로지스틱 회귀 는 지도 기계 학습 알고리즘 사용 분류 작업 여기서 목표는 인스턴스가 특정 클래스에 속할 확률을 예측하는 것입니다. 로지스틱 회귀는 두 가지 데이터 요소 간의 관계를 분석하는 통계 알고리즘입니다. 이 기사에서는 로지스틱 회귀의 기본 사항, 유형 및 구현을 살펴봅니다.
내용의 테이블
- 로지스틱 회귀란 무엇입니까?
- 로지스틱 함수 - 시그모이드 함수
- 로지스틱 회귀 유형
- 로지스틱 회귀의 가정
- 로지스틱 회귀는 어떻게 작동하나요?
- 로지스틱 회귀를 위한 코드 구현
- 로지스틱 회귀 임계값 설정의 정밀-재현율 절충
- 로지스틱 회귀 모델을 평가하는 방법은 무엇입니까?
- 선형 회귀와 로지스틱 회귀의 차이점
로지스틱 회귀란 무엇입니까?
로지스틱 회귀는 이진수에 사용됩니다. 분류 우리가 사용하는 곳 시그모이드 함수 , 이는 입력을 독립 변수로 취하고 0과 1 사이의 확률 값을 생성합니다.
예를 들어, 입력에 대한 로지스틱 함수의 값이 0.5(임계값)보다 크면 클래스 0과 클래스 1의 두 클래스가 있으며, 그렇지 않으면 클래스 0에 속합니다. 이를 회귀라고 합니다. 의 확장이다 선형 회귀 주로 분류 문제에 사용됩니다.
키 포인트:
- 로지스틱 회귀는 범주형 종속 변수의 출력을 예측합니다. 따라서 결과는 범주형 또는 이산형 값이어야 합니다.
- 예 또는 아니요, 0 또는 1, 참 또는 거짓 등이 될 수 있지만 0과 1이라는 정확한 값을 제공하는 대신 0과 1 사이에 있는 확률적 값을 제공합니다.
- 로지스틱 회귀에서는 회귀선을 맞추는 대신 두 개의 최대값(0 또는 1)을 예측하는 S 모양의 로지스틱 함수를 맞춥니다.
로지스틱 함수 - 시그모이드 함수
- 시그모이드 함수는 예측된 값을 확률에 매핑하는 데 사용되는 수학 함수입니다.
- 실제 값을 0과 1 범위 내의 다른 값으로 매핑합니다. 로지스틱 회귀의 값은 0과 1 사이여야 하며 이 한계를 넘을 수 없으므로 S 형태와 같은 곡선을 형성합니다.
- S형 곡선을 시그모이드 함수 또는 로지스틱 함수라고 합니다.
- 로지스틱 회귀에서는 0 또는 1의 확률을 정의하는 임계값 개념을 사용합니다. 예를 들어 임계값보다 높은 값은 1로 경향이 있고 임계값보다 낮은 값은 0으로 경향이 있습니다.
로지스틱 회귀 유형
범주에 따라 로지스틱 회귀는 세 가지 유형으로 분류될 수 있습니다.
- 이항식: 이항 로지스틱 회귀 분석에서는 0 또는 1, 합격 또는 실패 등 두 가지 유형의 종속 변수만 있을 수 있습니다.
- 다항식: 다항 로지스틱 회귀 분석에서는 고양이, 개, 양과 같이 순서가 지정되지 않은 종속 변수 유형이 3개 이상 있을 수 있습니다.
- 서수: 순서형 로지스틱 회귀 분석에서는 낮음, 중간, 높음과 같은 3개 이상의 정렬된 종속 변수 유형이 있을 수 있습니다.
로지스틱 회귀의 가정
모델을 적절하게 적용하려면 이러한 가정을 이해하는 것이 중요하므로 로지스틱 회귀의 가정을 살펴보겠습니다. 가정에는 다음이 포함됩니다.
- 독립적인 관찰: 각 관찰은 서로 독립적입니다. 이는 입력 변수 간에 상관 관계가 없음을 의미합니다.
- 이진 종속 변수: 종속 변수가 이진 또는 이분형이어야 한다는 가정을 사용합니다. 즉, 두 개의 값만 사용할 수 있습니다. 두 개 이상의 범주에는 SoftMax 기능이 사용됩니다.
- 독립변수와 로그 승산 간의 선형 관계: 독립 변수와 종속변수의 로그 승산 간의 관계는 선형이어야 합니다.
- 이상값 없음: 데이터세트에 이상값이 없어야 합니다.
- 큰 표본 크기: 표본 크기가 충분히 큽니다.
로지스틱 회귀와 관련된 용어
다음은 로지스틱 회귀와 관련된 몇 가지 일반적인 용어입니다.
