Java에서 메모리 관리는 메모리 관리라고 불리는 객체 할당 및 할당 해제 프로세스입니다. Java는 메모리 관리를 자동으로 수행합니다. Java는 다음과 같은 자동 메모리 관리 시스템을 사용합니다. 가비지 수집기 . 따라서 애플리케이션에서 메모리 관리 로직을 구현할 필요가 없습니다. Java 메모리 관리는 두 가지 주요 부분으로 나뉩니다.
JVM 메모리 구조
JVM은 힙에 다양한 런타임 데이터 영역을 생성합니다. 이 영역은 프로그램 실행 중에 사용됩니다. JVM이 종료되면 메모리 영역이 소멸되고, 스레드가 종료되면 데이터 영역이 소멸됩니다.
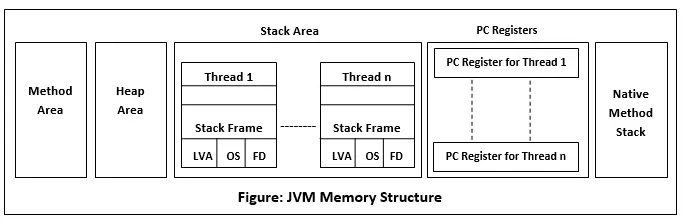
방법 영역
메소드 영역은 모든 스레드에서 공유되는 힙 메모리의 일부입니다. JVM이 시작될 때 생성됩니다. 클래스 구조, 슈퍼클래스 이름, 인터페이스 이름 및 생성자를 저장하는 데 사용됩니다. JVM은 메소드 영역에 다음과 같은 종류의 정보를 저장합니다.
- 유형의 정규화된 이름(예: 문자열)
- 유형의 수정자
- 유형의 직접 슈퍼클래스 이름
- 슈퍼 인터페이스의 정규화된 이름의 구조화된 목록입니다.
힙 영역
힙은 실제 객체를 저장합니다. JVM이 시작될 때 생성됩니다. 필요한 경우 사용자는 힙을 제어할 수 있습니다. 고정 크기 또는 동적 크기일 수 있습니다. new 키워드를 사용하면 JVM은 힙에 객체에 대한 인스턴스를 생성합니다. 해당 객체의 참조는 스택에 저장됩니다. 실행 중인 각 JVM 프로세스마다 하나의 힙만 존재합니다. 힙이 가득 차면 쓰레기가 수집됩니다. 예를 들어:
StringBuilder sb= new StringBuilder();
위의 문은 StringBuilder 클래스의 개체를 만듭니다. 객체는 힙에 할당되고 참조 sb는 스택에 할당됩니다. 힙은 다음 부분으로 나뉩니다.
- 젊은 세대
- 생존자 공간
- 구세대
- 영구 세대
- 코드 캐시
참조 유형
참고문헌에는 네 가지 유형이 있습니다. 강한 , 약한 , 부드러운 , 그리고 팬텀 참조 . 참조 유형 간의 차이점은 참조하는 힙의 개체가 다른 기준에 따라 가비지 수집에 적합하다는 것입니다.
강력한 참조: 일상적인 프로그래밍에 사용하기 때문에 매우 간단합니다. Strong 참조가 첨부된 객체는 가비지 수집 대상이 아닙니다. 다음 문을 사용하여 강력한 참조를 만들 수 있습니다.
자바의 소수 프로그램
StringBuilder sb= new StringBuilder();
약한 참조: 다음 가비지 수집 프로세스 이후에는 생존하지 않습니다. 데이터가 언제 다시 요청될지 확실하지 않은 경우. 이 조건에서는 이에 대한 약한 참조를 만들 수 있습니다. 이 경우 가비지 컬렉터가 처리하면 객체가 파괴됩니다. 해당 객체를 다시 검색하려고 하면 null 값을 얻습니다. 이는 다음에서 정의됩니다. java.lang.ref.WeakReference 수업. 다음 명령문을 사용하여 약한 참조를 만들 수 있습니다.
WeakReference reference = new WeakReference(new StringBuilder());
소프트 참조: 애플리케이션의 메모리가 부족할 때 수집됩니다. 가비지 수집기는 소프트하게 도달 가능한 개체를 수집하지 않습니다. 모든 소프트 참조 객체는 OutOfMemoryError가 발생하기 전에 수집됩니다. 다음 문을 사용하여 소프트 참조를 만들 수 있습니다.
