선형 회귀 및 로지스틱 회귀는 지도 학습 기술을 사용하는 두 가지 유명한 기계 학습 알고리즘입니다. 두 알고리즘 모두 본질적으로 감독되므로 이러한 알고리즘은 레이블이 지정된 데이터 세트를 사용하여 예측을 수행합니다. 그러나 이들 사이의 주요 차이점은 사용 방법입니다. 선형 회귀는 회귀 문제를 해결하는 데 사용되는 반면 로지스틱 회귀는 분류 문제를 해결하는 데 사용됩니다. 두 알고리즘에 대한 설명은 차이점 표와 함께 아래에 제공됩니다.
선형 회귀:
- 선형 회귀는 지도 학습 기술에 포함되고 회귀 문제를 해결하는 데 사용되는 가장 간단한 기계 학습 알고리즘 중 하나입니다.
- 독립변수의 도움으로 연속형 종속변수를 예측하는 데 사용됩니다.
- 선형 회귀의 목표는 연속 종속 변수의 출력을 정확하게 예측할 수 있는 최적의 선을 찾는 것입니다.
- 단일 독립변수를 사용하여 예측하는 경우를 단순선형회귀라고 하고, 독립변수가 2개 이상인 경우 이러한 회귀를 다중선형회귀라고 합니다.
- 알고리즘은 가장 적합한 선을 찾아 종속 변수와 독립 변수 간의 관계를 설정합니다. 그리고 그 관계는 선형적 성격을 띠어야 합니다.
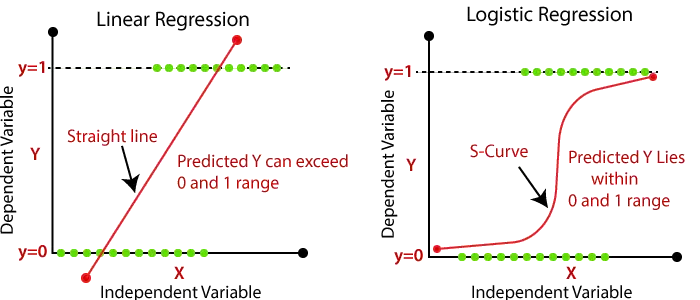
- 선형 회귀의 출력은 가격, 연령, 급여 등과 같은 연속 값이어야 합니다. 종속 변수와 독립 변수 간의 관계는 아래 이미지에 표시될 수 있습니다.

위 이미지에서 종속변수는 Y축(급여)에 있고 독립변수는 X축(경험)에 있습니다. 회귀선은 다음과 같이 작성할 수 있습니다.
y= a<sub>0</sub>+a<sub>1</sub>x+ ε
어디서,0그리고1는 계수이고 ε은 오류항입니다.
로지스틱 회귀:
- 로지스틱 회귀는 지도 학습 기술에 포함되는 가장 널리 사용되는 기계 학습 알고리즘 중 하나입니다.
- 회귀 문제뿐만 아니라 분류 문제에도 사용할 수 있지만 주로 분류 문제에 사용됩니다.
- 로지스틱 회귀 분석은 독립 변수의 도움으로 범주형 종속 변수를 예측하는 데 사용됩니다.
- 로지스틱 회귀 문제의 출력은 0과 1 사이에서만 가능합니다.
- 두 클래스 간의 확률이 필요한 경우 로지스틱 회귀를 사용할 수 있습니다. 예를 들어 오늘 비가 올지 여부, 0 또는 1, 참 또는 거짓 등입니다.
- 로지스틱 회귀는 최대 우도 추정 개념을 기반으로 합니다. 이 추정에 따르면 관측된 데이터는 가장 가능성이 높습니다.
- 로지스틱 회귀에서는 0과 1 사이의 값을 매핑할 수 있는 활성화 함수를 통해 입력의 가중 합계를 전달합니다. 이러한 활성화 함수는 다음과 같습니다. 시그모이드 함수 그리고 얻은 곡선을 시그모이드 곡선 또는 S-곡선이라고 합니다. 아래 이미지를 고려하십시오.

- 로지스틱 회귀 방정식은 다음과 같습니다.

선형 회귀와 로지스틱 회귀의 차이점:
| 선형 회귀 | 로지스틱 회귀 |
|---|---|
| 선형 회귀는 주어진 독립 변수 세트를 사용하여 연속 종속 변수를 예측하는 데 사용됩니다. | 로지스틱 회귀 분석은 주어진 독립 변수 세트를 사용하여 범주형 종속 변수를 예측하는 데 사용됩니다. |
| 선형 회귀는 회귀 문제를 해결하는 데 사용됩니다. | 로지스틱 회귀는 분류 문제를 해결하는 데 사용됩니다. |
| 선형 회귀에서는 연속 변수의 값을 예측합니다. | 로지스틱 회귀 분석에서는 범주형 변수의 값을 예측합니다. |
| 선형 회귀에서는 출력을 쉽게 예측할 수 있는 가장 적합한 선을 찾습니다. | 로지스틱 회귀 분석에서는 샘플을 분류할 수 있는 S-곡선을 찾습니다. |
| 정확도를 추정하기 위해 최소제곱 추정법을 사용합니다. | 정확도 추정을 위해 최대 우도 추정 방법이 사용됩니다. |
| 선형 회귀의 출력은 가격, 연령 등과 같은 연속 값이어야 합니다. | 로지스틱 회귀 분석의 출력은 0 또는 1, 예 또는 아니요 등과 같은 범주형 값이어야 합니다. |
| 선형회귀에서는 종속변수와 독립변수의 관계가 선형이어야 합니다. | 로지스틱 회귀 분석에서는 종속 변수와 독립 변수 사이에 선형 관계가 필요하지 않습니다. |
| 선형 회귀 분석에서는 독립 변수 사이에 공선성이 있을 수 있습니다. | 로지스틱 회귀 분석에서는 독립 변수 간에 공선성이 없어야 합니다. |