다음 튜토리얼에서는 B Tree 데이터 구조에 대해 배우고 시각화하는 것을 고려해 보겠습니다.
이제 시작하겠습니다.
B 트리란 무엇입니까?
그만큼 B 트리 는 특별한 유형의 다방향 탐색 트리 , 일반적으로 M-웨이 스스로 균형을 유지하는 나무. 균형 잡힌 구조로 인해 이러한 트리는 일반적으로 거대한 데이터베이스를 운영 및 관리하고 검색을 단순화하는 데 사용됩니다. B 트리에서 각 노드는 최대 n개의 하위 노드를 가질 수 있습니다. B 트리는 데이터베이스 관리 시스템(DBMS)의 다중 레벨 인덱싱의 예입니다. 리프 및 내부 노드에는 모두 레코드 참조가 있습니다. B 트리는 모든 리프 노드가 동일한 수준에 있기 때문에 균형 저장 트리(Balanced Stored Tree)로 알려져 있습니다.
다음 다이어그램은 B 트리의 예입니다.
그림 1. 차수가 3인 A B 트리
B 트리의 규칙 이해
B 트리의 중요한 속성은 다음과 같습니다.
- 모든 리프 노드는 동일한 수준에 있습니다.
- B 트리 데이터 구조는 최소 차수 'd'라는 용어로 정의됩니다. 'd' 값은 디스크 블록의 크기에 따라 달라집니다.
- 루트를 제외한 모든 노드는 최소한 d-1개의 키로 구성되어야 합니다. 루트 노드는 최소 1개의 키로 구성될 수 있습니다.
- 모든 노드(루트 노드 포함)는 최대로 구성될 수 있습니다. (2d-1) 열쇠.
- 노드의 자식 수는 다음과 같습니다. 그 안에 존재하는 키 수를 추가하고 .
- 노드의 모든 키는 오름차순으로 정렬됩니다. 두 키 k1과 k2 사이의 하위 키는 각각 k1과 k2 사이의 모든 키로 구성됩니다.
- 이진 검색 트리와 달리 B 트리 데이터 구조는 루트에서 커지거나 작아집니다. 반면 이진 검색 트리는 아래로 성장하고 아래로 축소됩니다.
- 다른 자체 균형 이진 검색 트리와 유사하게 검색, 삽입 및 삭제와 같은 작업에 대한 B 트리 데이터 구조의 시간 복잡도는 다음과 같습니다. O(로그?n) .
- B 트리에 노드 삽입은 리프 노드에서만 발생합니다.
최소 차수가 5인 B 트리의 다음 예를 고려해 보겠습니다.

