한 가지 중요한 측면 기계 학습 모델 평가입니다. 모델을 평가하려면 몇 가지 메커니즘이 필요합니다. 여기에서 이러한 성능 지표가 등장하여 모델이 얼마나 좋은지 알 수 있습니다. 기본적인 내용을 어느 정도 알고 계시다면 기계 학습 그런 다음 일반적으로 분류 작업에 사용되는 정확도, 정밀도, 재현율, auc-roc 등과 같은 일부 측정 항목을 접했을 것입니다. 이 기사에서는 이러한 측정항목 중 하나인 AUC-ROC 곡선을 자세히 살펴보겠습니다.
내용의 테이블
- AUC-ROC 곡선이란 무엇입니까?
- AUC 및 ROC 곡선에 사용되는 주요 용어
- 민감도, 특이도, FPR 및 임계값 간의 관계.
- AUC-ROC는 어떻게 작동하나요?
- AUC-ROC 평가 지표는 언제 사용해야 합니까?
- 모델의 성능 추측
- AUC-ROC 곡선 이해
- 두 가지 다른 모델을 사용한 구현
- 다중 클래스 모델에 ROC-AUC를 사용하는 방법은 무엇입니까?
- 기계 학습의 AUC ROC 곡선에 대한 FAQ
AUC-ROC 곡선이란 무엇입니까?
AUC-ROC 곡선(수신기 작동 특성 곡선 아래 영역)은 다양한 분류 임계값에서 이진 분류 모델의 성능을 그래픽으로 표현한 것입니다. 이는 두 가지 클래스, 일반적으로 양성 클래스(예: 질병의 존재)와 음성 클래스(예: 질병의 부재)를 구별하는 모델의 능력을 평가하기 위해 기계 학습에서 일반적으로 사용됩니다.
먼저 두 용어의 의미를 알아보겠습니다. 큰 괴조 그리고 AUC .
- 큰 괴조 : 수신기 작동 특성
- AUC : 곡선 아래 면적
ROC(수신기 작동 특성) 곡선
ROC는 Receiver Operating Characteristics의 약자이며 ROC 곡선은 이진 분류 모델의 효율성을 그래픽으로 표현한 것입니다. 다양한 분류 임계값에서 참양성률(TPR)과 거짓양성률(FPR)을 표시합니다.
곡선 아래 면적 (AUC) 곡선:
AUC는 Area Under the Curve를 의미하고, AUC 곡선은 ROC 곡선 아래의 면적을 나타냅니다. 이진 분류 모델의 전반적인 성능을 측정합니다. TPR과 FPR의 범위는 모두 0에서 1 사이이므로 영역은 항상 0과 1 사이에 위치하며 AUC 값이 클수록 모델 성능이 우수함을 나타냅니다. 우리의 주요 목표는 주어진 임계값에서 가장 높은 TPR과 가장 낮은 FPR을 갖기 위해 이 영역을 최대화하는 것입니다. AUC는 모델이 무작위로 선택한 긍정적인 사례에 무작위로 선택된 부정적인 사례에 비해 더 높은 예측 확률을 할당할 확률을 측정합니다.
그것은 개연성 이를 통해 우리 모델은 목표에 존재하는 두 클래스를 구별할 수 있습니다.
ROC-AUC 분류 평가 지표
AUC 및 ROC 곡선에 사용되는 주요 용어
1. TPR과 FPR
이는 AUC-ROC를 Google에서 검색할 때 접하게 되는 가장 일반적인 정의입니다. 기본적으로 ROC 곡선은 가능한 모든 임계값에서 분류 모델의 성능을 보여주는 그래프입니다(임계값은 특정 클래스에 속하는 포인트를 초과하는 특정 값입니다). 곡선은 두 매개변수 사이에 그려집니다.
- TPR – 진양성률
- FPR – 거짓양성률
이해하기 전에 TPR과 FPR에 대해 빠르게 살펴보겠습니다. 혼동 행렬 .
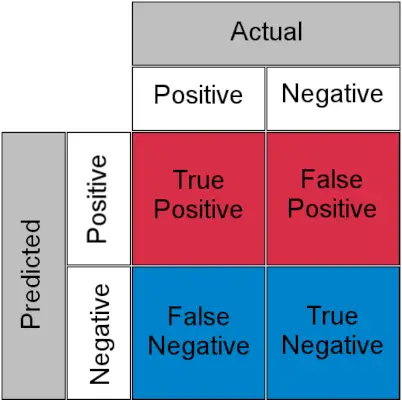
분류 작업에 대한 혼동 행렬
- 참양성 : 실제 양성 및 양성으로 예측
- 참음성 : 실제 음성 및 음성으로 예측
- 거짓양성(제1종 오류) : 실제는 음성이지만 양성으로 예측됨
- 거짓음성(제2종 오류) : 실제는 양성이지만 음성으로 예측됨
간단히 말해서 False Positive라고 부를 수 있습니다. 허위 경보 및 거짓 부정 놓치다 . 이제 TPR과 FPR이 무엇인지 살펴 보겠습니다.
2. 민감도 / 진양성률 / 재현율
기본적으로 TPR/Recall/Sensitivity는 올바르게 식별된 긍정적인 사례의 비율입니다. 이는 긍정적인 사례를 올바르게 식별하는 모델의 능력을 나타내며 다음과 같이 계산됩니다.