SoftReference reference = new SoftReference(new StringBuilder());
팬텀 참조: 다음에서 사용 가능합니다. java.lang.ref 패키지. 이는 다음에서 정의됩니다. java.lang.ref.PhantomReference 수업. 자신을 가리키는 가상 참조만 있는 개체는 가비지 수집기가 수집하려고 할 때마다 수집할 수 있습니다. 다음 명령문을 사용하여 팬텀 참조를 만들 수 있습니다.
PhantomReference reference = new PhantomReference(new StringBuilder());
스택 영역
스택 영역은 스레드가 생성될 때 생성됩니다. 고정 크기 또는 동적 크기일 수 있습니다. 스택 메모리는 스레드별로 할당됩니다. 데이터 및 부분 결과를 저장하는 데 사용됩니다. 여기에는 힙 개체에 대한 참조가 포함되어 있습니다. 또한 힙의 개체에 대한 참조가 아닌 값 자체를 보유합니다. 스택에 저장되는 변수에는 범위라는 특정 가시성이 있습니다.
스택 프레임: 스택 프레임은 스레드의 데이터를 포함하는 데이터 구조입니다. 스레드 데이터는 현재 메서드의 스레드 상태를 나타냅니다.
- 부분 결과 및 데이터를 저장하는 데 사용됩니다. 또한 동적 연결, 메서드에 의한 값 반환 및 예외 전달을 수행합니다.
- 메서드가 호출되면 새 프레임이 생성됩니다. 메서드 호출이 완료되면 프레임이 삭제됩니다.
- 각 프레임에는 자체 LVA(로컬 변수 배열), OS(피연산자 스택) 및 FD(프레임 데이터)가 포함되어 있습니다.
- LVA, OS, FD의 크기는 컴파일 타임에 결정됩니다.
- 특정 제어 스레드의 어느 지점에서든 하나의 프레임(메서드 실행을 위한 프레임)만 활성화됩니다. 이 프레임을 현재 프레임이라고 하며 해당 방법을 현재 방법이라고 합니다. 메소드의 클래스를 현재 클래스라고 합니다.
- 해당 메서드가 다른 메서드를 호출하거나 메서드가 완료되면 프레임은 현재 메서드를 중지합니다.
- 스레드에 의해 생성된 프레임은 해당 스레드에 대해 로컬이며 다른 스레드에서 참조할 수 없습니다.
네이티브 메소드 스택
C 스택이라고도 합니다. Java 이외의 언어로 작성된 네이티브 코드에 대한 스택입니다. JNI(Java Native Interface)는 네이티브 스택을 호출합니다. 네이티브 스택의 성능은 OS에 따라 다릅니다.
PC 레지스터
각 스레드에는 이와 관련된 프로그램 카운터(PC) 레지스터가 있습니다. PC 레지스터는 반환 주소 또는 기본 포인터를 저장합니다. 또한 현재 실행 중인 JVM 명령어의 주소도 포함됩니다.
가비지 콜렉터 작업
가비지 콜렉터 개요
프로그램이 Java에서 실행될 때 다양한 방식으로 메모리를 사용합니다. 힙은 객체가 존재하는 메모리의 일부입니다. 이는 가비지 수집 프로세스와 관련된 유일한 메모리 부분입니다. 가비지 수집 가능 힙이라고도 합니다. 모든 가비지 수집은 힙에 가능한 한 많은 여유 공간이 있는지 확인합니다. 가비지 수집기의 기능은 접근할 수 없는 개체를 찾아서 삭제하는 것입니다.
자바 루프에서 벗어나다
객체 할당
객체가 할당되면 JRockit JVM은 객체의 크기를 확인합니다. 작은 물체와 큰 물체를 구별합니다. 작은 크기와 큰 크기는 JVM 버전, 힙 크기, 가비지 수집 전략 및 사용된 플랫폼에 따라 다릅니다. 객체의 크기는 일반적으로 2KB에서 128KB 사이입니다.
작은 개체는 힙의 사용 가능한 청크인 TLA(스레드 로컬 영역)에 저장됩니다. TLA는 다른 스레드와 동기화되지 않습니다. TLA가 가득 차면 새 TLA를 요청합니다.
