우리는 모든 요소가 순차적으로 배열되어 있는 배열, 연결 리스트, 스택 및 큐와 같은 선형 데이터 구조를 읽습니다. 다양한 데이터 구조는 다양한 종류의 데이터에 사용됩니다.
데이터 구조를 선택할 때 몇 가지 요소가 고려됩니다.
나무 계층적 데이터를 나타내는 데이터 구조 중 하나이기도 합니다. 직원과 직위를 계층적 형태로 표시한다고 가정하면 아래와 같이 표현할 수 있습니다.
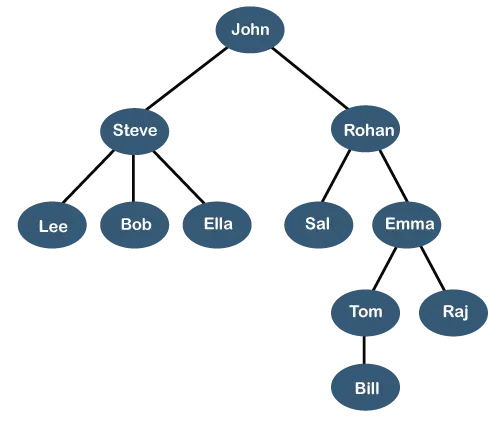
위의 트리는 조직 계층 어떤 회사의. 위의 구조에서, 남자 은 최고 경영자 회사의 직원이고 John에게는 다음과 같은 두 명의 직속 부하 직원이 있습니다. 스티브 그리고 로한 . Steve는 세 명의 직속 부하직원을 두고 있습니다. 리, 밥, 엘라 어디 스티브 관리자입니다. Bob에게는 다음과 같은 두 명의 직속 부하 직원이 있습니다. 일 것이다 그리고 엠마 . 엠마 이름이 두 명의 직속 부하 직원이 있습니다. 톰 그리고 주권 . Tom이라는 직속 부하 직원이 한 명 있습니다. 청구서 . 이 특별한 논리적 구조는 다음과 같이 알려져 있습니다. 나무 . 그 구조가 실제 나무와 유사해서 이름이 붙여졌습니다. 나무 . 이 구조에서는 뿌리 가 맨 위에 있고 가지가 아래쪽으로 움직입니다. 따라서 트리 데이터 구조는 데이터를 계층적으로 저장하는 효율적인 방법이라고 말할 수 있습니다.
트리 데이터 구조의 몇 가지 핵심 사항을 이해해 보겠습니다.
- 트리 데이터 구조는 계층 구조를 나타내거나 시뮬레이션하기 위해 서로 연결된 노드로 알려진 개체 또는 엔터티의 컬렉션으로 정의됩니다.
- 트리 데이터 구조는 순차적인 방식으로 저장되지 않기 때문에 비선형 데이터 구조입니다. 트리의 요소가 여러 수준으로 배열되는 계층 구조입니다.
- 트리 데이터 구조에서 최상위 노드를 루트 노드라고 합니다. 각 노드에는 일부 데이터가 포함되어 있으며 데이터는 모든 유형이 될 수 있습니다. 위의 트리 구조에서 노드에는 직원의 이름이 포함되므로 데이터 유형은 문자열이 됩니다.
- 각 노드에는 일부 데이터와 하위 노드라고 할 수 있는 다른 노드의 링크 또는 참조가 포함되어 있습니다.
트리 데이터 구조에 사용되는 몇 가지 기본 용어입니다.
아래에 표시된 트리 구조를 고려해 보겠습니다.
다음 자바

위의 구조에서 각 노드에는 숫자가 표시되어 있습니다. 위 그림에 표시된 각 화살표는 링크 두 노드 사이.
트리 데이터 구조의 속성

트리 데이터 구조의 속성에 따라 트리는 다양한 카테고리로 분류됩니다.
트리 구현
트리 데이터 구조는 포인터의 도움으로 노드를 동적으로 생성하여 생성할 수 있습니다. 메모리의 트리는 아래와 같이 표현될 수 있습니다.