민감도/재현율/TPR은 모델에 의해 양성으로 올바르게 식별된 실제 양성 사례의 비율을 측정합니다.
3. 거짓양성률
FPR은 잘못 분류된 부정적인 사례의 비율입니다.

4. 특이성
특이성은 모델에 의해 부정적인 것으로 올바르게 식별되는 실제 부정적인 사례의 비율을 측정합니다. 부정적인 사례를 정확하게 식별하는 모델의 능력을 나타냅니다.

앞서 말했듯이 ROC는 가능한 모든 임계값에 걸쳐 TPR과 FPR 사이의 플롯일 뿐이며 AUC는 이 ROC 곡선 아래의 전체 영역입니다.
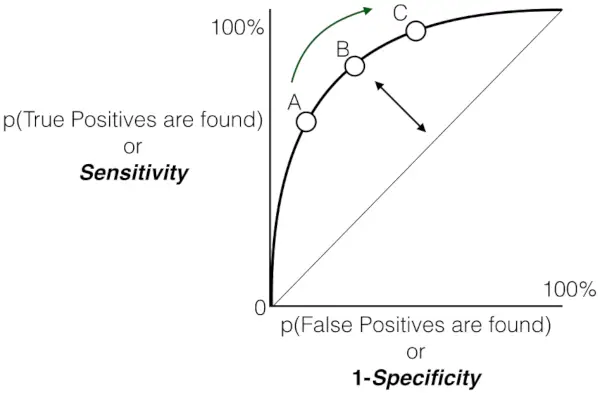
민감도 대 거짓 양성 비율 도표
민감도, 특이도, FPR 및 역치 간의 관계 .
민감도와 특이도:
- 반비례 관계: 민감도와 특이도는 반비례 관계에 있습니다. 하나가 증가하면 다른 하나는 감소하는 경향이 있습니다. 이는 참양성률과 참음성률 사이의 본질적인 상충 관계를 반영합니다.
- 임계값을 통한 조정: 임계값을 조정하여 민감도와 특이도 간의 균형을 제어할 수 있습니다. 임계값이 낮을수록 특이성(더 많은 위양성)이 희생되는 대신 더 높은 민감도(더 많은 참양성)가 발생합니다. 반대로, 임계값을 높이면 특이성이 높아지지만(거짓양성이 적음) 민감도가 저하됩니다(거짓음성이 많아짐).
임계값 및 FPR(거짓양성률):
- FPR 및 특이성 연결: 거짓양성률(FPR)은 단순히 특이성의 보완입니다(FPR = 1 – 특이성). 이는 둘 사이의 직접적인 관계를 의미합니다. 특이성이 높을수록 FPR이 낮아지고 그 반대의 경우도 마찬가지입니다.
- TPR을 통한 FPR 변경 사항: 마찬가지로, 관찰한 바와 같이 참양성률(TPR)과 FPR도 연결되어 있습니다. TPR(더 많은 참양성)이 증가하면 일반적으로 FPR(더 많은 거짓양성)이 증가합니다. 반대로, TPR이 낮아지면(진양성이 적음) FPR이 감소합니다(오탐성이 적음).
AUC-ROC는 어떻게 작동하나요?
기하학적인 해석을 살펴봤지만 0.75 AUC가 실제로 무엇을 의미하는지에 대한 직관을 발전시키기에는 아직 충분하지 않은 것 같습니다. 이제 확률론적 관점에서 AUC-ROC를 살펴보겠습니다. 먼저 AUC가 수행하는 작업에 대해 이야기하고 나중에 이에 대한 이해를 구축하겠습니다.
AUC는 모델이 다음을 얼마나 잘 구별할 수 있는지 측정합니다. 클래스.
