이 SQL 기사에서는 SQL 데이터베이스 쿼리에서 IN 키워드를 사용하는 방법을 배웁니다.
SQL의 IN 키워드는 무엇입니까?
그만큼 안에 데이터베이스 사용자가 WHERE 절에서 둘 이상의 값을 정의할 수 있도록 하는 구조적 쿼리 언어의 논리 연산자입니다.
중위순회
IN 연산자가 있는 WHERE 절은 주어진 값 세트와 일치하는 결과의 레코드를 표시합니다. IN 연산자의 괄호 안에 하위 쿼리를 지정할 수도 있습니다.
SQL 데이터베이스의 INSERT, SELECT, UPDATE 및 DELETE 쿼리와 함께 IN 연산자를 사용할 수 있습니다.
SQL의 IN 연산자는 쿼리의 여러 OR 조건 프로세스를 대체합니다.
IN 연산자의 구문:
SELECT Column_Name_1, Column_Name_2, Column_Name_3, ......, Column_Name_N FROM Table_Name WHERE Column_Name IN (Value_1, Value_2, Value_3, ......., Value_N);
SQL 문에서 IN 연산자를 사용하려면 아래에 제공된 단계를 동일한 순서로 따라야 합니다.
- SQL로 데이터베이스를 생성합니다.
- 새 SQL 테이블을 만듭니다.
- 테이블에 데이터를 삽입합니다.
- 삽입된 데이터를 봅니다.
- SQL IN 연산자를 사용하여 테이블의 데이터를 표시합니다.
이제 최고의 SQL 예제를 통해 각 단계를 하나씩 간략하게 설명하겠습니다.
1단계: 간단한 새 데이터베이스 만들기
첫 번째 단계는 구조적 쿼리 언어로 새 데이터베이스를 만드는 것입니다.
다음 CREATE 문은 새 항목을 생성합니다. 기계_대학 SQL 서버의 데이터베이스:
CREATE Database Mechanical_College;
2단계: 새 테이블 만들기
이제 데이터베이스에 새 테이블을 만드는 데 도움이 되는 다음 SQL 구문을 사용하세요.
CREATE TABLE table_name ( 1st_Column data type (character_size of 1st Column), 2nd_Column data type (character_size of the 2nd column ), 3rd_Column data type (character_size of the 3rd column), ...
Nth_Column data type (character_size of the Nth column) );
다음 CREATE 문은 교수_정보 테이블에 기계_대학 데이터 베이스:
CREATE TABLE Faculty_Info ( Faculty_ID INT NOT NULL PRIMARY KEY, Faculty_First_Name VARCHAR (100), Faculty_Last_Name VARCHAR (100), Faculty_Dept_Id INT NOT NULL, Faculty_Joining_DateDATE, Faculty_City Varchar (80), Faculty_Salary INT );
3단계: 테이블에 데이터 삽입
다음 INSERT 쿼리는 Faculty_Info 테이블에 교수진의 레코드를 삽입합니다.
INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary) VALUES (1001, Arush, Sharma, 4001, 2020-01-02, Delhi, 20000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary) VALUES (1002, Bulbul, Roy, 4002, 2019-12-31, Delhi, 38000 ); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary) VALUES (1004, Saurabh, Sharma, 4001, 2020-10-10, Mumbai, 45000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary) VALUES (1005, Shivani, Singhania, 4001, 2019-07-15, Kolkata, 42000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary) VALUES (1006, Avinash, Sharma, 4002, 2019-11-11, Delhi, 28000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary)VALUES (1007, Shyam, Besas, 4003, 2021-06-21, Lucknow, 35000);
4단계: 삽입된 데이터 보기
다음 SELECT 문은 Faculty_Info 테이블의 데이터를 표시합니다.
SELECT * FROM Faculty_Info;
| 교수_ID | 교수_이름_이름 | 교수_성_이름 | Faculty_Dept_Id | 교수진_입학_날짜 | 학부_시 | 교수_급여 |
|---|---|---|---|---|---|---|
| 1001 | 곰 | 샤르마 | 4001 | 2020-01-02 | 델리 | 20000 |
| 1002 | 불불 | 로이 | 4002 | 2019-12-31 | 델리 | 38000 |
| 1004 | 사우라브 | 로이 | 4001 | 2020-10-10 | 뭄바이 | 45000 |
| 1005 | 시바니 | 싱가니아 | 4001 | 2019-07-15 | 콜카타 | 42000 |
| 1006 | 아비나쉬 | 샤르마 | 4002 | 2019-11-11 | 델리 | 28000 |
| 1007 | 샤암 | 너는 키스한다 | 4003 | 2021-06-21 | 러크나우 | 35000 |
5단계: IN 연산자를 사용하여 다양한 방법으로 Faculty_Info 테이블의 데이터 보기
다음 쿼리에서는 IN 연산자와 함께 숫자 값을 사용합니다.