위 그림은 메모리 내 트리 데이터 구조의 표현을 보여줍니다. 위 구조에서 노드에는 세 개의 필드가 포함되어 있습니다. 두 번째 필드는 데이터를 저장합니다. 첫 번째 필드는 왼쪽 자식의 주소를 저장하고 세 번째 필드는 오른쪽 자식의 주소를 저장합니다.
ABS C 코드
프로그래밍에서 노드의 구조는 다음과 같이 정의될 수 있습니다.
struct node { int data; struct node *left; struct node *right; } 위의 구조는 이진 트리에 대해서만 정의할 수 있습니다. 왜냐하면 이진 트리는 최대 2개의 자식을 가질 수 있고 일반 트리는 2개 이상의 자식을 가질 수 있기 때문입니다. 일반 트리의 노드 구조는 이진 트리와 다릅니다.
나무의 응용
트리의 응용은 다음과 같습니다.
트리 데이터 구조의 유형
트리 데이터 구조의 유형은 다음과 같습니다.
긴 문자열 자바

있을 수있다 N 일반 트리의 하위 트리 수. 일반 트리에서는 하위 트리의 노드를 정렬할 수 없으므로 하위 트리는 정렬되지 않습니다.
비어 있지 않은 모든 트리에는 아래쪽 가장자리가 있으며 이러한 가장자리는 다음과 같은 노드에 연결됩니다. 하위 노드 . 루트 노드에는 수준 0이라는 레이블이 지정됩니다. 동일한 상위 노드를 갖는 노드는 다음과 같습니다. 형제 .