- 독립 변수: 종속변수의 예측에 적용되는 입력 특성 또는 예측 요인입니다.
- 종속변수: 예측하려는 로지스틱 회귀 모델의 목표 변수입니다.
- 물류 기능: 독립 변수와 종속 변수가 서로 어떻게 관련되어 있는지 나타내는 데 사용되는 공식입니다. 로지스틱 함수는 입력 변수를 0과 1 사이의 확률 값으로 변환합니다. 이는 종속 변수가 1 또는 0일 가능성을 나타냅니다.
- 승산: 일어나는 일과 일어나지 않는 일의 비율입니다. 확률은 발생할 수 있는 모든 일에 대한 발생하는 일의 비율이므로 확률과 다릅니다.
- 로그 확률: 로짓 함수라고도 알려진 로그 확률은 확률의 자연 로그입니다. 로지스틱 회귀 분석에서 종속 변수의 로그 확률은 독립 변수와 절편의 선형 조합으로 모델링됩니다.
- 계수: 로지스틱 회귀 모델의 추정 매개변수는 독립 변수와 종속 변수가 서로 어떻게 관련되어 있는지 보여줍니다.
- 가로채기: 모든 독립 변수가 0일 때 로그 확률을 나타내는 로지스틱 회귀 모델의 상수 항입니다.
- 최대 우도 추정 : 로지스틱 회귀 모델의 계수를 추정하는 데 사용되는 방법으로, 모델이 주어진 데이터를 관찰할 가능성을 최대화합니다.
로지스틱 회귀는 어떻게 작동하나요?
로지스틱 회귀 모델은 선형 회귀 함수 연속 값 출력을 시그모이드 함수를 사용하여 범주형 값 출력으로 변환합니다. 이 함수는 입력된 독립 변수의 실수 값 집합을 0과 1 사이의 값으로 매핑합니다. 이 함수를 로지스틱 함수라고 합니다.
독립적인 입력 기능은 다음과 같습니다.
자바 코딩 if else 문
종속 변수는 이진수 값, 즉 0 또는 1만 갖는 Y입니다.
그런 다음 다중 선형 함수를 입력 변수 X에 적용합니다.
여기
우리가 위에서 논의한 것은 무엇이든 선형 회귀 .
시그모이드 함수
이제 우리는 시그모이드 함수 여기서 입력은 z이고 0과 1 사이의 확률, 즉 예측된 y를 찾습니다.
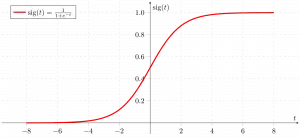
시그모이드 함수
위 그림과 같이 그림 시그모이드 함수는 연속변수 데이터를 다음과 같은 형태로 변환합니다. 개연성 즉, 0과 1 사이입니다.
sigma(z) 1을 향하는 경향이 있다z ightarrowinfty sigma(z) 0에 가까워지는 경향이 있다z ightarrow-infty sigma(z) 항상 0과 1 사이의 경계를 가지고 있습니다.
클래스가 될 확률은 다음과 같이 측정할 수 있습니다.
로지스틱 회귀 방정식
이상한 점은 발생하는 일과 발생하지 않는 일의 비율입니다. 확률은 발생할 수 있는 모든 일에 대한 발생하는 일의 비율이므로 확률과 다릅니다. 정말 이상한 일이 될 것입니다 :
빠른 정렬 자바
홀수에 자연로그를 적용합니다. 그러면 로그 홀수는 다음과 같습니다.
최종 로지스틱 회귀 방정식은 다음과 같습니다.
로지스틱 회귀 분석의 우도 함수
예상 확률은 다음과 같습니다.
- y=1인 경우 예측 확률은 다음과 같습니다. p(X;b,w) = p(x)
- y = 0인 경우 예측 확률은 다음과 같습니다. 1-p(X;b,w) = 1-p(x)
자바 정렬 목록
양쪽에 자연로그를 취함
로그 우도 함수의 기울기
최대 가능성 추정치를 찾기 위해 w.r.t w를 차별화합니다.
로지스틱 회귀를 위한 코드 구현
이항 로지스틱 회귀:
대상 변수에는 2가지 가능한 유형만 있을 수 있습니다. 0 또는 1은 승리 대 손실, 통과 대 실패, 데드 대 살아 있음 등을 나타낼 수 있습니다. 이 경우 이미 위에서 설명한 시그모이드 함수가 사용됩니다.
모델 요구 사항에 따라 필요한 라이브러리를 가져옵니다. 이 Python 코드는 유방암 데이터 세트를 사용하여 분류를 위한 로지스틱 회귀 모델을 구현하는 방법을 보여줍니다.
