 알고리즘이 사용되는 회귀 알고리즘과 분류 알고리즘의 주요 차이점 연속성을 예측하다 가격, 급여, 연령 등의 값과 분류 알고리즘을 사용하여 이산값 예측/분류 예: 남성 또는 여성, 참 또는 거짓, 스팸 또는 스팸 아님 등
아래 다이어그램을 고려하십시오.
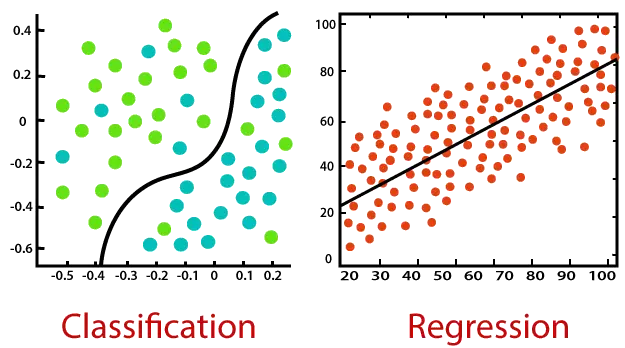
분류:
분류는 다양한 매개변수를 기반으로 데이터 세트를 클래스로 나누는 데 도움이 되는 함수를 찾는 프로세스입니다. 분류에서 컴퓨터 프로그램은 훈련 데이터 세트에 대해 훈련을 받고 해당 훈련을 기반으로 데이터를 다양한 클래스로 분류합니다.
분류 알고리즘의 임무는 입력(x)을 이산 출력(y)에 매핑하는 매핑 함수를 찾는 것입니다.
예: 분류 문제를 이해하는 가장 좋은 예는 이메일 스팸 감지입니다. 이 모델은 다양한 매개변수에 따라 수백만 개의 이메일을 기반으로 훈련되었으며 새 이메일을 수신할 때마다 해당 이메일이 스팸인지 여부를 식별합니다. 이메일이 스팸인 경우 스팸 폴더로 이동됩니다.
ML 분류 알고리즘의 유형:
분류 알고리즘은 다음 유형으로 더 나눌 수 있습니다.
- 로지스틱 회귀
- K-최근접이웃
- 서포트 벡터 머신
- 커널 SVM
- 나이브 베이즈
- 의사결정나무 분류
- 랜덤 포레스트 분류
회귀:
회귀분석은 종속변수와 독립변수 사이의 상관관계를 찾는 과정입니다. 예측과 같은 연속변수를 예측하는 데 도움이 됩니다. 시장 경향 , 집값 예측 등
회귀 알고리즘의 임무는 입력 변수(x)를 연속 출력 변수(y)에 매핑하는 매핑 함수를 찾는 것입니다.
예: 일기예보를 하고 싶다고 가정하자. 이를 위해 회귀(Regression) 알고리즘을 사용할 것이다. 날씨 예측에서는 과거의 데이터를 토대로 모델을 학습시키고, 학습이 완료되면 미래의 날씨를 쉽게 예측할 수 있습니다.
회귀 알고리즘 유형:
- 단순 선형 회귀
- 다중 선형 회귀
- 다항식 회귀
- 지원 벡터 회귀
- 의사결정 트리 회귀
- 랜덤 포레스트 회귀
회귀와 분류의 차이점
| 회귀 알고리즘 | 분류 알고리즘 |
|---|---|
| 회귀 분석에서 출력 변수는 연속적 성격 또는 실제 값이어야 합니다. | 분류에서 출력 변수는 이산형 값이어야 합니다. |
| 회귀 알고리즘의 임무는 입력 값(x)을 연속 출력 변수(y)와 매핑하는 것입니다. | 분류 알고리즘의 임무는 입력 값(x)을 이산 출력 변수(y)와 매핑하는 것입니다. |
| 회귀 알고리즘은 연속 데이터에 사용됩니다. | 분류 알고리즘은 이산 데이터에 사용됩니다. |
| 회귀 분석에서는 출력을 보다 정확하게 예측할 수 있는 최적의 선을 찾으려고 노력합니다. | 분류에서는 데이터 세트를 여러 클래스로 나눌 수 있는 결정 경계를 찾으려고 합니다. |
| 회귀 알고리즘은 날씨 예측, 주택 가격 예측 등과 같은 회귀 문제를 해결하는 데 사용될 수 있습니다. | 분류 알고리즘은 스팸 이메일 식별, 음성 인식, 암세포 식별 등과 같은 분류 문제를 해결하는 데 사용될 수 있습니다. |
| 회귀 알고리즘은 선형 회귀와 비선형 회귀로 더 나눌 수 있습니다. | 분류 알고리즘은 Binary Classifier와 Multi-class Classifier로 나눌 수 있습니다. |