IDENTITY 키워드는 SQL Server의 속성입니다. 테이블 열이 ID 속성으로 정의되면 해당 값은 자동 생성된 증분 값이 됩니다. . 이 값은 서버에서 자동으로 생성됩니다. 따라서 사용자로서 ID 열에 값을 수동으로 입력할 수 없습니다. 따라서 열을 ID로 표시하면 SQL Server는 자동 증가 방식으로 해당 열을 채웁니다.
통사론
다음은 SQL Server에서 IDENTITY 속성의 사용을 설명하는 구문입니다.
IDENTITY[(seed, increment)]
위의 구문 매개변수는 아래에 설명되어 있습니다.
간단한 예를 통해 이 개념을 이해해 보겠습니다.
우리가 ' 학생 ' 테이블, 그리고 우리는 원한다 학생 아이디 자동으로 생성됩니다. 우리는 초등학생증 10이며 새 ID마다 1씩 늘리고 싶습니다. 이 시나리오에서는 다음 값을 정의해야 합니다.
씨앗: 10
증가: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
참고: SQL Server에서는 테이블당 하나의 식별 열만 허용됩니다.
SQL Server ID 예
테이블에서 ID 속성을 어떻게 사용할 수 있는지 살펴보겠습니다. 열의 ID 속성은 새 테이블을 만들 때나 만든 후에 설정할 수 있습니다. 여기서는 두 가지 사례를 모두 예제와 함께 살펴보겠습니다.
새 테이블이 있는 IDENTITY 속성
다음 명령문은 ID 속성을 사용하여 지정된 데이터베이스에 새 테이블을 생성합니다.
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
다음으로 이 테이블에 새 행을 삽입합니다. 산출 자동 생성된 개인 ID를 확인하는 절:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
이 쿼리를 실행하면 아래 출력이 표시됩니다.
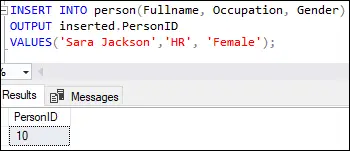
이 출력은 첫 번째 행이 값 10으로 삽입되었음을 보여줍니다. 개인ID 테이블 정의 ID 열에 지정된 열입니다.
다른 행을 삽입해 보겠습니다. 사람 테이블 아래:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
이 쿼리는 다음 출력을 반환합니다.

이 출력은 PersonID 열에 값 11이 있는 두 번째 행과 값 12가 있는 세 번째 행이 삽입되었음을 보여줍니다.
기존 테이블이 있는 IDENTITY 속성
먼저 위의 테이블을 삭제하고 아이덴티티 속성 없이 생성하여 이 개념을 설명하겠습니다. 아래 명령문을 실행하여 테이블을 삭제합니다.
DROP TABLE person;
다음으로 아래 쿼리를 사용하여 테이블을 만듭니다.
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
기존 테이블에 ID 속성이 있는 새 열을 추가하려면 ALTER 명령을 사용해야 합니다. 아래 쿼리는 PersonID를 개인 테이블의 ID 열로 추가합니다.
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
명시적으로 ID 열에 값 추가
ID 열 값을 명시적으로 지정하여 위 테이블에 새 행을 추가하면 SQL Server에서 오류가 발생합니다. 아래 쿼리를 참조하세요.
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
이 쿼리를 실행하면 다음 오류가 발생합니다.

ID 열 값을 명시적으로 삽입하려면 먼저 IDENTITY_INSERT 값을 ON으로 설정해야 합니다. 그런 다음 삽입 작업을 실행하여 테이블에 새 행을 추가한 다음 IDENTITY_INSERT 값을 OFF로 설정합니다. 아래 코드 스크립트를 참조하세요.
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT 켜짐 사용자는 ID 열에 데이터를 넣을 수 있습니다. IDENTITY_INSERT 꺼짐 이 열에 값을 추가하는 것을 방지합니다.
코드 스크립트를 실행하면 값 14의 PersonID가 성공적으로 삽입되었음을 확인할 수 있는 아래 출력이 표시됩니다.