그림 2. A B 차수 5의 트리
참고: 실제 B 트리에서는 최소 차수의 값이 5보다 훨씬 큽니다.
위 다이어그램에서 우리는 모든 리프 노드가 동일한 레벨에 있고 리프가 아닌 모든 노드에는 빈 하위 트리가 없으며 하위 노드 수보다 하나 적은 키로 구성된다는 것을 알 수 있습니다.
B 트리 규칙의 집합 공식화:
모든 B 트리는 다음과 같이 알려진 양의 상수 정수에 의존합니다. 최저한의 이는 단일 노드에 보관할 수 있는 데이터 요소의 수를 결정하는 데 사용됩니다.
자바 교체
규칙 1: 루트에는 데이터 요소가 하나만 있을 수 있습니다(또는 자식 요소가 없는 경우 데이터 요소가 없을 수도 있음). 다른 모든 노드에는 최소한 최저한의 데이터 요소.
규칙 2: 노드에 저장되는 데이터 요소의 최대 개수는 다음 값의 두 배입니다. 최저한의 .
규칙 3: B 트리의 각 노드의 데이터 요소는 부분적으로 채워진 배열에 저장되며 가장 작은 데이터 요소(인덱스)부터 정렬됩니다. 0 )를 가장 큰 데이터 요소(어레이의 최종 활용 위치)로 복사합니다.
규칙 4: 리프가 아닌 노드 아래의 하위 트리의 총 수는 항상 해당 노드의 데이터 요소 수보다 1개 더 많습니다.
- 하위 트리 0,하위 트리 1,...
규칙 5: 리프가 아닌 노드와 관련하여:
- 인덱스의 데이터 요소가 하위 트리 번호의 모든 데이터 요소보다 큽니다. 나 노드의
- 인덱스의 데이터 요소는 하위 트리 번호의 모든 데이터 요소보다 작습니다. 나+1 노드의.
규칙 6: B 트리의 모든 리프는 동일한 깊이를 갖습니다. 따라서 B 트리는 불균형 트리 문제를 방지합니다.
B 트리 데이터 구조에 대한 작업
작업 중에 B 트리 데이터 구조의 속성 중 어느 것도 위반되지 않도록 하기 위해 B 트리를 분할하거나 결합할 수 있습니다. 다음은 B 트리에서 수행할 수 있는 몇 가지 작업입니다.
- B 트리에서 데이터 요소 검색
- B 트리에 데이터 요소 삽입
- B 트리의 데이터 요소 삭제
B 트리에서 검색 작업
B 트리의 요소 검색은 이진 검색 트리의 요소 검색과 유사합니다. 그러나 이진 검색 트리처럼 양방향 결정(왼쪽 또는 오른쪽)을 내리는 대신 B 트리는 각 노드에서 m방향 결정을 내립니다. 여기서 m은 노드의 자식 수입니다.
B 트리에서 데이터 요소를 검색하는 단계:
1 단계: 검색은 루트 노드부터 시작됩니다. 검색 요소 k를 루트와 비교합니다.
1.1단계: 루트 노드가 k 요소로 구성되면 검색이 완료됩니다.
1.2단계: k 요소가 루트의 첫 번째 값보다 작으면 가장 왼쪽 자식으로 이동하여 재귀적으로 자식을 검색합니다.
1.3.1단계: 루트에 자식이 두 개만 있으면 가장 오른쪽 자식으로 이동하고 자식 노드를 재귀적으로 검색합니다.
1.3.2단계: 루트에 세 개 이상의 키가 있으면 나머지를 검색합니다.
2 단계: 전체 트리를 순회한 후에도 k 요소가 발견되지 않으면 해당 검색 요소는 B 트리에 존재하지 않습니다.
예제를 통해 위의 단계를 시각화해 보겠습니다. 다음 B 트리에서 k=34 키를 검색한다고 가정해 보겠습니다.

그림 3.1. 주어진 B 트리
- 먼저, 키가 있는지 확인하겠습니다. k = 34 루트 노드에 있습니다. 키가 루트에 없으므로 하위 노드로 이동하겠습니다. 또한 루트 노드에 두 개의 자식이 있는 것을 볼 수 있습니다. 따라서 두 키 사이에 필요한 값을 비교하겠습니다.
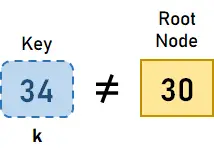
그림 3.2. 키 k가 루트에 존재하지 않습니다. - 이제 키 k가 루트 노드, 즉 30보다 크다는 것을 알 수 있으므로 루트의 오른쪽 자식으로 진행하겠습니다.
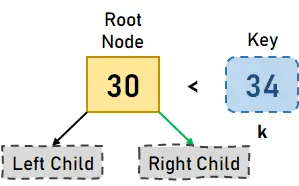
그림 3.3. 키 k > 30, 오른쪽 자식으로 이동 - 이제 키 k를 노드에 존재하는 값, 즉 각각 40과 50과 비교할 것입니다. 키 k가 왼쪽 키보다 작기 때문에(즉, 40) 노드의 왼쪽 자식으로 이동합니다.
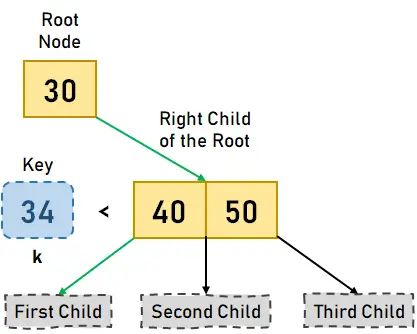
그림 3.4. 키 k<40, move to left child< li> - 40의 왼쪽 자식의 값이 필요한 값인 34이므로 키를 찾았다고 결론을 내릴 수 있고 검색 작업이 완료됩니다.
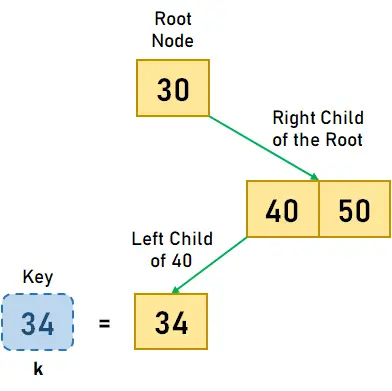
그림 3.4. 키 k = 34, 왼쪽 자식 40