파이썬3 # import the necessary libraries from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # load the breast cancer dataset X, y = load_breast_cancer(return_X_y=True) # split the train and test dataset X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=23) # LogisticRegression clf = LogisticRegression(random_state=0) clf.fit(X_train, y_train) # Prediction y_pred = clf.predict(X_test) acc = accuracy_score(y_test, y_pred) print('Logistic Regression model accuracy (in %):', acc*100)> 산출 :
로지스틱 회귀 모델 정확도(%): 95.6140350877193
다항 로지스틱 회귀:
대상 변수는 질병 A 대 질병 B 대 질병 C와 같이 순서가 지정되지 않은(즉, 유형에 양적 중요성이 없는) 3개 이상의 가능한 유형을 가질 수 있습니다.
이 경우 Sigmoid 함수 대신 Softmax 함수가 사용됩니다. 소프트맥스 기능 K 클래스의 경우 다음과 같습니다.
여기, 케이 는 벡터 z의 요소 수를 나타내며, i, j는 벡터의 모든 요소를 반복합니다.
그러면 클래스 c의 확률은 다음과 같습니다.
다항 로지스틱 회귀 분석에서 출력 변수는 다음을 가질 수 있습니다. 2개 이상의 개별 출력 가능 . 숫자 데이터세트를 고려해보세요.
파이썬3 from sklearn.model_selection import train_test_split from sklearn import datasets, linear_model, metrics # load the digit dataset digits = datasets.load_digits() # defining feature matrix(X) and response vector(y) X = digits.data y = digits.target # splitting X and y into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1) # create logistic regression object reg = linear_model.LogisticRegression() # train the model using the training sets reg.fit(X_train, y_train) # making predictions on the testing set y_pred = reg.predict(X_test) # comparing actual response values (y_test) # with predicted response values (y_pred) print('Logistic Regression model accuracy(in %):', metrics.accuracy_score(y_test, y_pred)*100)> 산출:
로지스틱 회귀 모델 정확도(%): 96.52294853963839
로지스틱 회귀 모델을 평가하는 방법은 무엇입니까?
다음 측정항목을 사용하여 로지스틱 회귀 모델을 평가할 수 있습니다.
- 정확성: 정확성 올바르게 분류된 인스턴스의 비율을 제공합니다.
Accuracy = frac{True , Positives + True , Negatives}{Total}
- 정도: 정도 긍정적인 예측의 정확성에 중점을 둡니다.
Precision = frac{True , Positives }{True, Positives + False , Positives}
- 재현율(민감도 또는 참양성률): 상기하다 모든 실제 긍정적 사례 중에서 올바르게 예측된 긍정적 사례의 비율을 측정합니다.
Recall = frac{ True , Positives}{True, Positives + False , Negatives}
- F1 점수: F1 점수 정밀도와 재현율의 조화 평균입니다.
F1 , Score = 2 * frac{Precision * Recall}{Precision + Recall}
- 수신기 작동 특성 곡선(AUC-ROC) 아래 영역: ROC 곡선은 다양한 임계값에서 거짓 긍정 비율에 대한 참 긍정 비율을 표시합니다. AUC-ROC 이 곡선 아래의 면적을 측정하여 다양한 분류 임계값에 걸쳐 모델 성능에 대한 집계 측정값을 제공합니다.
- 정밀도-재현율 곡선 아래 영역(AUC-PR): AUC-ROC와 유사합니다. AUC-PR 정밀도-재현율 곡선 아래 영역을 측정하여 다양한 정밀도-재현율 절충에 대한 모델 성능 요약을 제공합니다.
로지스틱 회귀 임계값 설정의 정밀-재현율 절충
로지스틱 회귀는 결정 임계값이 포함된 경우에만 분류 기술이 됩니다. 임계값 설정은 로지스틱 회귀 분석의 매우 중요한 측면이며 분류 문제 자체에 따라 달라집니다.
임계값의 결정은 다음 값에 의해 크게 영향을 받습니다. 정밀도와 리콜. 이상적으로는 정밀도와 재현율이 모두 1이 되기를 원하지만 그런 경우는 거의 없습니다.
의 경우 정밀-재현율 절충 , 임계값을 결정하기 위해 다음 인수를 사용합니다.
- 낮은 정밀도/높은 재현율: 위양성 수를 반드시 줄이지 않고 위음성 수를 줄이려는 애플리케이션에서는 정밀도 값이 낮거나 재현율 값이 높은 결정 값을 선택합니다. 예를 들어, 암 진단 애플리케이션에서 우리는 환자가 암으로 잘못 진단되는 경우 많은 주의를 기울이지 않고 영향을 받은 환자가 영향을 받지 않은 것으로 분류되는 것을 원하지 않습니다. 이는 암의 부재는 추가적인 의학적 질병에 의해 검출될 수 있지만, 이미 거부된 후보자에서는 질병의 존재를 검출할 수 없기 때문이다.
