건너뛰기 목록이란 무엇입니까?
건너뛰기 목록은 확률적 데이터 구조입니다. 스킵 리스트는 연결 리스트와 함께 정렬된 요소 목록 또는 데이터를 저장하는 데 사용됩니다. 이를 통해 요소나 데이터의 처리 과정을 효율적으로 볼 수 있습니다. 한 단계에서 전체 목록의 여러 요소를 건너뛰므로 건너뛰기 목록이라고 합니다.
건너뛰기 목록은 연결 목록의 확장 버전입니다. 이를 통해 사용자는 요소를 매우 빠르게 검색, 제거 및 삽입할 수 있습니다. 이는 후속 요소의 링크 계층 구조를 유지하는 요소 집합을 포함하는 기본 목록으로 구성됩니다.
목록 구조 건너뛰기
가장 낮은 레이어와 맨 위 레이어의 두 가지 레이어로 구성됩니다.
스킵 리스트의 최하위 레이어는 공통적으로 정렬된 연결 리스트이고, 스킵 리스트의 맨 위 레이어는 요소를 건너뛰는 '빠른 줄'과 같습니다.
건너뛰기 목록의 복잡도 표
| 예 아니오 | 복잡성 | 평균 사례 | 최악의 경우 |
|---|---|---|---|
| 1. | 접근 복잡성 | 오(로그인) | 에) |
| 2. | 검색 복잡성 | 오(로그인) | 에) |
| 삼. | 복잡성 삭제 | 오(로그인) | 에) |
| 4. | 복잡성 삽입 | 오(로그인) | 에) |
| 5. | 공간 복잡도 | - | O(로그인) |
건너뛰기 목록 작업
건너뛰기 목록의 작동을 이해하기 위해 예를 들어 보겠습니다. 이 예에는 14개의 노드가 있으며 다이어그램에 표시된 것처럼 이러한 노드는 두 개의 레이어로 나뉩니다.
아래 레이어는 다이어그램에서 볼 수 있듯이 모든 노드를 연결하는 공통선이고, 상위 레이어는 메인 노드만 연결하는 급행선입니다.
이 예에서는 47을 찾고 싶다고 가정합니다. 급행선의 첫 번째 노드부터 검색을 시작하고 47과 같거나 47보다 큰 노드를 찾을 때까지 급행선에서 계속 실행됩니다.
예를 보면 급행선에는 47이 존재하지 않으므로 47보다 작은 노드인 40을 검색하면 된다. 이제 40의 도움을 받아 일반선으로 가서 47을 검색하면, 다이어그램에 표시된 것처럼.
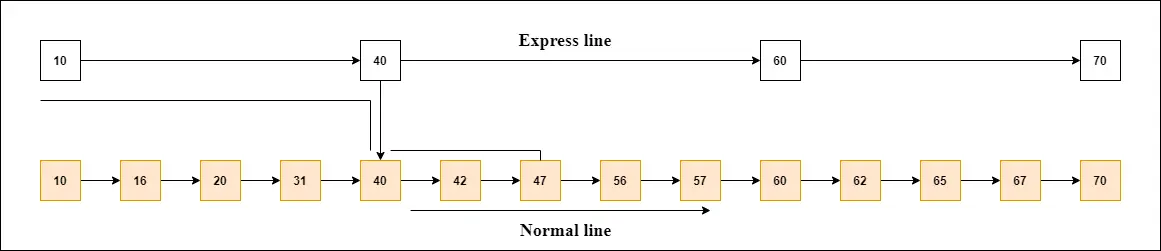
참고: '급행선'에서 이와 같은 노드를 찾으면 포인터를 사용하여 이 노드에서 '일반 차선'으로 이동하고 일반 라인에서 해당 노드를 검색하면 됩니다.
건너뛰기 목록 기본 작업
건너뛰기 목록에는 다음과 같은 유형의 작업이 있습니다.
삽입 작업의 알고리즘
Insertion (L, Key) local update [0...Max_Level + 1] a = L → header for i = L → level down to 0 do. while a → forward[i] → key forward[i] update[i] = a a = a → forward[0] lvl = random_Level() if lvl > L → level then for i = L → level + 1 to lvl do update[i] = L → header L → level = lvl a = makeNode(lvl, Key, value) for i = 0 to level do a → forward[i] = update[i] → forward[i] update[i] → forward[i] = a
삭제 작업의 알고리즘
Deletion (L, Key) local update [0... Max_Level + 1] a = L → header for i = L → level down to 0 do. while a → forward[i] → key forward[i] update[i] = a a = a → forward[0] if a → key = Key then for i = 0 to L → level do if update[i] → forward[i] ? a then break update[i] → forward[i] = a → forward[i] free(a) while L → level > 0 and L → header → forward[L → level] = NIL do L → level = L → level - 1
검색 작업의 알고리즘
Searching (L, SKey) a = L → header loop invariant: a → key level down to 0 do. while a → forward[i] → key forward[i] a = a → forward[0] if a → key = SKey then return a → value else return failure
예시 1: 건너뛰기 목록을 만듭니다. 빈 건너뛰기 목록에 다음 키를 삽입하려고 합니다.
- 레벨 1에서는 6입니다.
- 레벨 1은 29입니다.
- 레벨 4에서는 22입니다.
- 9레벨이면 3레벨.
- 레벨 1에서는 17입니다.
- 레벨 2로 4.
연령:
1 단계: 레벨 1에 6을 삽입합니다.

2 단계: 레벨 1에 29 삽입

3단계: 레벨 4에 22 삽입

4단계: 레벨 3에 9 삽입

5단계: 레벨 1에 17을 삽입합니다.

6단계: 레벨 2에 4 삽입

예 2: 키 17을 검색하려는 이 예를 생각해 보세요.

연령:

건너뛰기 목록의 장점
- 건너뛰기 목록에 새 노드를 삽입하려는 경우 건너뛰기 목록에 회전이 없기 때문에 노드가 매우 빠르게 삽입됩니다.
- 스킵 리스트는 해시 테이블과 이진 검색 트리에 비해 구현이 간단합니다.
- 노드를 정렬된 형태로 저장하기 때문에 목록에서 노드를 찾는 것은 매우 간단합니다.
- 건너뛰기 목록 알고리즘은 인덱싱 가능한 건너뛰기 목록, 트리 또는 우선순위 대기열과 같은 보다 구체적인 구조에서 매우 쉽게 수정할 수 있습니다.
- 건너뛰기 목록은 강력하고 신뢰할 수 있는 목록입니다.
건너뛰기 목록의 단점
- 균형 트리보다 더 많은 메모리가 필요합니다.
- 역검색은 허용되지 않습니다.
- 스킵 리스트는 링크드 리스트보다 훨씬 느리게 노드를 검색합니다.
건너뛰기 목록의 적용
- 분산 애플리케이션에서 사용되며 분산 애플리케이션의 포인터와 시스템을 나타냅니다.
- 잠금 경합이 낮은 동적 탄력적 동시 대기열을 구현하는 데 사용됩니다.
- 또한 QMap 템플릿 클래스와 함께 사용됩니다.
- 건너뛰기 목록의 인덱싱은 중앙값 문제를 실행하는 데 사용됩니다.
- 건너뛰기 목록은 Lucene 검색에서 델타 인코딩 게시에 사용됩니다.