위의 예에서 키를 찾을 때까지 4가지 다른 값과 비교했습니다. 따라서 B Tree에서 탐색 연산에 필요한 시간복잡도는 다음과 같다. O(로그?n) .
B 트리에 작업 삽입
B 트리에 데이터 요소를 삽입하는 동안 먼저 해당 요소가 트리에 이미 존재하는지 여부를 확인해야 합니다. 데이터 요소가 B 트리 내에서 발견되면 삽입 작업이 발생하지 않습니다. 그러나 그렇지 않은 경우 추가로 삽입을 진행하겠습니다. 리프 노드에 요소를 삽입하는 동안 처리해야 하는 두 가지 시나리오가 있습니다.
B 트리에 데이터 요소를 삽입하는 단계:
1 단계: B 트리의 순서를 기준으로 노드의 최대 키 수를 계산하는 것부터 시작하겠습니다.
2 단계: 트리가 비어 있으면 루트 노드가 할당되고 루트 노드 역할을 하는 키를 삽입합니다.
3단계: 이제 삽입할 해당 노드를 검색하겠습니다.
4단계: 노드가 가득 찬 경우:
4.1단계: 데이터 요소를 오름차순으로 삽입하겠습니다.
4.2단계: 데이터 요소가 최대 키 수보다 크면 중앙값에서 전체 노드를 분할합니다.
4.3단계: 중앙값 키를 위쪽으로 밀고 왼쪽 및 오른쪽 키를 왼쪽 및 오른쪽 자식으로 분할합니다.
5단계: 노드가 가득 차지 않으면 오름차순으로 노드를 삽입합니다.
예제를 통해 위의 단계를 시각화해 보겠습니다. 순서 4의 B 트리를 생성해야 한다고 가정합니다. B 트리에 삽입해야 하는 데이터 요소는 다음과 같습니다. 5,3,21,11,1,16,8,13,4 및 9 .
- m은 3과 같으므로 노드의 최대 키 수 = m-1 = 3-1 = 2 .
- 삽입부터 시작하겠습니다. 5 빈 나무에서.

그림 4.1. 5개 삽입 - 이제 트리에 3을 삽입하겠습니다. 3은 5보다 작으므로 같은 노드에서 5의 왼쪽에 3을 삽입합니다.