AUC가 0.75라는 것은 실제로 별도의 클래스에 속하는 두 개의 데이터 포인트를 취한다고 가정하면 모델이 이를 분리하거나 올바르게 순위를 매길 수 있는 확률이 75%라는 것을 의미합니다. 즉, 긍정적인 포인트는 부정적인 것보다 예측 확률이 더 높습니다. 수업. (예측 확률이 높다고 가정하면 해당 포인트가 이상적으로 포지티브 클래스에 속한다는 의미입니다.) 다음은 상황을 더 명확하게 하기 위한 작은 예입니다.
색인 | 수업 | 개연성 |
|---|---|---|
P1 | 1 | 0.95 |
P2 | 1 | 0.90 |
P3 | 0 | 0.85 |
P4 | 0 | 0.81 |
P5 | 1 | 0.78 |
P6 | 0 | 0.70 |
여기에는 P1, P2, P5가 클래스 1에 속하고 P3, P4, P6이 클래스 0에 속하는 6개의 점이 있으며, 별도의 클래스에 속하는 두 점을 취하면 말했듯이 확률 열의 예측 확률에 해당합니다. 클래스가 모델 순위에 따라 올바르게 정렬될 확률은 얼마입니까?
한 포인트는 클래스 1에 속하고 다른 포인트는 클래스 0에 속하도록 가능한 모든 쌍을 취합니다. 아래에는 총 9개의 쌍이 있으며 이 9개의 가능한 쌍은 모두 있습니다.
쌍 | 맞다 |
|---|---|
(P1,P3) | 예 |
(P1,P4) | 예 |
(P1,P6) | 예 |
(P2,P3) | 예 |
(P2,P4) | 예 |
(P2,P6) | 예 |
(P3,P5) | 아니요 |
(P4,P5) | 아니요 |
(P5,P6) | 예 |
여기서 올바른 열은 언급된 쌍이 예측 확률을 기반으로 올바르게 순위가 지정되었는지 여부를 알려줍니다. 즉, 클래스 1 포인트가 클래스 0 포인트보다 확률이 높으며, 가능한 9개 쌍 중 7개에서 클래스 1이 클래스 0보다 높은 순위를 갖습니다. 별도의 클래스에 속하는 한 쌍의 점을 선택하면 모델이 이를 올바르게 구별할 수 있을 확률이 77%라고 말할 수 있습니다. 이제 이 AUC 수치 뒤에 약간의 직관이 있을 수 있다고 생각합니다. 추가 의심을 없애기 위해 Scikit 학습 AUC-ROC 구현을 사용하여 검증해 보겠습니다.
파이썬3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
산출:
AUC for our sample data is 0.778>
AUC-ROC 평가 지표는 언제 사용해야 합니까?
ROC-AUC를 사용하는 것이 이상적이지 않은 일부 영역이 있습니다. 데이터 세트의 불균형이 심한 경우 ROC 곡선은 모델 성능에 대해 지나치게 낙관적인 평가를 제공할 수 있습니다. . 이러한 낙관 편향은 실제 부정의 수가 많을 때 ROC 곡선의 거짓 긍정 비율(FPR)이 매우 작아질 수 있기 때문에 발생합니다.
FPR 공식을 살펴보면,