SELECT Faculty_Id, Faculty_First_Name, Faculty_Dept_Id, Faculty_Joining_Date, Faculty_Salary FROM Faculty_Info WHERE Faculty_Salary IN ( 38000, 42000, 45000, 35000);
이 쿼리는 WHERE 절의 IN 연산자에 급여가 전달된 교수진의 레코드만 표시합니다.
산출:
| 교수_ID | 교수_이름_이름 | Faculty_Dept_Id | 교수진_입학_날짜 | 교수_급여 |
|---|---|---|---|---|
| 1002 | 불불 | 4002 | 2019-12-31 | 38000 |
| 1004 | 사우라브 | 4001 | 2020-10-10 | 45000 |
| 1005 | 시바니 | 4001 | 2019-07-15 | 42000 |
| 1007 | 샤암 | 4003 | 2021-06-21 | 35000 |
다음 쿼리에서는 IN 논리 연산자와 함께 텍스트 또는 문자 값을 사용합니다.
SELECT Faculty_Id, Faculty_First_Name, Faculty_Joining_Date, Faculty_City FROM Faculty_Info WHERE Faculty_City IN ( Mumbai, Kolkata, Lucknow);
이 쿼리는 WHERE 절의 IN 연산자 괄호 안에 도시가 포함된 학부의 레코드만 표시합니다.
산출:
| 교수_ID | 교수_이름_이름 | 교수진_입학_날짜 | 학부_시 |
|---|---|---|---|
| 1004 | 사우라브 | 2020-10-10 | 뭄바이 |
| 1005 | 시바니 | 2019-07-15 | 콜카타 |
| 1007 | 샤암 | 2021-06-21 | 러크나우 |
다음 쿼리는 IN 논리 연산자와 함께 DATEformat을 사용합니다.
SELECT Faculty_Id, Faculty_First_Name, Faculty_Dept_ID Faculty_Joining_Date, Faculty_Salary FROM Faculty_Info WHERE Faculty_Joining_Date IN (2020-01-02, 2021-06-21, 2020-10-10, 2019-07-15);
이 쿼리는 WHERE 절의 IN 연산자에 합류 날짜가 전달된 교수진의 레코드만 표시합니다.
산출:
| 교수_ID | 교수_이름_이름 | Faculty_Dept_Id | 교수진_입학_날짜 | 교수_급여 |
|---|---|---|---|---|
| 1001 | 곰 | 4001 | 2020-01-02 | 20000 |
| 1004 | 사우라브 | 4001 | 2020-10-10 | 45000 |
| 1005 | 시바니 | 4001 | 2019-07-15 | 42000 |
| 1007 | 샤암 | 4003 | 2021-06-21 | 35000 |
다음 쿼리는 IN 논리 연산자와 함께 SQL UPDATE 명령을 사용합니다.
Kat timpf는 변호사인가요?
UPDATE Faculty_Info SET Faculty_Salary = 50000 WHERE Faculty_Dept_ID IN (4002, 4003);
이 쿼리는 WHERE 절의 IN 연산자에 Dept_Id가 전달된 교수진의 급여를 업데이트합니다.
위 쿼리의 결과를 확인하려면 SQL에 다음 SELECT 쿼리를 입력하세요.
SELECT * FROM Faculty_Info;
| 교수_ID | 교수_이름_이름 | 교수_성_이름 | Faculty_Dept_Id | 교수진_입학_날짜 | 학부_시 | 교수_급여 |
|---|---|---|---|---|---|---|
| 1001 | 곰 | 샤르마 | 4001 | 2020-01-02 | 델리 | 20000 |
| 1002 | 불불 | 로이 | 4002 | 2019-12-31 | 델리 | 50000 |
| 1004 | 사우라브 | 로이 | 4001 | 2020-10-10 | 뭄바이 | 45000 |
| 1005 | 시바니 | 싱가니아 | 4001 | 2019-07-15 | 콜카타 | 42000 |
| 1006 | 아비나쉬 | 샤르마 | 4002 | 2019-11-11 | 델리 | 50000 |
| 1007 | 샤암 | 너는 키스한다 | 4003 | 2021-06-21 | 러크나우 | 50000 |
하위 쿼리가 포함된 SQL IN 연산자
구조적 쿼리 언어에서는 IN 논리 연산자와 함께 하위 쿼리를 사용할 수도 있습니다.
하위 쿼리가 포함된 IN 연산자의 구문은 다음과 같습니다.