그림 4.2. 3개 삽입 - 이제 트리에 21을 삽입할 것이며, 21은 5보다 크므로 동일한 노드에서 5의 오른쪽에 삽입됩니다. 그러나 노드의 최대 키 개수는 2개이므로 이 키 중 하나는 분할하기 위해 상위 노드로 이동됩니다. 따라서 중간 데이터 요소인 5는 위로 이동하고 3과 21은 각각 왼쪽 및 오른쪽 노드가 됩니다.
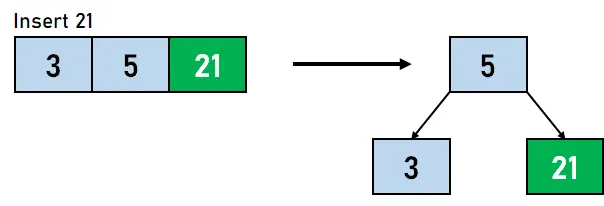
그림 4.3. 21 삽입 - 이제 다음 데이터 요소, 즉 5보다 크고 21보다 작은 11을 삽입할 차례입니다. 따라서 21을 키로 구성하는 노드의 왼쪽에 11이 키로 삽입됩니다.
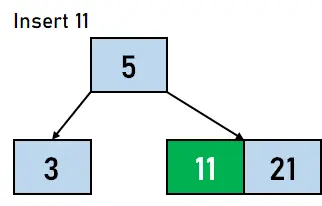
그림 4.4. 11 삽입 - 마찬가지로 다음 데이터 요소 1을 트리에 삽입할 것이며 관찰할 수 있듯이 1은 3보다 작습니다. 따라서 3개로 구성된 노드의 왼쪽에 키로 삽입됩니다.
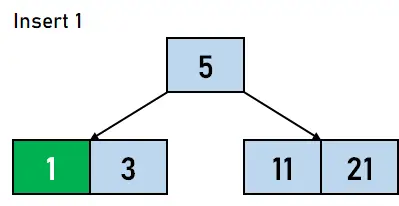
그림 4.5. 1개 삽입 중 - 이제 11보다 크고 21보다 작은 데이터 요소 16을 트리에 삽입하겠습니다. 그러나 해당 노드의 키 수가 최대 키 수를 초과합니다. 따라서 노드가 분할되어 중간 키가 루트로 이동됩니다. 따라서 16은 5의 오른쪽에 삽입되어 11과 21을 두 개의 별도 노드로 분할합니다.
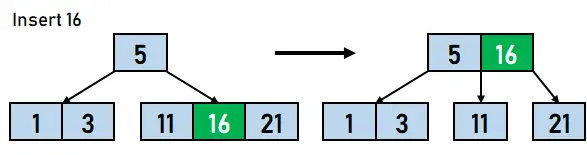
그림 4.6. 16 삽입 - 데이터 요소 8은 11의 왼쪽에 키로 삽입됩니다.
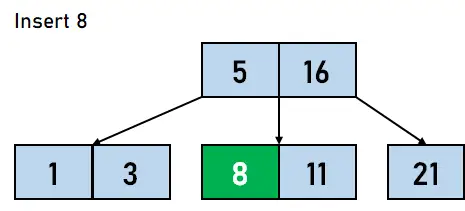
그림 4.7. 8 삽입 - 16보다 작고 11보다 큰 13을 트리에 삽입합니다. 따라서 데이터 요소 13은 8과 11로 구성된 노드의 오른쪽에 삽입되어야 합니다. 그러나 트리의 최대 키 수는 2만 있으면 분할이 발생하여 중간 데이터 요소 11을 위 노드로 이동하고 8과 13을 두 개의 별도 노드로 이동합니다. 이제 위의 노드는 5, 11, 16으로 구성되며, 이는 다시 최대 키 수를 초과합니다. 따라서 또 다른 분할이 발생하여 데이터 요소 11을 5와 16을 하위로 갖는 루트 노드로 만듭니다.
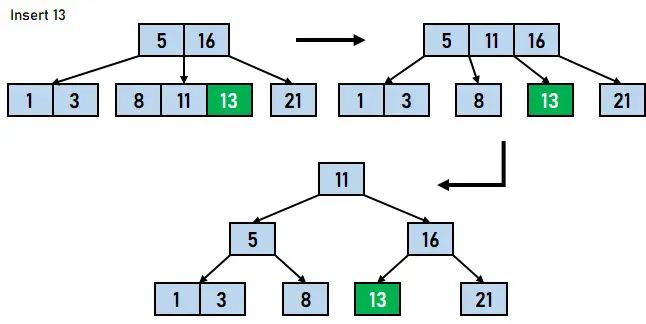
그림 4.8. 13 삽입 - 데이터 요소 4는 5보다 작고 3보다 크므로 1과 3으로 구성된 노드 오른쪽에 삽입되며, 이는 다시 노드의 최대 키 수를 초과하게 됩니다. 따라서 유출이 다시 발생하여 3이 5 옆의 상위 노드로 이동합니다.
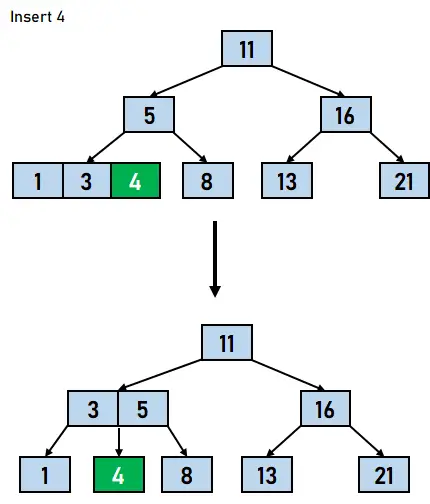
그림 4.9. 4개 삽입 - 마지막으로 8보다 크고 11보다 작은 데이터 요소 9가 8로 구성된 노드의 오른쪽에 키로 삽입됩니다.
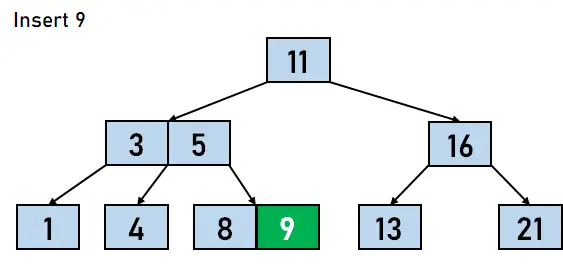
그림 4.10. 9 삽입