ID 기능
SQL Server는 테이블의 IDENTITY 열 작업을 위한 몇 가지 ID 기능을 제공합니다. 이러한 식별 기능은 다음과 같습니다.
- @@IDENTITY 함수
- SCOPE_IDENTITY() 함수
- IDENT_CURRENT 함수
- ID 기능
몇 가지 예를 통해 IDENTITY 함수를 살펴보겠습니다.
@@IDENTITY 함수
@@IDENTITY는 시스템 정의 함수입니다. 마지막 ID 값을 표시합니다. (최대 사용 ID 값)이 동일한 세션의 IDENTITY 열에 대한 테이블에 생성되었습니다. 이 함수 열은 테이블에 새 항목을 삽입한 후 명령문에 의해 생성된 ID 값을 반환합니다. 그것은 없는 IDENTITY 값을 생성하지 않는 쿼리를 실행할 때의 값입니다. 항상 현재 세션 범위에서 작동합니다. 원격으로 사용할 수 없습니다.
예
개인 테이블의 현재 최대 ID 값이 13이라고 가정합니다. 이제 동일한 세션에 ID 값을 1씩 증가시키는 하나의 레코드를 추가하겠습니다. 그런 다음 @@IDENTITY 함수를 사용하여 동일한 세션에서 생성된 마지막 ID 값을 가져옵니다.
전체 코드 스크립트는 다음과 같습니다.
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
스크립트를 실행하면 사용된 최대 ID 값이 14임을 확인할 수 있는 다음 출력이 반환됩니다.

SCOPE_IDENTITY() 함수
SCOPE_IDENTITY()는 다음을 수행하는 시스템 정의 함수입니다. 가장 최근의 ID 값을 표시합니다. 현재 범위의 테이블에서. 이 범위는 모듈, 트리거, 함수 또는 저장 프로시저일 수 있습니다. 이 함수는 제한된 범위만 갖는다는 점을 제외하면 @@IDENTITY() 함수와 유사합니다. SCOPE_IDENTITY 함수는 동일한 범위에서 값을 생성하는 삽입 작업 전에 실행하면 NULL을 반환합니다.
예
아래 코드는 동일한 세션에서 @@IDENTITY 및 SCOPE_IDENTITY() 함수를 모두 사용합니다. 이 예에서는 먼저 마지막 ID 값을 표시한 다음 테이블에 행 하나를 삽입합니다. 다음으로 두 가지 ID 기능을 모두 실행합니다.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
코드를 실행하면 현재 세션 및 유사한 범위에 동일한 값이 표시됩니다. 아래 출력 이미지를 참조하십시오.

이제 예제를 통해 두 기능이 어떻게 다른지 살펴보겠습니다. 먼저, 다음과 같은 두 개의 테이블을 생성합니다. 직원_데이터 그리고 부서 아래 명령문을 사용하여:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
다음으로, Employee_data 테이블에 INSERT 트리거를 생성합니다. 이 트리거는 Employee_data 테이블에 행을 삽입할 때마다 부서 테이블에 행을 삽입하기 위해 호출됩니다.
아래 쿼리는 기본값을 삽입하기 위한 트리거를 생성합니다. '그것' Employee_data 테이블의 각 삽입 쿼리에 대한 부서 테이블에서:
무작위로 SQL 순서
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
트리거를 생성한 후 Employee_data 테이블에 하나의 레코드를 삽입하고 @@IDENTITY 및 SCOPE_IDENTITY() 함수의 출력을 모두 확인하겠습니다.
INSERT INTO employee_data VALUES ('John Mathew');
쿼리를 실행하면 Employee_data 테이블에 한 행이 추가되고 동일한 세션에서 ID 값이 생성됩니다. Employee_data 테이블에서 삽입 쿼리가 실행되면 자동으로 트리거를 호출하여 부서 테이블에 행 하나를 추가합니다. ID 시드 값은 Employee_data의 경우 1이고 부서 테이블의 경우 100입니다.
마지막으로, 동일한 범위에서만 ID 값을 반환하기 때문에 SELECT @@IDENTITY 함수에 대한 출력 100과 SCOPE_IDENTITY 함수에 대한 출력 1을 표시하는 아래 문을 실행합니다.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
결과는 다음과 같습니다.

IDENT_CURRENT() 함수
IDENT_CURRENT는 시스템 정의 함수입니다. 가장 최근 IDENTITY 값을 표시합니다. 모든 연결에서 특정 테이블에 대해 생성됩니다. 이 함수는 ID 값을 생성하는 SQL 쿼리의 범위를 고려하지 않습니다. 이 함수에는 ID 값을 얻으려는 테이블 이름이 필요합니다.
예
먼저 두 개의 연결 창을 열어보면 이를 이해할 수 있습니다. 개인 테이블에 ID 값 15를 생성하는 첫 번째 창에 하나의 레코드를 삽입합니다. 다음으로 동일한 출력을 볼 수 있는 다른 연결 창에서 이 ID 값을 확인할 수 있습니다. 전체 코드는 다음과 같습니다.
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
두 개의 서로 다른 창에서 위 코드를 실행하면 동일한 ID 값이 표시됩니다.