SELECT Column_Name_1, Column_Name_2, Column_Name_3, ......, Column_Name_N FROM Table_Name WHERE Column_Name IN (Subquery);
하위 쿼리가 포함된 IN 연산자를 이해하려면 CREATE 문을 사용하여 구조적 쿼리 언어로 두 개의 서로 다른 테이블을 만들어야 합니다.
다음 쿼리는 데이터베이스에 Faculty_Info 테이블을 생성합니다.
CREATE TABLE Faculty_Info ( Faculty_ID INT NOT NULL PRIMARY KEY, Faculty_First_Name VARCHAR (100), Faculty_Last_Name VARCHAR (100), Faculty_Dept_Id INT NOT NULL, Faculty_Address Varchar (80), Faculty_City Varchar (80), Faculty_Salary INT );
다음 쿼리는 부서_정보 데이터베이스의 테이블:
CREATE TABLE Department_Info ( Dept_Id INT NOT NULL, Dept_Name Varchar(100), Head_Id INT );
다음 INSERT 쿼리는 Faculty_Info 테이블에 교수진의 레코드를 삽입합니다.
INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Address, Faculty_City, Faculty_Salary) VALUES (1001, Arush, Sharma, 4001, 22 street, New Delhi, 20000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Address, Faculty_City, Faculty_Salary) VALUES (1002, Bulbul, Roy, 4002, 120 street, New Delhi, 38000 ); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Address, Faculty_City, Faculty_Salary) VALUES (1004, Saurabh, Sharma, 4001, 221 street, Mumbai, 45000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Address, Faculty_City, Faculty_Salary) VALUES (1005, Shivani, Singhania, 4001, 501 street, Kolkata, 42000);
다음 INSERT 쿼리는 Department_Info 테이블에 부서 레코드를 삽입합니다.
INSERT INTO Department_Info (Dept_ID, Dept_Name, Head_Id) VALUES ( 4001, Arun, 1005); INSERT INTO Department_Info (Dept_ID, Dept_Name, Head_Id) VALUES ( 4002, Zayant, 1009); INSERT INTO Department_Info (Dept_ID, Dept_Name, Head_Id) VALUES ( 4003, Manish, 1007);
다음 SELECT 문은 Faculty_Info 테이블의 데이터를 표시합니다.
SELECT * FROM Faculty_Info;
| 교수_ID | 교수_이름_이름 | 교수_성_이름 | Faculty_Dept_Id | 교수_주소 | 학부_시 | 교수_급여 |
|---|---|---|---|---|---|---|
| 1001 | 곰 | 샤르마 | 4001 | 22번가 | 뉴 델리 | 20000 |
| 1002 | 불불 | 로이 | 4002 | 120 스트리트 | 뉴 델리 | 38000 |
| 1004 | 사우라브 | 로이 | 4001 | 221 스트리트 | 뭄바이 | 45000 |
| 1005 | 시바니 | 싱가니아 | 4001 | 501 스트리트 | 콜카타 | 42000 |
| 1006 | 아비나쉬 | 샤르마 | 4002 | 12번가 | 델리 | 28000 |
| 1007 | 샤암 | 너는 키스한다 | 4003 | 202번가 | 러크나우 | 35000 |
다음 쿼리는 Department_Info 테이블의 부서 레코드를 보여줍니다.
SELECT * FROM Department_Info;
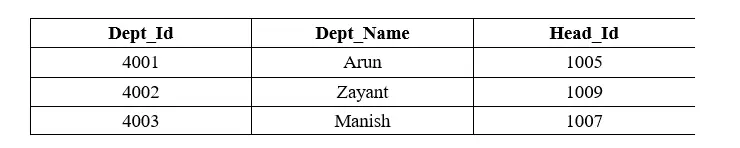
다음 쿼리는 하위 쿼리와 함께 IN 연산자를 사용합니다.
SELECT * FROM Faculty_Info WHERE Faculty_Dept_Id IN ( Select Dept_Id FROM Department_Info WHERE Head_Id >= 1007);
이 쿼리는 Faculty_Info 테이블의 Dept_ID가 Department_Info 테이블의 Dept_Id와 일치하는 교수진의 레코드를 표시합니다.
산출:
| 교수_ID | 교수_이름_이름 | 교수_성_이름 | Faculty_Dept_Id | 교수_주소 | 학부_시 | 교수_급여 |
|---|---|---|---|---|---|---|
| 1002 | 불불 | 로이 | 4002 | 120 스트리트 | 뉴 델리 | 38000 |
| 1006 | 아비나쉬 | 샤르마 | 4002 | 12번가 | 델리 | 28000 |
| 1007 | 샤암 | 너는 키스한다 | 4003 | 202번가 | 러크나우 | 35000 |
SQL에서 NOT IN은 무엇입니까?