위의 예에서는 다양한 비교를 수행했습니다. 첫 번째 값은 트리에 직접 삽입되었습니다. 그 후 모든 값은 해당 트리에서 사용 가능한 노드와 비교되어야 했습니다. B 트리에서 삽입 작업의 시간 복잡도는 노드 수와 에 따라 다릅니다.
B 트리에서 작업 삭제
B 트리의 데이터 요소 삭제에는 세 가지 주요 이벤트가 포함됩니다.
- 삭제할 키가 존재하는 노드를 검색하면,
- 키를 삭제하고,
- 필요한 경우 트리 균형을 조정합니다.
트리에서 요소를 삭제하는 동안 언더플로라는 조건이 발생할 수 있습니다. 언더플로는 노드가 최소 키 수보다 적게 구성될 때 발생합니다. 그것은 유지되어야합니다.
다음은 삭제/제거 작업을 시각화하기 전에 이해해야 할 몇 가지 용어입니다.
B 트리에서 삭제 작업의 대표적인 세 가지 사례는 다음과 같습니다.
사례 1: 키 삭제/제거는 리프 노드에 있습니다. 이 사건은 다시 두 가지 경우로 나누어집니다.
1. 키의 삭제/제거는 노드가 보유해야 하는 최소 키 수의 속성을 위반하지 않습니다.
다음 B 트리에서 키 32를 삭제하는 예를 사용하여 이 사례를 시각화해 보겠습니다.