IDENTITY() 함수
IDENTITY() 함수는 시스템 정의 함수입니다. 새 테이블에 ID 열을 삽입하는 데 사용됩니다. . 이 함수는 CREATE TABLE 및 ALTER TABLE 문과 함께 사용하는 IDENTITY 속성과 다릅니다. 이 함수는 한 테이블에서 다른 테이블로 데이터를 전송할 때 사용되는 SELECT INTO 문에서만 사용할 수 있습니다.
다음 구문은 SQL Server에서 이 함수를 사용하는 방법을 보여줍니다.
IDENTITY (data_type , seed , increment) AS column_name
소스 테이블에 IDENTITY 열이 있는 경우 SELECT INTO 명령으로 형성된 테이블은 기본적으로 이를 상속합니다. 예를 들어 , 이전에 ID 열이 있는 person 테이블을 만들었습니다. IDENTITY() 함수와 함께 SELECT INTO 문을 사용하여 개인 테이블을 상속하는 새 테이블을 생성한다고 가정합니다. 이 경우 소스 테이블에 이미 ID 열이 있으므로 오류가 발생합니다. 아래 쿼리를 참조하세요.
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
위 명령문을 실행하면 다음 오류 메시지가 반환됩니다.

아래 명령문을 사용하여 ID 속성이 없는 새 테이블을 만들어 보겠습니다.
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
그런 다음, 다음과 같이 IDENTITY 함수를 포함하는 SELECT INTO 문을 사용하여 이 테이블을 복사합니다.
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
명령문이 실행되면 다음을 사용하여 이를 확인할 수 있습니다. sp_help 테이블 속성을 표시하는 명령입니다.

IDENTITY 열을 볼 수 있습니다. 유혹적이다 지정된 조건에 따라 속성을 지정합니다.
SELECT 문과 함께 이 함수를 사용하면 SQL Server는 다음과 같은 오류 메시지를 표시합니다.
Msg 177, Level 15, State 1, Line 2 IDENTITY 함수는 SELECT 문에 INTO 절이 있는 경우에만 사용할 수 있습니다.
IDENTITY 값 재사용
SQL Server 테이블의 ID 값은 재사용할 수 없습니다. ID 열 테이블에서 행을 삭제하면 ID 열에 간격이 생성됩니다. 또한 SQL Server는 ID 열에 새 행을 삽입할 때 간격을 생성하며 문이 실패하거나 롤백됩니다. 간격은 ID 값이 손실되어 IDENTITY 열에 다시 생성될 수 없음을 나타냅니다.
실제로 이해하려면 아래 예를 고려하십시오. 우리는 이미 다음 데이터를 포함하는 개인 테이블을 가지고 있습니다:

다음으로 이름이 지정된 두 개의 테이블을 더 만듭니다. '위치' , 그리고 ' 사람_위치 ' 다음 문을 사용합니다.
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
다음으로, person 테이블에 새 레코드를 삽입하고 person_position 테이블에 새 행을 추가하여 위치를 할당하려고 합니다. 우리는 아래와 같은 거래 명세서를 사용하여 이를 수행할 것입니다:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
위의 트랜잭션 코드 스크립트는 첫 번째 insert 문을 성공적으로 실행합니다. 그러나 포지션 테이블에 ID가 10인 포지션이 없기 때문에 두 번째 명령문은 실패했습니다. 따라서 전체 트랜잭션이 롤백되었습니다.
PersonID 열의 최대 ID 값은 16이므로 첫 번째 삽입 문에서 ID 값 17을 사용한 다음 트랜잭션이 롤백되었습니다. 따라서 Person 테이블에 다음 행을 삽입하면 다음 ID 값은 18이 됩니다. 아래 명령문을 실행하십시오.
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
개인 테이블을 다시 확인한 후 새로 추가된 레코드에 ID 값 18이 포함되어 있음을 확인합니다.

단일 테이블에 있는 두 개의 IDENTITY 열
기술적으로 단일 테이블에 두 개의 ID 열을 만드는 것은 불가능합니다. 이렇게 하면 SQL Server에서 오류가 발생합니다. 다음 쿼리를 참조하세요.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
이 코드를 실행하면 다음 오류가 표시됩니다.