우리는 관찰한다 ,
- Negative 클래스는 다수에 속하며 FPR의 분모는 True Negatives에 의해 지배되므로 FPR은 소수 클래스(Positive 클래스)와 관련된 예측의 변화에 덜 민감해집니다.
- ROC 곡선은 거짓양성 및 거짓음성의 비용이 균형을 이루고 데이터세트의 불균형이 심하지 않은 경우에 적합할 수 있습니다.
그러한 경우, 정밀도-재현율 곡선 양성(소수) 클래스에 대한 분류기의 성능에 초점을 맞춰 불균형 데이터 세트에 더 적합한 대체 평가 메트릭을 제공하는 데 사용할 수 있습니다.
모델의 성능 추측
- 높은 AUC(1에 가까움)는 탁월한 식별력을 나타냅니다. 이는 모델이 두 클래스를 구별하는 데 효과적이며 예측이 신뢰할 수 있음을 의미합니다.
- 낮은 AUC(0에 가까움)는 성능이 좋지 않음을 나타냅니다. 이 경우 모델은 긍정적인 클래스와 부정적인 클래스를 구별하는 데 어려움을 겪으며 예측이 신뢰할 수 없을 수 있습니다.
- 0.5 부근의 AUC는 모델이 기본적으로 무작위 추측을 하고 있음을 의미합니다. 이는 클래스를 분리하는 기능이 없음을 보여 주며, 이는 모델이 데이터에서 의미 있는 패턴을 학습하지 않음을 나타냅니다.
AUC-ROC 곡선 이해
ROC 곡선에서 x축은 일반적으로 FPR(false positive rate)을 나타내고 y축은 민감도 또는 재현율이라고도 알려진 TPR(참양성률)을 나타냅니다. 따라서 ROC 곡선의 x축 값(오른쪽으로)이 높을수록 거짓 긍정률이 높고, y축 값(상단으로)이 높을수록 참양성률이 높아집니다. ROC 곡선은 그래픽입니다. 다양한 임계값에서 참양성률과 거짓양성률 사이의 균형을 표현합니다. 다양한 분류 임계값에서 분류 모델의 성능을 보여줍니다. AUC(곡선 아래 영역)는 ROC 곡선 성능의 요약 측정값입니다. 임계값 선택은 해결하려는 문제의 특정 요구 사항과 거짓 긍정과 거짓 부정 간의 균형에 따라 달라집니다. 귀하의 상황에 따라 허용됩니다.
- 거짓양성을 줄이는 데 우선순위를 두려면(긍정적이지 않은 항목에 라벨을 붙일 가능성을 최소화), 거짓양성률을 낮추는 임계값을 선택할 수 있습니다.
- 참양성 증가(가능한 한 많은 실제 양성 캡처)에 우선순위를 두려는 경우 참양성 비율이 더 높은 임계값을 선택할 수 있습니다.
다양한 ROC 곡선이 생성되는 방법을 설명하는 예를 살펴보겠습니다. 임계값 특정 임계값이 혼동 행렬과 어떻게 일치하는지. 우리가 이진 분류 문제 이메일이 스팸인지(긍정적) 스팸이 아닌지(부정적) 예측하는 모델을 사용합니다.
가상의 데이터를 생각해 보자.
실제 레이블: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
예측 확률: [0.8, 0.3, 0.6, 0.2, 0.7, 0.9, 0.4, 0.1, 0.75, 0.55]
사례 1: 임계값 = 0.5
진정한 라벨 | 예측 확률 | 예측된 라벨 |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
위의 예측을 기반으로 한 혼동 행렬
| 예측 = 0 | 예측 = 1 |
|---|---|---|
실제 = 0 | TP=4 | FN=1 |
실제 = 1 | FP=0 | 테네시=5 |
따라서,
- 참양성률(TPR) :
분류기에 의해 올바르게 식별된 실제 양성의 비율은 다음과 같습니다.

