프로세스에는 두 가지 유형이 있습니다.
- 독립적인 프로세스.
- 협력 프로세스.
독립 프로세스는 다른 프로세스의 실행에 영향을 받지 않지만 협력 프로세스는 다른 실행 프로세스의 영향을 받을 수 있습니다. 독립적으로 실행되는 프로세스는 매우 효율적으로 실행될 것이라고 생각할 수 있지만 실제로는 계산 속도, 편의성 및 모듈성을 높이기 위해 협동적 성격을 활용할 수 있는 상황이 많이 있습니다. IPC(프로세스 간 통신)는 프로세스가 서로 통신하고 작업을 동기화할 수 있도록 하는 메커니즘입니다. 이러한 프로세스 간의 커뮤니케이션은 프로세스 간의 협력 방법으로 볼 수 있습니다. 프로세스는 다음 두 가지를 통해 서로 통신할 수 있습니다.
- 공유 메모리
- 메시지 전달
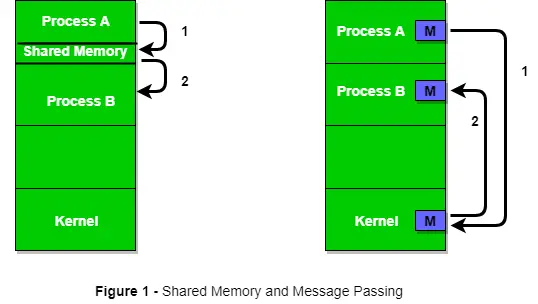
아래 그림 1은 공유 메모리 방식과 메시지 전달 방식을 통한 프로세스 간 통신의 기본 구조를 보여줍니다.
운영 체제는 두 가지 통신 방법을 모두 구현할 수 있습니다. 먼저, 공유 메모리 통신 방법과 메시지 전달 방법에 대해 논의하겠습니다. 공유 메모리를 사용하는 프로세스 간 통신에는 프로세스가 일부 변수를 공유해야 하며 이는 전적으로 프로그래머가 이를 구현하는 방법에 따라 달라집니다. 공유 메모리를 사용하는 한 가지 통신 방법은 다음과 같이 상상할 수 있습니다. process1과 process2가 동시에 실행되고 있고 일부 리소스를 공유하거나 다른 프로세스의 일부 정보를 사용한다고 가정합니다. Process1은 사용 중인 특정 계산이나 리소스에 대한 정보를 생성하고 이를 공유 메모리에 기록으로 유지합니다. process2가 공유 정보를 사용해야 할 경우 공유 메모리에 저장된 레코드를 확인하고 process1에서 생성된 정보를 기록하고 그에 따라 조치를 취합니다. 프로세스는 공유 메모리를 사용하여 다른 프로세스의 레코드로 정보를 추출하고 특정 정보를 다른 프로세스에 전달할 수 있습니다.
공유 메모리 방식을 사용한 프로세스 간 통신의 예를 살펴보겠습니다.
i) 공유 메모리 방식
예: 생산자-소비자 문제
생산자와 소비자라는 두 가지 프로세스가 있습니다. 생산자는 일부 품목을 생산하고 소비자는 해당 품목을 소비합니다. 두 프로세스는 생산자가 생산한 항목이 저장되고 소비자가 필요한 경우 항목을 소비하는 버퍼라고 알려진 공통 공간 또는 메모리 위치를 공유합니다. 이 문제에는 두 가지 버전이 있습니다. 첫 번째는 생산자가 항목을 계속 생산할 수 있고 버퍼 크기에 제한이 없는 무한 버퍼 문제로 알려져 있으며, 두 번째는 제한된 버퍼 문제로 알려져 있습니다. 생산자는 소비자가 소비하기를 기다리기 전에 특정 수의 품목을 생산할 수 있습니다. 제한된 버퍼 문제에 대해 논의하겠습니다. 먼저 생산자와 소비자가 공통 메모리를 공유한 다음 생산자가 아이템 생산을 시작합니다. 생산된 총 항목이 버퍼 크기와 같으면 생산자는 소비자가 해당 항목을 소비할 때까지 기다립니다. 마찬가지로 소비자는 먼저 품목의 가용성을 확인합니다. 사용할 수 있는 항목이 없으면 소비자는 생산자가 해당 항목을 생산할 때까지 기다립니다. 사용 가능한 항목이 있으면 소비자는 해당 항목을 소비합니다. 시연할 의사 코드는 다음과 같습니다.