반면, TLA 내부에 맞지 않는 대형 객체는 힙에 직접 할당됩니다. 스레드가 Young 공간을 사용하는 경우 Old 공간에 직접 저장됩니다. 대형 개체에는 스레드 간에 더 많은 동기화가 필요합니다.
자바에서 정렬된 배열
Java 가비지 수집기란 무엇입니까?
JVM은 가비지 수집기를 제어합니다. JVM은 가비지 수집을 수행할 시기를 결정합니다. 또한 가비지 수집기를 실행하도록 JVM에 요청할 수도 있습니다. 그러나 어떤 조건에서도 JVM이 준수한다는 보장은 없습니다. JVM은 메모리가 부족하다는 것을 감지하면 가비지 수집기를 실행합니다. Java 프로그램이 가비지 컬렉터를 요청하면 JVM은 일반적으로 짧은 순서로 요청을 승인합니다. 요청이 수락되었는지 확인하지 않습니다.
이해해야 할 점은 ' 객체가 가비지 수집 대상이 되는 시점은 언제입니까? '
모든 Java 프로그램에는 둘 이상의 스레드가 있습니다. 각 스레드에는 실행 스택이 있습니다. main() 메소드인 Java 프로그램에서 실행할 스레드가 있습니다. 이제 라이브 스레드가 액세스할 수 없는 객체가 가비지 수집에 적합하다고 말할 수 있습니다. 가비지 수집기는 해당 개체를 삭제할 수 있는 것으로 간주합니다. 프로그램에 개체를 참조하는 참조 변수(라이브 스레드에서 사용할 수 있는 참조 변수)가 있는 경우 이 개체를 호출합니다. 도달 가능 .
여기서 '라는 의문이 생긴다. Java 애플리케이션에 메모리가 부족할 수 있나요? '
대답은 '예'입니다. 가비지 수집 시스템은 사용되지 않는 메모리에서 개체를 시도합니다. 그러나 많은 라이브 개체를 유지 관리하는 경우 가비지 수집이 메모리가 충분하다는 것을 보장하지는 않습니다. 사용 가능한 메모리만 효과적으로 관리됩니다.
가비지 수집 유형
가비지 수집에는 다음과 같은 5가지 유형이 있습니다.
마크 앤 스윕 알고리즘
JRockit JVM은 가비지 수집을 수행하기 위해 마크 및 스윕 알고리즘을 사용합니다. 여기에는 마크 단계와 스윕 단계의 두 단계가 포함됩니다.
마크 단계: 스레드, 기본 핸들 및 기타 GC 루트 소스에서 액세스할 수 있는 개체는 라이브로 표시됩니다. 모든 개체 트리에는 둘 이상의 루트 개체가 있습니다. GC 루트는 항상 접근 가능합니다. 따라서 루트에 가비지 수집 루트가 있는 모든 개체입니다. 사용 중인 모든 객체를 식별하고 표시하며 나머지는 가비지로 간주될 수 있습니다.

스윕 단계: 이 단계에서는 힙을 탐색하여 활성 객체 사이의 간격을 찾습니다. 이러한 간격은 여유 목록에 기록되며 새 개체 할당에 사용할 수 있습니다.
마크 앤 스윕에는 두 가지 향상된 버전이 있습니다.
동시 표시 및 스윕
이를 통해 가비지 수집의 상당 부분 동안 스레드가 계속 실행될 수 있습니다. 표시에는 다음과 같은 유형이 있습니다.
평행 마크 및 스윕
가능한 한 빨리 가비지 수집을 수행하기 위해 시스템에서 사용 가능한 모든 CPU를 사용합니다. 병렬 가비지 수집기라고도 합니다. 병렬 가비지 수집이 실행될 때 스레드가 실행되지 않습니다.
안드로이드 폰의 아이폰 이모티콘
마크 앤 스윕의 장점
- 이는 반복되는 과정입니다.
- 무한 루프입니다.
- 알고리즘 실행 중에는 추가 오버헤드가 허용되지 않습니다.
마크 앤 스윕의 단점
- 가비지 수집 알고리즘이 실행되는 동안 정상적인 프로그램 실행을 중지합니다.
- 프로그램에서 여러 번 실행됩니다.