- 거짓양성률(FPR) :
실제 부정적인 내용이 긍정적인 내용으로 잘못 분류된 비율



따라서 임계값 0.5에서:
- 진양성률(민감도): 0.8
- 거짓양성률: 0
해석은 이 임계값에서 모델이 실제 양성(TPR)의 80%를 정확하게 식별하지만 실제 음성(FPR)의 0%를 양성으로 잘못 분류한다는 것입니다.
따라서 서로 다른 임계값에 대해 우리는 다음을 얻게 됩니다.
사례 2: 임계값 = 0.7
진정한 라벨 | 예측 확률 | 예측된 라벨 |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 0 |
위의 예측을 기반으로 한 혼동 행렬
| 예측 = 0 | 예측 = 1 |
|---|---|---|
실제 = 0 | TP=5 | FN=0 |
실제 = 1 | FP=2 | 테네시=3 |
따라서,
- 참양성률(TPR) :
분류기에 의해 올바르게 식별된 실제 양성의 비율은 다음과 같습니다.

- 거짓양성률(FPR) :
실제 부정적인 내용이 긍정적인 내용으로 잘못 분류된 비율



사례 3: 임계값 = 0.4
진정한 라벨 | 예측 확률 | 예측된 라벨 |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
위의 예측을 기반으로 한 혼동 행렬
| 예측 = 0 | 예측 = 1 |
|---|---|---|
실제 = 0 | TP=4 | FN=1 |
실제 = 1 | FP=0 | 테네시=5 |
따라서,
- 참양성률(TPR) :
분류기에 의해 올바르게 식별된 실제 양성의 비율은 다음과 같습니다.
- 거짓양성률(FPR) :
실제 부정적인 내용이 긍정적인 내용으로 잘못 분류된 비율
사례 4: 임계값 = 0.2
진정한 라벨 | 예측 확률 | 예측된 라벨 |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 1 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 1 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
위의 예측을 기반으로 한 혼동 행렬
| 예측 = 0 | 예측 = 1 |
|---|---|---|
실제 = 0 | TP=2 | FN=3 |
실제 = 1 | FP=0 마우스 스크롤이 작동하지 않습니다 | 테네시=5 |
따라서,
- 참양성률(TPR) :
분류기에 의해 올바르게 식별된 실제 양성의 비율은 다음과 같습니다.

- 거짓양성률(FPR) :
실제 부정적인 내용이 긍정적인 내용으로 잘못 분류된 비율

사례 5: 임계값 = 0.85
진정한 라벨 | 예측 확률 | 예측된 라벨 |
|---|---|---|
| 1 | 0.8 | 0 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 0 |
| 0 | 0.55 | 0 |
위의 예측을 기반으로 한 혼동 행렬
| 예측 = 0 | 예측 = 1 |
|---|---|---|
실제 = 0 | TP=5 | FN=0 |
실제 = 1 | FP=4 | 테네시=1 |
따라서,
- 참양성률(TPR) :
분류기에 의해 올바르게 식별된 실제 양성의 비율은 다음과 같습니다.
- 거짓양성률(FPR) :
실제 부정적인 내용이 긍정적인 내용으로 잘못 분류된 비율