두 프로세스 간의 공유 데이터
씨
#define buff_max 25> #define mod %> >struct> item{> >// different member of the produced data> >// or consumed data> >---------> >}> > >// An array is needed for holding the items.> >// This is the shared place which will be> >// access by both process> >// item shared_buff [ buff_max ];> > >// Two variables which will keep track of> >// the indexes of the items produced by producer> >// and consumer The free index points to> >// the next free index. The full index points to> >// the first full index.> >int> free_index = 0;> >int> full_index = 0;> > |
>
>
생산자 프로세스 코드
씨
item nextProduced;> > >while>(1){> > >// check if there is no space> >// for production.> >// if so keep waiting.> >while>((free_index+1) mod buff_max == full_index);> > >shared_buff[free_index] = nextProduced;> >free_index = (free_index + 1) mod buff_max;> >}> |
>
>
소비자 프로세스 코드
씨
item nextConsumed;> > >while>(1){> > >// check if there is an available> >// item for consumption.> >// if not keep on waiting for> >// get them produced.> >while>((free_index == full_index);> > >nextConsumed = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >}> |
>
>
위 코드에서 생산자는 (free_index+1) 모드 버프 최대값이 무료가 될 때 다시 생산을 시작합니다. 왜냐하면 그것이 무료가 아닌 경우 이는 여전히 소비자가 소비할 수 있는 항목이 있으므로 필요가 없음을 의미하기 때문입니다. 더 많은 것을 생산하기 위해. 마찬가지로, 여유 인덱스와 전체 인덱스가 동일한 인덱스를 가리키는 경우 소비할 항목이 없음을 의미합니다.
전반적인 C++ 구현:
C++
#include> #include> #include> #include> #define buff_max 25> #define mod %> struct> item {> >// different member of the produced data> >// or consumed data> >// ---------> };> // An array is needed for holding the items.> // This is the shared place which will be> // access by both process> // item shared_buff[buff_max];> // Two variables which will keep track of> // the indexes of the items produced by producer> // and consumer The free index points to> // the next free index. The full index points to> // the first full index.> std::atomic<>int>>free_index(0);> std::atomic<>int>>전체 인덱스(0);> std::mutex mtx;> void> producer() {> >item new_item;> >while> (>true>) {> >// Produce the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >// Add the item to the buffer> >while> (((free_index + 1) mod buff_max) == full_index) {> >// Buffer is full, wait for consumer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Add the item to the buffer> >// shared_buff[free_index] = new_item;> >free_index = (free_index + 1) mod buff_max;> >mtx.unlock();> >}> }> void> consumer() {> >item consumed_item;> >while> (>true>) {> >while> (free_index == full_index) {> >// Buffer is empty, wait for producer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Consume the item from the buffer> >// consumed_item = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >mtx.unlock();> >// Consume the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> }> int> main() {> >// Create producer and consumer threads> >std::vectorthread>스레드; thread.emplace_back(생산자); thread.emplace_back(소비자); // 스레드가 완료될 때까지 기다립니다. for (auto& thread : thread) { thread.join(); } 0을 반환합니다. }> |
>
>
js 여러 줄 문자열
원자 클래스는 공유 변수 free_index 및 full_index가 원자적으로 업데이트되는지 확인하는 데 사용됩니다. 뮤텍스는 공유 버퍼에 액세스하는 중요 섹션을 보호하는 데 사용됩니다. sleep_for 함수는 아이템의 생산과 소비를 시뮬레이션하는 데 사용됩니다.
ii) 메시지 전달 방법
이제 메시지 전달을 통한 프로세스 간 통신에 대한 논의를 시작하겠습니다. 이 방법에서는 프로세스가 어떤 종류의 공유 메모리도 사용하지 않고 서로 통신합니다. 두 프로세스 p1과 p2가 서로 통신하려는 경우 다음과 같이 진행됩니다.
- 통신 링크를 설정합니다. (링크가 이미 존재하는 경우 다시 설정할 필요가 없습니다.)