- 높은 정밀도/낮은 재현율: 위음성 수를 반드시 줄이지 않고 위양성 수를 줄이려는 애플리케이션에서는 정밀도 값이 높거나 재현율 값이 낮은 결정 값을 선택합니다. 예를 들어, 고객이 개인화된 광고에 긍정적으로 반응할지 부정적으로 반응할지 분류하는 경우 고객이 광고에 긍정적으로 반응할지 절대적으로 확신해야 합니다. 그렇지 않으면 부정적인 반응으로 인해 잠재 매출 손실이 발생할 수 있기 때문입니다. 고객.
선형 회귀와 로지스틱 회귀의 차이점
선형 회귀와 로지스틱 회귀의 차이점은 선형 회귀 출력은 무엇이든 될 수 있는 연속 값인 반면 로지스틱 회귀는 인스턴스가 주어진 클래스에 속할 확률을 예측한다는 것입니다.
aes 대 des
선형 회귀 | 로지스틱 회귀 |
|---|---|
선형 회귀는 주어진 독립 변수 세트를 사용하여 연속 종속 변수를 예측하는 데 사용됩니다. | 로지스틱 회귀는 주어진 독립 변수 세트를 사용하여 범주형 종속 변수를 예측하는 데 사용됩니다. |
회귀 문제를 해결하기 위해 선형 회귀가 사용됩니다. | 분류 문제를 해결하는 데 사용됩니다. |
여기서 우리는 연속 변수의 값을 예측합니다. | 여기서 우리는 범주형 변수의 값을 예측합니다. |
이것에서 우리는 가장 적합한 선을 찾습니다. | 여기에 S-곡선이 있습니다. |
정확도를 추정하기 위해 최소제곱 추정법을 사용합니다. | 정확도 추정에는 최대 우도 추정 방법이 사용됩니다. |
출력은 가격, 연령 등과 같은 연속 값이어야 합니다. | 출력은 0 또는 1, 예 또는 아니요 등과 같은 범주형 값이어야 합니다. 날짜를 문자열로 변환 |
종속변수와 독립변수 사이의 선형 관계가 필요했습니다. | 선형 관계가 필요하지 않습니다. |
독립변수 사이에는 공선성이 있을 수 있습니다. | 독립변수 사이에는 공선성이 없어야 합니다. |
로지스틱 회귀 – 자주 묻는 질문(FAQ)
기계 학습의 로지스틱 회귀란 무엇입니까?
로지스틱 회귀는 이진 종속 변수, 즉 이진을 사용하여 기계 학습 모델을 개발하기 위한 통계 방법입니다. 로지스틱 회귀는 데이터와 하나의 종속 변수와 하나 이상의 독립 변수 간의 관계를 설명하는 데 사용되는 통계 기법입니다.
로지스틱 회귀의 세 가지 유형은 무엇입니까?
로지스틱 회귀는 이항형, 다항형, 순서형의 세 가지 유형으로 분류됩니다. 그들은 이론뿐만 아니라 실행도 다릅니다. 이진 회귀는 예 또는 아니오라는 두 가지 가능한 결과와 관련됩니다. 다항 로지스틱 회귀는 값이 3개 이상일 때 사용됩니다.
분류 문제에 로지스틱 회귀가 사용되는 이유는 무엇입니까?
로지스틱 회귀는 구현, 해석, 학습이 더 쉽습니다. 알려지지 않은 기록을 매우 빠르게 분류합니다. 데이터 세트가 선형으로 분리 가능하면 성능이 좋습니다. 모델 계수는 특성 중요도의 지표로 해석될 수 있습니다.
로지스틱 회귀와 선형 회귀의 차이점은 무엇입니까?
선형 회귀는 지속적인 결과를 예측하는 데 사용되는 반면, 로지스틱 회귀는 관찰이 특정 범주에 속할 가능성을 예측하는 데 사용됩니다. 로지스틱 회귀는 S자 모양의 로지스틱 함수를 사용하여 0과 1 사이의 예측 값을 매핑합니다.
로지스틱 회귀 분석에서 로지스틱 함수는 어떤 역할을 합니까?
로지스틱 회귀는 로지스틱 함수를 사용하여 출력을 확률 점수로 변환합니다. 이 점수는 관측치가 특정 클래스에 속할 확률을 나타냅니다. S자형 곡선은 데이터를 이진 결과로 임계값을 지정하고 분류하는 데 도움이 됩니다.