위의 결과를 바탕으로 ROC 곡선을 그려보겠습니다.
파이썬3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
산출:
그래프에서 다음과 같이 암시됩니다.
- 회색 점선은 모델의 예측, 즉 TPR이 FPR과 동일한 최악의 시나리오를 나타냅니다. 이 대각선은 최악의 시나리오로 간주되며, 긍정 오류와 부정 오류의 가능성이 동일함을 나타냅니다.
- 점이 무작위 추측선에서 벗어나 왼쪽 상단으로 갈수록 모델의 성능이 향상됩니다.
- AUC(곡선 아래 면적)는 모델의 판별 능력을 정량적으로 측정한 것입니다. AUC 값이 1.0에 가까울수록 성능이 우수함을 나타냅니다. 가능한 최상의 AUC 값은 1.0이며, 이는 100% 민감도와 100% 특이도를 달성하는 모델에 해당합니다.
전체적으로 ROC(수신자 작동 특성) 곡선은 다양한 결정 임계값에서 이진 분류 모델의 참양성률(민감도)과 거짓양성률 간의 균형을 그래픽으로 표현하는 역할을 합니다. 곡선이 왼쪽 위 모서리를 향해 우아하게 상승함에 따라 신뢰도 임계값 범위에서 긍정적인 사례와 부정적인 사례를 구별하는 모델의 훌륭한 능력을 나타냅니다. 이러한 상승 궤적은 오탐을 최소화하면서 더 높은 민감도를 달성하여 성능이 향상되었음을 나타냅니다. A, B, C, D 및 E로 표시된 주석이 달린 임계값은 다양한 신뢰 수준에서 모델의 동적 동작에 대한 귀중한 통찰력을 제공합니다.
두 가지 다른 모델을 사용한 구현
라이브러리 설치
파이썬3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
훈련시키기 위해서는 랜덤 포레스트 그리고 로지스틱 회귀 모델을 사용하고 ROC 곡선을 AUC 점수로 표시하기 위해 알고리즘은 인공 이진 분류 데이터를 생성합니다.
데이터 생성 및 데이터 분할
파이썬3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
80-20 분할 비율을 사용하여 알고리즘은 20개의 기능이 포함된 인공 이진 분류 데이터를 생성하고 이를 훈련 세트와 테스트 세트로 나누고 재현성을 보장하기 위해 무작위 시드를 할당합니다.
다양한 모델 훈련
파이썬3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
반복성을 보장하기 위해 고정된 무작위 시드를 사용하여 이 방법은 훈련 세트에서 로지스틱 회귀 모델을 초기화하고 훈련합니다. 비슷한 방식으로 훈련 데이터와 동일한 무작위 시드를 사용하여 100개의 나무가 있는 Random Forest 모델을 초기화하고 훈련합니다.
예측
파이썬3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
테스트 데이터와 훈련된 데이터를 사용하여 로지스틱 회귀 모델에서 코드는 양성 클래스의 확률을 예측합니다. 비슷한 방식으로 테스트 데이터를 사용하여 훈련된 Random Forest 모델을 사용하여 양성 클래스에 대한 예상 확률을 생성합니다.
데이터프레임 생성
파이썬3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
테스트 데이터를 사용하여 코드는 True, Logistic 및 RandomForest라는 레이블이 붙은 열이 있는 test_df라는 DataFrame을 생성하고 Random Forest 및 Logistic Regression 모델의 실제 레이블과 예측 확률을 추가합니다.
모델에 대한 ROC 곡선 그리기
파이썬3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
산출:

코드는 8 x 6인치 그림으로 플롯을 생성합니다. 각 모델(Random Forest 및 Logistic Regression)에 대한 AUC 및 ROC 곡선을 계산한 다음 ROC 곡선을 그립니다. 그만큼 ROC 곡선 무작위 추측을 위한 경우에도 빨간색 점선으로 표시되며 시각화를 위해 레이블, 제목, 범례가 설정됩니다.
다중 클래스 모델에 ROC-AUC를 사용하는 방법은 무엇입니까?
다중 클래스 설정의 경우 간단히 일대다 방법론을 사용할 수 있으며 각 클래스에 대해 하나의 ROC 곡선을 갖게 됩니다. 4개의 클래스 A, B, C, D가 있다고 가정하면 4개 클래스 모두에 대한 ROC 곡선과 해당 AUC 값이 있습니다. 즉, A가 하나의 클래스가 되고 B, C, D를 결합하면 다른 클래스가 됩니다. 마찬가지로 B는 하나의 클래스이고 A, C, D가 결합되어 다른 클래스가 되는 식입니다.
다중클래스 분류 모델의 맥락에서 AUC-ROC를 사용하는 일반적인 단계는 다음과 같습니다.
일대다 방법론:
- 멀티클래스 문제의 각 클래스에 대해 이를 포지티브 클래스로 처리하고 다른 모든 클래스를 네거티브 클래스로 결합합니다.
- 나머지 클래스에 대해 각 클래스의 이진 분류기를 훈련합니다.
각 클래스에 대한 AUC-ROC를 계산합니다.
- 여기서는 나머지 클래스에 대해 특정 클래스에 대한 ROC 곡선을 그립니다.
- 동일한 그래프에 각 클래스에 대한 ROC 곡선을 그립니다. 각 곡선은 특정 클래스에 대한 모델의 판별 성능을 나타냅니다.
- 각 클래스의 AUC 점수를 검사합니다. AUC 점수가 높을수록 해당 특정 클래스에 대한 차별이 더 우수함을 나타냅니다.
다중클래스 분류에서 AUC-ROC 구현
라이브러리 가져오기
파이썬3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
프로그램은 인공적인 멀티클래스 데이터를 생성하고 이를 훈련 세트와 테스트 세트로 나눈 다음 One-vs-Rest 분류기 Random Forest와 Logistic Regression에 대한 분류기를 훈련하는 기술입니다. 마지막으로 두 모델의 다중 클래스 ROC 곡선을 플롯하여 다양한 클래스를 얼마나 잘 구별하는지 보여줍니다.
데이터 생성 및 분할
파이썬3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
3개의 클래스와 20개의 기능이 코드에 의해 생성된 합성 멀티클래스 데이터를 구성합니다. 레이블 이진화 후 데이터는 80-20 비율로 훈련 세트와 테스트 세트로 나뉩니다.
훈련 모델
파이썬3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
이 프로그램은 두 가지 멀티클래스 모델을 학습합니다. 하나는 100개의 추정기를 사용하는 Random Forest 모델이고 다른 하나는 로지스틱 회귀 모델입니다. One-vs-Rest 접근 방식 . 훈련 데이터 세트를 사용하면 두 모델이 모두 적합합니다.
AUC-ROC 곡선 그리기
파이썬3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
산출:

Random Forest 및 Logistic Regression 모델의 ROC 곡선과 AUC 점수는 각 클래스의 코드로 계산됩니다. 그런 다음 다중 클래스 ROC 곡선이 그려져 각 클래스의 판별 성능을 보여주고 무작위 추측을 나타내는 선이 표시됩니다. 결과 플롯은 모델의 분류 성능에 대한 그래픽 평가를 제공합니다.
결론
기계 학습에서 이진 분류 모델의 성능은 AUC-ROC(수신기 작동 특성 아래 영역)라는 중요한 측정항목을 사용하여 평가됩니다. 다양한 결정 임계값에 걸쳐 민감도와 특이도가 어떻게 균형을 이루는지 보여줍니다. 일반적으로 AUC 점수가 높은 모델에서는 긍정적인 인스턴스와 부정적인 인스턴스 간의 더 큰 차별이 나타납니다. 0.5는 우연을 나타내고, 1은 완벽한 성능을 나타냅니다. 모델 최적화 및 선택은 AUC-ROC 곡선이 클래스 간 구별을 위한 모델의 능력에 대해 제공하는 유용한 정보의 도움을 받습니다. 거짓 긍정과 거짓 부정의 비용이 서로 다른 불균형 데이터 세트나 애플리케이션으로 작업할 때 이는 포괄적인 측정으로 특히 유용합니다.
기계 학습의 AUC ROC 곡선에 대한 FAQ
1. AUC-ROC 곡선이란 무엇입니까?
다양한 분류 임계값에 대해 진양성률(민감도)과 위양성률(특이성) 간의 균형은 AUC-ROC 곡선으로 그래픽으로 표시됩니다.
2. 완벽한 AUC-ROC 곡선은 어떤 모습인가요?
이상적인 AUC-ROC 곡선의 영역이 1이면 모델이 모든 임계값에서 최적의 민감도와 특이도를 달성한다는 의미입니다.
3. AUC 값 0.5는 무엇을 의미합니까?
AUC 0.5는 모델의 성능이 무작위 확률의 성능과 유사함을 나타냅니다. 분별력이 부족하다는 뜻이다.
4. AUC-ROC를 다중 클래스 분류에 사용할 수 있습니까?
AUC-ROC는 이진 분류와 관련된 문제에 자주 적용됩니다. 다중 클래스 분류를 위해 거시 평균 또는 미시 평균 AUC와 같은 변형을 고려할 수 있습니다.
5. AUC-ROC 곡선은 모델 평가에 어떻게 유용합니까?
클래스를 구별하는 모델의 능력은 AUC-ROC 곡선으로 종합적으로 요약됩니다. 불균형 데이터 세트로 작업할 때 특히 유용합니다.