NOT IN은 SQL IN 연산자와 정반대인 구조적 쿼리 언어의 또 다른 연산자입니다. 이를 통해 IN 연산자의 괄호를 전달하지 않는 테이블의 값에 액세스할 수 있습니다.
NOT IN 연산자는 INSERT, UPDATE, SELECT 및 DELETE SQL 쿼리에 사용할 수 있습니다.
NOT IN 연산자의 구문:
SELECT Column_Name_1, Column_Name_2, Column_Name_3, ......, Column_Name_N FROM Table_Name WHERE Column_Name NOT IN (Value_1, Value_2, Value_3, ......., Value_N);
SQL 문에서 NOT IN 연산자를 사용하려면 동일한 순서로 주어진 단계를 따라야 합니다.
- SQL 시스템에 데이터베이스를 생성합니다.
- 데이터베이스에 새 테이블을 만듭니다.
- 테이블에 데이터 삽입
- 삽입된 데이터 보기
- NOT IN 연산자를 사용하여 데이터를 봅니다.
이제 최고의 SQL 예제를 통해 각 단계를 하나씩 간략하게 설명하겠습니다.
1단계: 간단한 새 데이터베이스 만들기
다음 쿼리는 새 토목_산업 SQL 서버의 데이터베이스:
CREATE Database Industry;
2단계: 새 테이블 만들기
다음 쿼리는 작업자_정보 테이블에 토목_산업 데이터 베이스:
CREATE TABLE Worker_Info ( Worker_ID INT NOT NULL PRIMARY KEY, Worker_Name VARCHAR (100), Worker_Gender Varchar(20), Worker_Age INT NOT NULL DEFAULT 18, Worker_Address Varchar (80), Worker_Salary INT NOT NULL );
3단계: 값 삽입
다음 INSERT 쿼리는 Worker_Info 테이블에 작업자의 레코드를 삽입합니다.
INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1001, Arush, Male, Agra, 35000); INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1002, Bulbul, Female, Lucknow, 42000); INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1004, Saurabh, Male, 20, Lucknow, 45000); INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1005, Shivani, Female, Agra, 28000); INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1006, Avinash, Male, 22, Delhi, 38000); INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1007, Shyam, Male, Banglore, 20000);
4단계: 테이블 데이터 보기
다음 쿼리는 Worker_Info 테이블의 데이터를 표시합니다.
SELECT * FROM Worker_Info;
| 작업자_ID | 작업자_이름 | 근로자_성별 | 근로자_나이 | 근로자_주소 | 근로자_급여 |
|---|---|---|---|---|---|
| 1001 | 곰 | 남성 | 18 | 아그라 | 35000 |
| 1002 | 불불 | 여성 | 18 | 러크나우 | 42000 |
| 1004 | 사우라브 | 남성 | 이십 | 러크나우 | 45000 |
| 1005 | 시바니 | 여성 | 18 | 아그라 | 28000 |
| 1006 | 아비나쉬 | 남성 | 22 | 델리 | 38000 |
| 1007 | 샤암 | 남성 | 18 | 방갈로르 | 20000 |
4단계: NOT IN 연산자 사용
다음 쿼리에서는 숫자 데이터에 NOT IN 연산자를 사용합니다.
SELECT * FROM Worker_Info WHERE Worker_salary NOT IN (35000, 28000, 38000);
이 SELECT 쿼리는 급여가 NOT IN 연산자로 전달되지 않은 모든 근로자를 출력에 표시합니다.
위 명령문의 결과는 다음 표에 나와 있습니다.
자바 객체 평등
| 작업자_ID | 작업자_이름 | 근로자_성별 | 근로자_나이 | 근로자_주소 | 근로자_급여 |
|---|---|---|---|---|---|
| 1002 | 불불 | 여성 | 18 | 러크나우 | 42000 |
| 1004 | 사우라브 | 남성 | 이십 | 러크나우 | 45000 |
| 1007 | 샤암 | 남성 | 18 | 방갈로르 | 20000 |
다음 쿼리는 문자 또는 텍스트 값과 함께 NOT IN 논리 연산자를 사용합니다.
SELECT * FROM Worker_Info WHERE Worker_Address NOT IN (Lucknow, Delhi);
이 쿼리는 주소가 NOT IN 연산자에 전달되지 않은 모든 작업자의 기록을 보여줍니다.
산출:
| 작업자_ID | 작업자_이름 | 근로자_성별 | 근로자_나이 | 근로자_주소 | 근로자_급여 |
|---|---|---|---|---|---|
| 1001 | 곰 | 남성 | 18 | 아그라 | 35000 |
| 1005 | 시바니 | 여성 | 18 | 아그라 | 28000 |
| 1007 | 샤암 | 남성 | 18 | 방갈로르 | 20000 |