Linux uniq 명령은 파일에서 반복되는 모든 줄을 제거하는 데 사용됩니다. 또한 단어 수, 반복되는 줄만 표시하고 문자를 무시하고 특정 필드를 비교하는 데 사용할 수 있습니다. 에서 가장 자주 사용되는 명령 중 하나입니다. 리눅스 체계. 그것은 종종 다음과 함께 사용됩니다. 정렬 명령 인접한 문자를 비교하기 때문입니다. 동일한 줄을 모두 버리고 출력을 씁니다.
통사론:
uniq [OPTION]... [INPUT [OUTPUT]]
옵션:
uniq 명령의 몇 가지 유용한 명령줄 옵션은 다음과 같습니다:
-c, --count: 발생 횟수만큼 줄 앞에 붙습니다.
-d, --반복: 이는 각 그룹마다 하나씩 중복 행을 인쇄하는 데 사용됩니다.
-디: 모든 중복 라인을 인쇄하는 데 사용됩니다.
--모두 반복[=방법]: 이는 '-D' 옵션과 매우 유사합니다. 두 옵션의 차이점은 빈 줄을 사용하여 그룹을 구분할 수 있다는 것입니다.
-f, --skip-필드=N: 처음 N개 필드의 비교를 피하기 위해 사용됩니다.
--그룹[=방법]: 모든 항목을 표시하는 데 사용되며 빈 줄로 그룹을 구분합니다.
-i, --ignore-case: 비교할 때 차이점을 무시하는 데 사용됩니다.
-s, --skip-chars=N: 처음 N 문자의 비교를 피하기 위해 사용됩니다.
-u, --고유: 고유한 라인을 인쇄하는 데 사용됩니다.
-z, --제로 종료: 줄 구분 기호가 NUL이고 개행 모드가 아닌 경우에 사용됩니다.
JSON 파일 읽기
-w, --check-chars=N: 한 줄에서 N개 이하의 문자를 비교하는 데 사용됩니다.
--돕다: 도움말 문서를 표시하는 데 사용됩니다.
--버전: 버전 정보를 표시하는데 사용됩니다.
uniq 명령의 예
uniq 명령의 다음 예를 살펴보겠습니다.
디렉토리 이름 바꾸기 리눅스
반복되는 줄 제거
파일에서 반복되는 줄을 제거하려면 다음과 같이 기본 uniq 명령을 실행하십시오.
sort dupli.txt | uniq
위 명령은 'dupli.txt' 파일에서 중복된 줄을 제거합니다. 아래 출력을 고려하십시오.
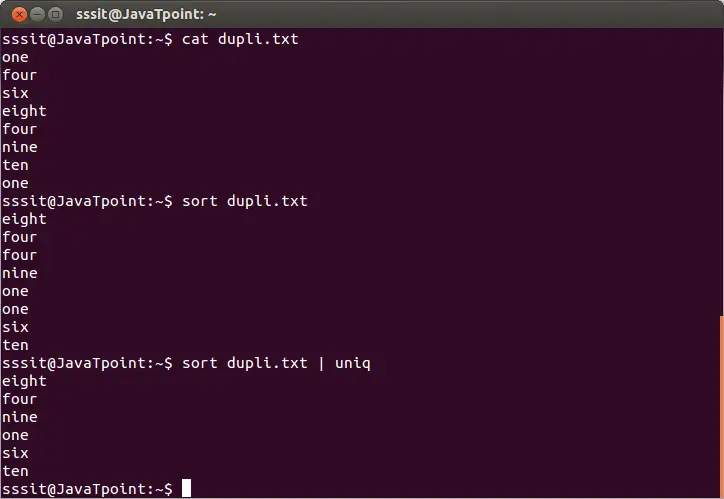
위 출력에서 반복되는 단어는 무시됩니다.
단어의 발생 횟수 계산
uniq 명령을 사용하면 단어가 나타나는 횟수를 셀 수 있습니다. '-c' 옵션은 단어 수를 계산하는 데 사용됩니다. 다음과 같이 실행하세요:
sort dupli.txt | uniq -c
위 명령은 'dupli.txt'에 포함된 단어 수를 계산합니다. 아래 출력을 고려하십시오.

위 출력에서 'sort dupli.txt | uniq -c'는 단어가 반복되는 횟수를 계산합니다.
반복되는 줄 표시
'-d' 옵션은 반복되는 행만 표시하는 데 사용됩니다. 파일에 두 번 이상 있을 줄만 표시하고 출력을 표준 출력에 씁니다. 아래 명령을 고려하십시오.
sort dupli.txt | uniq -d
위 명령은 반복되는 행만 표시합니다. 아래 출력을 고려하십시오.

고유 라인 표시
'-u' 옵션은 (반복되지 않는) 고유한 줄만 표시하는 데 사용됩니다. 한 번만 발생하는 행만 표시하고 결과를 표준 출력에 기록합니다. 아래 명령을 고려하십시오.
sort dupli.txt | uniq -u
위 명령은 'dupli.txt' 파일의 고유한 줄만 표시합니다. 아래 출력을 고려하십시오.

비교에서 문자 무시
'-s' 옵션은 비교에서 문자를 무시하는 데 사용됩니다. 지정된 문자 수를 무시하고 결과를 표준 출력에 표시합니다. 아래 명령을 고려하십시오.
sort dupli.txt | uniq -s 2
위 명령은 'dupli.txt' 파일과 비교할 때 처음 두 문자를 무시합니다. 아래 출력을 고려하십시오.

비교에서 필드 무시
'-f' 옵션은 필드를 무시하는 데 사용됩니다. 아래 명령을 고려하십시오.
uniq -f 2 dupli2.txt
위 명령은 'dupli2.txt' 파일의 처음 두 필드를 비교하지 않습니다. 아래 출력을 고려하십시오.

위 출력에서 처음 두 필드는 건너뛰고 나머지 모든 필드는 'dupli2.txt' 파일에서 비교됩니다.