이 기사에서는 데이터 구조의 DFS 알고리즘에 대해 설명합니다. 트리 데이터 구조나 그래프의 모든 꼭지점을 검색하는 재귀 알고리즘입니다. 깊이 우선 탐색(DFS) 알고리즘은 그래프 G의 초기 노드에서 시작하여 목표 노드 또는 자식이 없는 노드를 찾을 때까지 더 깊이 진행됩니다.
재귀적 특성으로 인해 스택 데이터 구조를 사용하여 DFS 알고리즘을 구현할 수 있습니다. DFS를 구현하는 과정은 BFS 알고리즘과 유사합니다.
DFS 순회를 구현하는 단계별 프로세스는 다음과 같습니다.
- 먼저 그래프의 총 정점 수로 스택을 만듭니다.
- 이제 순회 시작점으로 정점을 선택하고 해당 정점을 스택에 푸시합니다.
- 그 후, 방문하지 않은 정점(스택 상단의 정점에 인접한)을 스택의 상단으로 푸시합니다.
- 이제 스택 상단의 정점에서 방문할 정점이 더 이상 남지 않을 때까지 3단계와 4단계를 반복합니다.
- 정점이 남아 있지 않으면 돌아가서 스택에서 정점을 팝합니다.
- 스택이 빌 때까지 2, 3, 4단계를 반복합니다.
DFS 알고리즘의 응용
DFS 알고리즘을 사용하는 응용 프로그램은 다음과 같습니다.
- DFS 알고리즘을 사용하여 위상 정렬을 구현할 수 있습니다.
- 두 정점 사이의 경로를 찾는 데 사용할 수 있습니다.
- 그래프에서 주기를 감지하는 데에도 사용할 수 있습니다.
- DFS 알고리즘은 단일 솔루션 퍼즐에도 사용됩니다.
- DFS는 그래프가 이분형인지 아닌지를 결정하는 데 사용됩니다.
연산
1 단계: SET STATUS = G의 각 노드에 대해 1(준비 상태)
2 단계: 시작 노드 A를 스택에 푸시하고 STATUS = 2(대기 상태)로 설정합니다.
3단계: STACK이 빌 때까지 4단계와 5단계를 반복합니다.
4단계: 최상위 노드 N을 팝합니다. 이를 처리하고 STATUS = 3(처리된 상태)으로 설정합니다.
5단계: 준비 상태(STATUS = 1)에 있는 N의 모든 이웃을 스택에 푸시하고 해당 STATUS = 2(대기 상태)로 설정합니다.
[루프 종료]
6단계: 출구
의사코드
DFS(G,v) ( v is the vertex where the search starts ) Stack S := {}; ( start with an empty stack ) for each vertex u, set visited[u] := false; push S, v; while (S is not empty) do u := pop S; if (not visited[u]) then visited[u] := true; for each unvisited neighbour w of uu push S, w; end if end while END DFS() DFS 알고리즘의 예
이제 예제를 사용하여 DFS 알고리즘의 작동을 이해해 보겠습니다. 아래 예제에는 7개의 꼭짓점을 갖는 방향성 그래프가 있습니다.
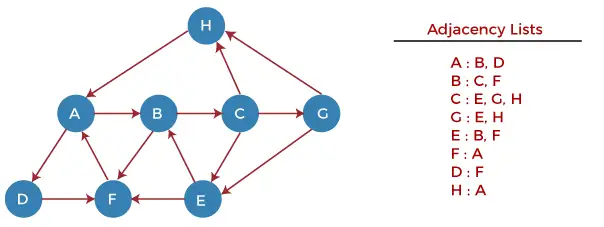
이제 노드 H부터 그래프를 살펴보겠습니다.
1 단계 - 먼저 H를 스택에 밀어 넣습니다.
STACK: H
2 단계 - 스택의 최상위 요소(예: H)를 POP하고 인쇄합니다. 이제 H의 모든 이웃을 준비 상태인 스택으로 푸시합니다.
Print: H]STACK: A
3단계 - 스택의 최상위 요소(예: A)를 POP하고 인쇄합니다. 이제 A의 모든 이웃을 준비 상태인 스택으로 푸시합니다.
Print: A STACK: B, D
4단계 - 스택의 최상위 요소(예: D)를 POP하고 인쇄합니다. 이제 D의 모든 이웃을 준비 상태인 스택으로 푸시합니다.
Print: D STACK: B, F
5단계 - 스택의 최상위 요소(예: F)를 POP하고 인쇄합니다. 이제 F의 모든 이웃을 준비 상태인 스택으로 푸시합니다.
Print: F STACK: B
6단계 - 스택의 최상위 요소(예: B)를 POP하고 인쇄합니다. 이제 B의 모든 이웃을 준비 상태인 스택으로 푸시합니다.
Print: B STACK: C
7단계 - 스택의 최상위 요소(예: C)를 POP하고 인쇄합니다. 이제 준비 상태에 있는 스택에 C의 모든 이웃을 푸시합니다.
Print: C STACK: E, G
8단계 - 스택의 최상위 요소를 POP합니다. 즉, G는 준비 상태에 있는 스택에 G의 모든 이웃 요소를 PUSH합니다.
Print: G STACK: E
9단계 - 스택의 최상위 요소를 POP합니다. 즉, E는 E의 모든 이웃 요소를 준비 상태인 스택으로 PUSH합니다.
Print: E STACK:
이제 모든 그래프 노드가 탐색되었으며 스택은 비어 있습니다.
깊이 우선 탐색 알고리즘의 복잡성
DFS 알고리즘의 시간 복잡도는 다음과 같습니다. O(V+E) 여기서 V는 정점의 수이고 E는 그래프의 가장자리 수입니다.
knn 알고리즘
DFS 알고리즘의 공간 복잡도는 O(V)입니다.
DFS 알고리즘 구현
이제 Java에서 DFS 알고리즘의 구현을 살펴보겠습니다.
이 예에서 코드를 시연하기 위해 사용하는 그래프는 다음과 같습니다.

/*A sample java program to implement the DFS algorithm*/ import java.util.*; class DFSTraversal { private LinkedList adj[]; /*adjacency list representation*/ private boolean visited[]; /* Creation of the graph */ DFSTraversal(int V) /*'V' is the number of vertices in the graph*/ { adj = new LinkedList[V]; visited = new boolean[V]; for (int i = 0; i <v; i++) adj[i]="new" linkedlist(); } * adding an edge to the graph void insertedge(int src, int dest) { adj[src].add(dest); dfs(int vertex) visited[vertex]="true;" *mark current node as visited* system.out.print(vertex + ' '); iterator it="adj[vertex].listIterator();" while (it.hasnext()) n="it.next();" if (!visited[n]) dfs(n); public static main(string args[]) dfstraversal dfstraversal(8); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, system.out.println('depth first traversal for is:'); graph.dfs(0); < pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/28/dfs-algorithm-3.webp" alt="DFS algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the depth-first search technique, its example, complexity, and implementation in the java programming language. Along with that, we have also seen the applications of the depth-first search algorithm.</p> <p>So, that's all about the article. Hope it will be helpful and informative to you.</p> <hr></v;>