팬더 데이터프레임.corr() Python의 Pandas Dataframe에 있는 모든 열의 쌍별 상관 관계를 찾는 데 사용됩니다. 어느 NaN 값은 자동으로 제외됩니다. 숫자가 아닌 값을 무시하려면 숫자만 = True 매개변수를 사용하십시오. 이번 글에서는 DataFrame.corr() 메소드에 대해 알아보겠습니다. 파이썬 .
Pandas DataFrame corr() 메서드 구문
통사론: DataFrame.corr(self, 메소드='pearson', min_기간=1, 숫자_전용 = False)
매개변수:
- 방법 :
- 피어슨: 표준 상관 계수
- kendall: Kendall Tau 상관계수
- 스피어맨: 스피어맨 순위 상관관계
- 최소 기간: 유효한 결과를 얻으려면 열 쌍당 필요한 최소 관찰 수입니다. 현재 Pearson 및 Spearman 상관관계에만 사용할 수 있습니다.
- 숫자_전용 : 숫자 값만 연산할지 여부입니다. 기본적으로 False로 설정되어 있습니다.
보고: 개수 :y : 데이터프레임
Pandas 데이터 상관 관계 corr() 메서드
좋은 상관관계는 용도에 따라 다르지만, 좋은 상관관계라고 부르려면 최소 0.6(또는 -0.6)이 있다고 해도 무방합니다. 상관 관계가 어떻게 작동하는지 보여주는 간단한 예 파이썬 .
파이썬3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
자바 형식 문자열
산출
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
샘플 데이터프레임 생성
데이터프레임의 처음 10개 행을 인쇄합니다.
메모: 변수 자체와의 상관 관계는 1입니다. 코드에 사용된 CSV 파일에 대한 링크를 보려면 여기
파이썬3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
산출

Python Pandas DataFrame corr() 메서드 예
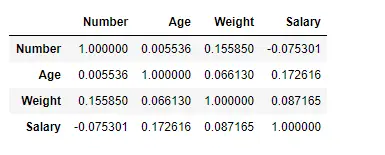
피어슨 방법을 사용하여 열 간의 상관 관계 찾기
여기서는 corr() 함수를 사용하여 'Pearson' 메서드를 사용하여 데이터프레임의 열 간의 상관관계를 찾습니다. 데이터프레임에는 숫자 열이 4개만 있습니다. 출력 데이터 프레임은 모든 셀에 대해 해석될 수 있으며, 열 변수와의 행 변수 상관 관계는 셀 값입니다. 앞서 언급했듯이 변수 자체와의 상관관계는 1입니다. 따라서 모든 대각선 값은 1.00입니다.
파이썬3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
산출
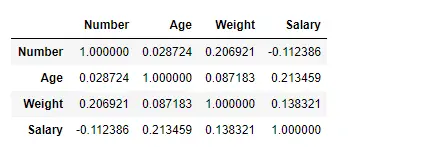
Kendall 방법을 사용하여 열 간의 상관 관계 찾기
Pandas df.corr() 함수를 사용하여 'kendall' 메서드를 사용하여 데이터 프레임의 열 간의 상관 관계를 찾습니다. 출력 데이터 프레임은 모든 셀에 대해 해석될 수 있으며, 열 변수와의 행 변수 상관 관계는 셀 값입니다. 앞서 언급했듯이 변수 자체와의 상관관계는 1입니다. 따라서 모든 대각선 값은 1.00입니다.
파이썬3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
>
산출