- 기본 프리미티브를 사용하여 메시지 교환을 시작합니다.
최소한 두 개의 기본 요소가 필요합니다.
– 보내다 (메시지, 대상) 또는 보내다 (메시지)
– 받다 (메시지, 호스트) 또는 받다 (메시지)

메시지 크기는 고정된 크기이거나 가변적인 크기일 수 있습니다. 크기가 고정되면 OS 설계자에게는 쉽지만 프로그래머에게는 복잡하고, 가변 크기이면 프로그래머에게는 쉽지만 OS 설계자에게는 복잡합니다. 표준 메시지는 두 부분으로 구성될 수 있습니다. 헤더와 본문.
그만큼 헤더 부분 메시지 유형, 대상 ID, 소스 ID, 메시지 길이 및 제어 정보를 저장하는 데 사용됩니다. 제어 정보에는 버퍼 공간 부족 시 수행 방법, 시퀀스 번호, 우선 순위 등의 정보가 포함됩니다. 일반적으로 메시지는 FIFO 스타일을 사용하여 전송됩니다.
통신 링크를 통한 메시지 전달.
직접 및 간접 커뮤니케이션 링크
이제 통신 링크를 구현하는 방법에 대한 논의를 시작하겠습니다. 링크를 구현하는 동안 다음과 같이 염두에 두어야 할 몇 가지 질문이 있습니다.
- 링크는 어떻게 설정되나요?
- 하나의 링크가 2개 이상의 프로세스와 연결될 수 있습니까?
- 모든 통신 프로세스 쌍 사이에는 몇 개의 링크가 있을 수 있습니까?
- 링크의 용량은 얼마입니까? 링크가 수용할 수 있는 메시지의 크기는 고정되어 있나요, 아니면 가변적인가요?
- 링크는 단방향인가요, 아니면 양방향인가요?
링크에는 일시적으로 상주할 수 있는 메시지 수를 결정하는 일부 용량이 있으며, 모든 링크에는 용량이 0, 제한된 용량 또는 무제한 용량일 수 있는 대기열이 연결되어 있습니다. 용량이 0인 경우 보낸 사람은 받는 사람이 보낸 사람에게 메시지를 받았다고 알릴 때까지 기다립니다. 용량이 0이 아닌 경우 프로세스는 전송 작업 후에 메시지가 수신되었는지 여부를 알 수 없습니다. 이를 위해서는 송신자가 수신자와 명시적으로 통신해야 합니다. 링크의 구현은 상황에 따라 다르며 직접 통신 링크일 수도 있고 간접 통신 링크일 수도 있습니다.
직접 커뮤니케이션 링크 프로세스가 통신을 위해 특정 프로세스 식별자를 사용하는 경우 구현되지만 보낸 사람을 미리 식별하기가 어렵습니다.
예를 들어 인쇄 서버.
간접 커뮤니케이션 이는 메시지 대기열로 구성된 공유 사서함(포트)을 통해 수행됩니다. 보낸 사람은 메시지를 사서함에 보관하고 받는 사람은 메시지를 가져옵니다.
메시지 교환을 통한 메시지 전달.
동기식 및 비동기식 메시지 전달:
차단된 프로세스는 리소스를 사용할 수 있게 되거나 I/O 작업이 완료되는 등의 일부 이벤트를 기다리는 프로세스입니다. IPC는 동일한 컴퓨터의 프로세스뿐만 아니라 다른 컴퓨터(예: 네트워크/분산 시스템)에서 실행되는 프로세스 간에도 가능합니다. 두 경우 모두 메시지를 보내거나 메시지를 받으려고 시도하는 동안 프로세스가 차단되거나 차단되지 않을 수 있으므로 메시지 전달이 차단되거나 차단되지 않을 수 있습니다. 차단이 고려됩니다 동기식 그리고 보내기 차단 수신자가 메시지를 수신할 때까지 발신자가 차단된다는 의미입니다. 비슷하게, 수신 차단 메시지를 사용할 수 있을 때까지 수신자를 차단합니다. 비차단이 고려됩니다. 비동기식 비차단 전송은 발신자가 메시지를 보내고 계속하도록 합니다. 마찬가지로 비차단 수신은 수신자가 유효한 메시지 또는 null을 수신하도록 합니다. 주의 깊게 분석한 후 메시지를 다른 프로세스로 보내야 할 수 있으므로 보낸 사람의 경우 메시지 전달 후 비차단을 수행하는 것이 더 자연스럽다는 결론에 도달할 수 있습니다. 그러나 발신자는 전송이 실패할 경우 수신자로부터 승인을 기대합니다. 마찬가지로 수신된 메시지의 정보가 추가 실행에 사용될 수 있으므로 수신자가 수신을 발행한 후 차단하는 것이 더 자연스럽습니다. 동시에 메시지 전송이 계속 실패하면 수신자는 무기한 기다려야 합니다. 이것이 바로 우리가 메시지 전달의 다른 가능성도 고려하는 이유입니다. 기본적으로 선호되는 세 가지 조합이 있습니다.