그림 4.1: B 트리에서 리프 노드 키(32) 삭제
우리가 볼 수 있듯이 이 트리에서 32를 삭제해도 위의 속성을 위반하지 않습니다.
2. 키의 삭제/제거는 노드가 보유해야 하는 최소 키 수의 속성을 위반합니다. 이 경우, 왼쪽에서 오른쪽 순서로 가까운 형제 노드로부터 키를 빌려야 합니다.
먼저, 가까운 왼쪽 형제를 방문하겠습니다. 왼쪽 형제 노드에 최소 개수보다 많은 키가 있는 경우 이 노드에서 키를 빌립니다.
그렇지 않으면 가까운 Right 형제 노드에서 빌려오는지 확인합니다.
이제 위의 B 트리에서 31을 삭제하는 예를 통해 이 사례를 시각화해 보겠습니다. 이 경우 왼쪽 형제 노드에서 키를 빌릴 것입니다.

그림 4.2: B 트리에서 리프 노드 키(31) 삭제
두 인접 형제 노드가 이미 최소 수의 키로 구성되어 있는 경우 노드를 왼쪽 형제 노드 또는 오른쪽 노드와 병합합니다. 이 병합 프로세스는 상위 노드를 통해 수행됩니다.
위 B 트리에서 키 30을 삭제하여 다시 시각화해 보겠습니다.

그림 4.3: B 트리에서 리프 노드 키(30) 삭제
사례 2: 키 삭제/제거는 리프가 아닌 노드에 있습니다. 이 사건은 다음과 같이 또 다른 사건으로 나누어집니다.
1. 제거된 비리프/내부 노드는 왼쪽 하위 노드에 최소 키 개수보다 많은 키가 있는 경우 순서대로의 전임 노드로 교체됩니다.
Java 객체를 json으로 변환
B 트리에서 키 33을 삭제하는 예를 사용하여 이 사례를 시각화해 보겠습니다.

그림 4.4: B 트리에서 리프 노드 키(33) 삭제
2. 제거된 비리프/내부 노드는 오른쪽 하위 노드에 최소 키 개수보다 많은 키가 있는 경우 순서대로의 후속 노드로 대체됩니다.
두 하위 중 하나에 최소 개수의 키가 있는 경우 왼쪽 및 오른쪽 하위 노드를 병합합니다.
B 트리에서 키 30을 삭제하여 이 사례를 시각화해 보겠습니다.

그림 4.5: B 트리에서 리프 노드 키(30) 삭제
병합 후 상위 노드의 키 수가 최소 개수보다 적으면 다음과 같이 형제를 찾을 수 있습니다. 사례 1 .
사례 3: 다음 경우에는 트리의 높이가 줄어듭니다. 대상 키가 내부 노드에 있고 키를 제거하면 노드에 더 적은 수의 키(필요한 최소값보다 적음)가 발생하는 경우 순서대로의 선행 키와 순서대로의 후속 키를 찾습니다. 두 자녀 모두 최소 개수의 키를 갖고 있으면 대출이 발생할 수 없습니다. 이로 인해 사례 2(3) , 즉 하위 노드를 병합합니다.
열쇠를 빌릴 형제자매를 다시 찾아보겠습니다. 그러나 형제 노드도 최소 개수의 키로 구성된 경우 부모 노드와 함께 형제 노드와 노드를 병합하고 요구 사항(오름차순)에 따라 자식 노드를 정렬합니다.
주어진 B 트리에서 데이터 요소 10을 삭제하는 예를 통해 이 사례를 시각화해 보겠습니다.

그림 4.6: B 트리에서 리프 노드 키(10) 삭제
위 예의 시간 복잡도는 키를 삭제해야 하는 위치에 따라 달라집니다. 따라서 B 트리에서 삭제 작업의 시간 복잡도는 다음과 같습니다. O(로그?n) .
결론
이 튜토리얼에서 우리는 B 트리에 대해 배웠고 다양한 예제를 통해 다양한 작업을 시각화했습니다. 우리는 또한 B 트리의 몇 가지 기본 속성과 규칙을 이해했습니다.