이진 트리에 대한 자세한 내용을 보려면 아래 링크를 클릭하세요.
https://www.javatpoint.com/binary-tree
왼쪽 하위 트리의 모든 노드는 루트 노드의 값보다 작은 값을 포함해야 하며, 오른쪽 하위 트리의 각 노드의 값은 루트 노드의 값보다 커야 합니다.
노드는 다음과 같은 사용자 정의 데이터 유형을 사용하여 생성될 수 있습니다. 구조체, 아래 그림과 같이:
struct node { int data; struct node *left; struct node *right; } 위는 데이터 필드, 두 번째 필드는 노드 유형의 왼쪽 포인터, 세 번째 필드는 노드 유형의 오른쪽 포인터라는 세 가지 필드가 있는 노드 구조입니다.
이진 검색 트리에 대한 자세한 내용을 보려면 아래 링크를 클릭하십시오.
https://www.javatpoint.com/binary-search-tree
이는 이진 트리 유형 중 하나이거나 이진 검색 트리의 변형이라고 말할 수 있습니다. AVL 트리는 다음의 속성을 만족합니다. 이진 트리 뿐만 아니라 이진 검색 트리 . 에 의해 발명된 자체 균형 이진 검색 트리입니다. 아델슨 벨스키 린다스 . 여기서 셀프 밸런싱(self-balancing)이란 왼쪽 하위 트리와 오른쪽 하위 트리의 높이 균형을 맞추는 것을 의미합니다. 이 균형은 다음과 같은 측면에서 측정됩니다. 균형 요소 .
트리가 이진 검색 트리와 균형 요소를 따르는 경우 트리를 AVL 트리로 간주할 수 있습니다. 균형 요인은 다음과 같이 정의될 수 있습니다. 왼쪽 하위 트리의 높이와 오른쪽 하위 트리의 높이 차이 . 균형 요소의 값은 0, -1 또는 1이어야 합니다. 따라서 AVL 트리의 각 노드는 0, -1 또는 1 중 하나의 균형 요소 값을 가져야 합니다.
AVL 트리에 대한 자세한 내용을 보려면 아래 링크를 클릭하십시오.
https://www.javatpoint.com/avl-tree
레드-블랙 트리 이진 검색 트리입니다. 레드-블랙 트리의 전제 조건은 이진 검색 트리에 대해 알아야 한다는 것입니다. 이진 탐색 트리에서는 왼쪽 하위 트리의 값이 해당 노드의 값보다 작아야 하고, 오른쪽 하위 트리의 값이 해당 노드의 값보다 커야 합니다. 평균적인 경우 이진 검색의 시간 복잡도는 로그라는 것을 알고 있습니다.2n에서 가장 좋은 경우는 O(1)이고, 최악의 경우는 O(n)입니다.
트리에서 어떤 작업이 수행될 때 검색, 삽입, 삭제 등과 같은 모든 작업에 시간이 덜 걸리고 이러한 모든 작업의 시간 복잡도가 통나무2N.
레드-블랙 트리 자체 균형 이진 검색 트리입니다. AVL 트리는 높이 균형 이진 검색 트리이기도 합니다. Red-Black 트리가 필요한 이유 . AVL 트리에서는 트리의 균형을 맞추는 데 몇 번의 회전이 필요한지 알 수 없지만 Red-black 트리에서는 트리의 균형을 맞추는 데 최대 2회전이 필요합니다. 여기에는 트리의 균형을 보장하기 위해 노드의 빨간색 또는 검정색을 나타내는 하나의 추가 비트가 포함되어 있습니다.
스플레이 트리 데이터 구조는 최근에 액세스한 요소가 일부 회전 작업을 수행하여 트리의 루트 위치에 배치되는 이진 검색 트리이기도 합니다. 여기, 튀는 최근에 액세스한 노드를 의미합니다. 이것은 자체 균형 다음과 같은 명시적인 균형 조건이 없는 이진 검색 트리 AVL 나무.
스플레이 트리의 높이가 균형을 이루지 않을 가능성이 있습니다. 즉, 왼쪽 및 오른쪽 하위 트리의 높이가 다를 수 있지만 스플레이 트리의 작업은 다음 순서를 따릅니다. 침착한 시간은 어디에 N 노드 수입니다.
CSS에서 마우스를 가리키면
스플레이 트리는 균형 잡힌 트리이지만 각 작업 후에 회전이 수행되어 균형 잡힌 트리가 되기 때문에 높이 균형 트리로 간주할 수 없습니다.
Treap 데이터 구조는 Tree 및 Heap 데이터 구조에서 나왔습니다. 따라서 이는 트리 및 힙 데이터 구조의 속성으로 구성됩니다. 이진 탐색 트리에서 왼쪽 하위 트리의 각 노드는 루트 노드의 값과 같거나 작아야 하며, 오른쪽 하위 트리의 각 노드는 루트 노드의 값과 같거나 커야 합니다. 힙 데이터 구조에서는 오른쪽 및 왼쪽 하위 트리 모두 루트보다 더 큰 키를 포함합니다. 따라서 루트 노드에 가장 낮은 값이 포함되어 있다고 말할 수 있습니다.
당신은 스플 라이스입니다
Treap 데이터 구조에서 각 노드는 두 가지를 모두 갖습니다. 열쇠 그리고 우선 사항 여기서 키는 이진 검색 트리에서 파생되고 우선 순위는 힙 데이터 구조에서 파생됩니다.
그만큼 함정 데이터 구조는 아래에 주어진 두 가지 속성을 따릅니다.
- 노드의 오른쪽 자식>=현재 노드 및 노드의 왼쪽 자식<=current node (binary tree)< li>
- 모든 하위 트리의 하위 항목은 노드(힙)보다 커야 합니다.
B-트리는 균형 잡힌 트리입니다. M자형 나무 어디에 중 트리의 순서를 정의합니다. 지금까지 우리는 노드에 하나의 키만 포함되어 있지만 b-tree는 하나 이상의 키와 2개 이상의 자식을 가질 수 있다는 것을 읽었습니다. 항상 정렬된 데이터를 유지합니다. 이진 트리에서는 리프 노드가 서로 다른 레벨에 있을 수 있지만 B-트리에서는 모든 리프 노드가 동일한 레벨에 있어야 합니다.
순서가 m이면 노드는 다음과 같은 속성을 갖습니다.
- b-트리의 각 노드는 최대값을 가질 수 있습니다. 중 어린이들
- 최소 자식의 경우 리프 노드에는 0개의 자식이 있고 루트 노드에는 최소 2개의 자식이 있으며 내부 노드에는 최소 m/2 자식의 최대 한도가 있습니다. 예를 들어, m 값이 5이면 노드는 5개의 자식을 가질 수 있고 내부 노드는 최대 3개의 자식을 포함할 수 있음을 의미합니다.
- 각 노드에는 최대(m-1)개의 키가 있습니다.
루트 노드에는 최소 1개의 키가 포함되어야 하며 다른 모든 노드에는 최소한 1개의 키가 포함되어야 합니다. 한도 m/2 - 1 열쇠.