- 보내기 차단 및 수신 차단
- 비차단 송신 및 비차단 수신
- Non-Blocking 송신 및 Blocking 수신(주로 사용됨)
다이렉트 메시지 전달 중 , 통신하려는 프로세스는 통신의 수신자 또는 발신자를 명시적으로 지정해야 합니다.
예를 들어 보내기(p1, 메시지) p1에 메시지를 보내는 것을 의미합니다.
비슷하게, 수신(p2, 메시지) p2로부터 메시지를 수신한다는 의미입니다.
이 통신 방법에서는 통신 링크가 자동으로 설정되며 단방향 또는 양방향이 될 수 있지만 한 쌍의 송신자와 수신자 사이에는 하나의 링크가 사용될 수 있으며 한 쌍의 송신자와 수신자는 한 쌍 이상의 링크를 소유할 수 없습니다. 연결. 보내기와 받기 사이의 대칭과 비대칭도 구현될 수 있습니다. 즉, 두 프로세스가 메시지를 보내고 받기 위해 서로 이름을 지정하거나 보낸 사람만 메시지 보내기에 받는 사람의 이름을 지정하고 받는 사람이 보낸 사람의 이름을 지정할 필요가 없습니다. 메시지를 받고 있습니다. 이 통신 방법의 문제점은 한 프로세스의 이름이 변경되면 이 방법이 작동하지 않는다는 것입니다.
간접 메시지 전달에서 , 프로세스는 메시지를 보내고 받기 위해 사서함(포트라고도 함)을 사용합니다. 각 사서함에는 고유한 ID가 있으며 프로세스는 사서함을 공유하는 경우에만 통신할 수 있습니다. 프로세스가 공통 사서함을 공유하고 단일 링크가 여러 프로세스와 연결될 수 있는 경우에만 링크가 설정됩니다. 각 프로세스 쌍은 여러 통신 링크를 공유할 수 있으며 이러한 링크는 단방향이거나 양방향일 수 있습니다. 두 프로세스가 간접 메시지 전달을 통해 통신하기를 원한다고 가정하면 필요한 작업은 사서함을 만들고 이 사서함을 메시지 전송 및 수신에 사용한 다음 사서함을 삭제하는 것입니다. 사용되는 표준 기본 요소는 다음과 같습니다. 메세지를 보내다) 이는 메시지를 사서함 A로 보내는 것을 의미합니다. 메시지 수신을 위한 기본 요소도 같은 방식으로 작동합니다. 수신됨(A, 메시지) . 이 사서함 구현에 문제가 있습니다. 동일한 사서함을 공유하는 프로세스가 두 개 이상 있고 프로세스 p1이 사서함에 메시지를 보낸다고 가정하면 어느 프로세스가 수신자가 될까요? 이 문제는 두 개의 프로세스만 단일 사서함을 공유할 수 있도록 하거나, 주어진 시간에 하나의 프로세스만 수신을 실행할 수 있도록 하거나, 임의의 프로세스를 무작위로 선택하여 보낸 사람에게 수신자에 대해 알리는 방식으로 해결할 수 있습니다. 사서함은 단일 발신자/수신자 쌍에 대해 비공개로 설정될 수 있으며 여러 발신자/수신자 쌍 간에 공유될 수도 있습니다. 포트는 여러 발신자와 단일 수신자를 가질 수 있는 사서함의 구현입니다. 클라이언트/서버 애플리케이션에서 사용됩니다(이 경우 서버가 수신자임). 포트는 수신 프로세스가 소유하고 수신 프로세스의 요청에 따라 OS에서 생성되며 수신자가 자체 종료될 때 동일한 수신 프로세서의 요청에 따라 삭제될 수 있습니다. 하나의 프로세스만 수신을 실행할 수 있도록 강제하는 것은 상호 배제 개념을 사용하여 수행할 수 있습니다. 뮤텍스 사서함 n 프로세스에서 공유되는 생성됩니다. 보낸 사람은 차단되지 않고 메시지를 보냅니다. 수신을 실행하는 첫 번째 프로세스는 임계 섹션에 들어가고 다른 모든 프로세스는 차단되고 대기합니다.
