Excel 시트는 매우 본능적이고 사용자 친화적이므로 기술이 부족한 사람이라도 대규모 데이터 세트를 조작하는 데 이상적입니다. Excel 파일의 내용을 조작하고 자동화하는 방법을 배울 수 있는 곳을 찾고 있다면 파이썬 , 더 이상 보지 마십시오. 당신은 바로 이곳에 있습니다.
이 기사에서는 사용 방법을 배웁니다. 팬더 Excel 스프레드시트로 작업합니다. 이 기사에서는 다음에 대해 알아볼 것입니다.
- 읽다 엑셀 파일 Python에서 Pandas 사용하기
- Pandas 설치 및 가져오기
- Pandas를 사용하여 여러 Excel 시트 읽기
- 다양한 Pandas 기능 적용
Python에서 Pandas를 사용하여 Excel 파일 읽기
팬더 설치
Python에 Pandas를 설치하려면 명령 프롬프트에서 다음 명령을 사용할 수 있습니다.
pip install pandas>
Anaconda에 Pandas를 설치하려면 Anaconda 터미널에서 다음 명령을 사용할 수 있습니다.
conda install pandas>
팬더 가져오기
우선, 다음 명령을 실행하여 수행할 수 있는 Pandas 모듈을 가져와야 합니다.
파이썬3
import> pandas as pd> |
>
>
입력 파일: Excel 파일이 다음과 같다고 가정해 보겠습니다.
시트 1:

시트 1
시트 2:
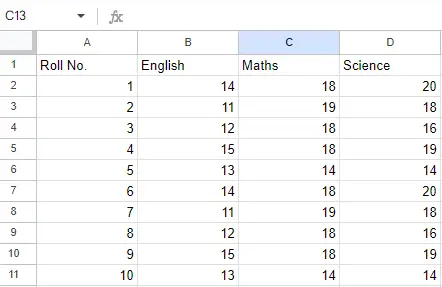
시트 2
이제 Pandas의 read_excel 함수를 사용하여 Excel 파일을 가져와서 Python에서 Pandas를 사용하여 Excel 파일을 읽을 수 있습니다. 두 번째 문은 Excel에서 데이터를 읽고 newData 변수로 표시되는 pandas 데이터 프레임에 저장합니다.
파이썬3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
산출:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Concat() 메서드를 사용하여 여러 시트 로드
Excel 통합 문서에 여러 시트가 있는 경우 명령은 첫 번째 시트에서 데이터를 가져옵니다. 통합 문서의 모든 시트로 데이터 프레임을 만들려면 가장 쉬운 방법은 서로 다른 데이터 프레임을 별도로 만든 다음 연결하는 것입니다. read_excel 메소드는 sheet_name 및 index_col 인수를 사용하여 프레임을 구성해야 하는 시트를 지정할 수 있으며 index_col은 아래와 같이 제목 열을 지정합니다.
예:
세 번째 문은 두 시트를 연결합니다. 이제 전체 데이터 프레임을 확인하려면 다음 명령을 실행하면 됩니다.
파이썬3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
산출:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Pandas의 Head() 및 Tail() 메서드
데이터 프레임의 상단과 하단에서 5개의 열을 보려면 명령을 실행하면 됩니다. 이것 머리() 그리고 꼬리() 메소드는 또한 표시할 열 수에 대한 숫자로 인수를 사용합니다.
파이썬3
print>(newData.head())> print>(newData.tail())> |
>
>
산출:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Shape() 메서드
그만큼 모양() 메서드 다음과 같이 데이터 프레임의 행과 열 수를 보는 데 사용할 수 있습니다.
파이썬3
newData.shape> |
>
>
산출:
(20, 3)>
Pandas의 Sort_values() 메서드
열에 숫자 데이터가 포함되어 있으면 다음을 사용하여 해당 열을 정렬할 수 있습니다. sort_values() 팬더의 메소드는 다음과 같습니다.
파이썬3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
이제 정렬된 열의 상위 5개 값을 원한다고 가정하고 여기에서 head() 메서드를 사용할 수 있습니다.
파이썬3
sorted_column.head(>5>)> |
>
>
산출:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
아래와 같이 데이터 프레임의 숫자 열을 사용하여 이를 수행할 수 있습니다.
파이썬3
newData[>'Maths'>].head()> |
>
>
산출:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
팬더 설명() 메서드
이제 데이터가 대부분 숫자라고 가정해 보겠습니다. 다음을 사용하여 데이터 프레임에 대한 평균, 최대, 최소 등과 같은 통계 정보를 얻을 수 있습니다. 설명하다() 아래와 같은 방법:
파이썬3
newData.describe()> |
>
>
산출:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
다음 명령을 사용하여 모든 숫자 열에 대해 별도로 수행할 수도 있습니다.
파이썬3
newData[>'English'>].mean()> |
>
>
산출:
14.3>
다른 통계 정보도 해당 방법을 사용하여 계산할 수 있습니다. 엑셀과 마찬가지로 수식을 적용할 수도 있으며, 계산된 컬럼은 다음과 같이 생성할 수 있습니다.
파이썬3
Java에서 유형 변환 및 캐스팅
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
산출:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
데이터 프레임의 데이터에 대해 작업을 수행한 후 to_excel 메서드를 사용하여 데이터를 다시 Excel 파일로 내보낼 수 있습니다. 이를 위해 아래와 같이 변환된 데이터가 기록될 출력 Excel 파일을 지정해야 합니다.
파이썬3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
산출:
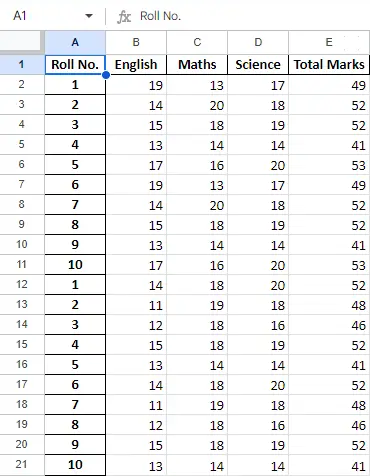
최종 시트