이제 메시지 전달 개념을 사용하여 생산자-소비자 문제를 논의해 보겠습니다. 생산자는 사서함에 항목(메시지 내부)을 배치하고 소비자는 사서함에 메시지가 하나 이상 있을 때 항목을 소비할 수 있습니다. 코드는 아래와 같습니다:
생산자 코드
씨
void> Producer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Consumer, &m);> >item = produce();> >build_message(&m , item ) ;> >send(Consumer, &m);> >}> >}> |
>
>
소비자 코드
씨
void> Consumer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Producer, &m);> >item = extracted_item();> >send(Producer, &m);> >consume_item(item);> >}> >}> |
>
>
IPC 시스템의 예
- Posix : 공유 메모리 방식을 사용합니다.
- Mach : 메시지 전달을 사용합니다.
- Windows XP: 로컬 절차 호출을 사용한 메시지 전달을 사용합니다.
클라이언트/서버 아키텍처의 통신:
다양한 메커니즘이 있습니다:
- 파이프
- 소켓
- RPC(원격 절차 호출)
위의 세 가지 방법은 모두 매우 개념적이며 별도의 기사를 작성할 가치가 있으므로 이후 기사에서 논의될 것입니다.
참고자료:
- Galvin 등의 운영 체제 개념
- Bar-Ilan University Ariel J. Frank의 강의 노트/ppt
IPC(프로세스 간 통신)는 프로세스나 스레드가 컴퓨터나 네트워크를 통해 서로 통신하고 데이터를 교환할 수 있는 메커니즘입니다. IPC는 다양한 프로세스가 함께 작동하고 리소스를 공유할 수 있게 하여 효율성과 유연성을 향상시키므로 최신 운영 체제의 중요한 측면입니다.
IPC의 장점:
- 프로세스가 서로 통신하고 리소스를 공유할 수 있도록 하여 효율성과 유연성을 향상시킵니다.
- 여러 프로세스 간의 조정을 촉진하여 전반적인 시스템 성능을 향상시킵니다.
- 여러 컴퓨터 또는 네트워크에 걸쳐 있을 수 있는 분산 시스템을 생성할 수 있습니다.
- 세마포어, 파이프, 소켓 등 다양한 동기화 및 통신 프로토콜을 구현하는 데 사용할 수 있습니다.
IPC의 단점:
- 시스템 복잡성이 증가하여 설계, 구현 및 디버그가 더 어려워집니다.
- 프로세스가 다른 프로세스에 속한 데이터에 액세스하거나 수정할 수 있으므로 보안 취약점이 발생할 수 있습니다.
- IPC 작업으로 인해 전체 시스템 성능이 저하되지 않도록 메모리 및 CPU 시간과 같은 시스템 리소스를 주의 깊게 관리해야 합니다.
여러 프로세스가 동시에 동일한 데이터에 액세스하거나 수정하려고 하면 데이터 불일치가 발생할 수 있습니다. - 전반적으로 IPC는 현대 운영 체제에 필요한 메커니즘이고 프로세스가 함께 작동하고 유연하고 효율적인 방식으로 리소스를 공유할 수 있도록 하므로 단점보다 장점이 더 큽니다. 그러나 잠재적인 보안 취약성과 성능 문제를 방지하려면 IPC 시스템을 신중하게 설계하고 구현하는 데 주의를 기울여야 합니다.
추가 참조:
http://nptel.ac.in/courses/106108101/pdf/Lecture_Notes/Mod%207_LN.pdf
https://www.youtube.com/watch?v=lcRqHwIn5Dk