그러나 계산 열을 사용하면 단일 테이블에 두 개의 ID 열을 만들 수 있습니다. 다음 쿼리는 원래 ID 열을 사용하고 이를 1씩 줄이는 계산 열이 있는 테이블을 만듭니다.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
다음으로 아래 명령을 사용하여 이 테이블에 일부 데이터를 추가합니다.
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
마지막으로 SELECT 문을 사용하여 테이블 데이터를 확인합니다. 다음 출력이 반환됩니다.

이미지에서 SecondID 열이 두 번째 ID 열 역할을 하며 시작 값인 9990에서 10씩 감소하는 방식을 볼 수 있습니다.
SQL Server의 IDENTITY 열에 대한 오해
DBA 사용자는 SQL Server ID 열에 관해 많은 오해를 갖고 있습니다. 다음은 ID 열과 관련하여 볼 수 있는 가장 일반적인 오해 목록입니다.
IDENTITY 열은 고유합니다. SQL Server의 공식 문서에 따르면 ID 속성은 열 값이 고유하다는 것을 보장할 수 없습니다. 열 고유성을 적용하려면 PRIMARY KEY, UNIQUE 제약 조건 또는 UNIQUE 인덱스를 사용해야 합니다.
IDENTITY 열은 연속된 숫자를 생성합니다. 공식 문서에는 데이터베이스 오류 또는 서버 재시작 시 ID 열에 할당된 값이 손실될 수 있음이 명시되어 있습니다. 삽입하는 동안 ID 값에 공백이 발생할 수 있습니다. 테이블에서 값을 삭제하거나 insert 문이 롤백될 때 간격이 생성될 수도 있습니다. 간격을 생성하는 값은 더 이상 사용할 수 없습니다.
IDENTITY 열은 기존 값을 자동 생성할 수 없습니다. DBCC CHECKIDENT 명령을 사용하여 ID 속성을 다시 시드할 때까지는 ID 열에서 기존 값을 자동 생성할 수 없습니다. 이를 통해 ID 속성의 시드 값(행의 시작 값)을 조정할 수 있습니다. 이 명령을 수행한 후 SQL Server는 새로 생성된 값이 이미 테이블에 있는지 여부를 확인하지 않습니다.
PRIMARY KEY인 IDENTITY 열은 행을 식별하는 데 충분합니다. 기본 키에 다른 고유 제약 조건 없이 테이블의 ID 열이 포함되어 있는 경우 해당 열은 중복 값을 저장하고 열 고유성을 방지할 수 있습니다. 아시다시피 기본 키는 중복 값을 저장할 수 없지만 ID 열은 중복 값을 저장할 수 있습니다. 동일한 열에 기본 키와 ID 속성을 사용하지 않는 것이 좋습니다.
삽입 후 ID 값을 다시 가져오기 위해 잘못된 도구를 사용하는 경우: 방금 실행한 문에서 직접 삽입된 ID 값을 가져오기 위해 @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT 및 IDENTITY() 함수 간의 차이점을 인식하지 못하는 것에 대한 일반적인 오해이기도 합니다.
SEQUENCE와 IDENTITY의 차이점
자동 번호를 생성하기 위해 SEQUENCE와 IDENTITY를 모두 사용합니다. 그러나 몇 가지 차이점이 있으며 주요 차이점은 ID는 테이블에 종속적인 반면 시퀀스는 그렇지 않다는 것입니다. 차이점을 표 형식으로 요약해 보겠습니다.
| 신원 | 순서 |
|---|---|
| ID 속성은 특정 테이블에 사용되며 다른 테이블과 공유할 수 없습니다. | DBA는 테이블과 독립적이기 때문에 여러 테이블 간에 공유할 수 있는 시퀀스 개체를 정의합니다. |
| 이 속성은 테이블에서 insert 문이 실행될 때마다 값을 자동으로 생성합니다. | NEXT VALUE FOR 절을 사용하여 시퀀스 개체의 다음 값을 생성합니다. |
| SQL Server는 ID 속성의 열 값을 초기 값으로 재설정하지 않습니다. | SQL Server에서는 시퀀스 개체의 값을 재설정할 수 있습니다. |
| ID 속성의 최대값을 설정할 수 없습니다. | 시퀀스 객체의 최대값을 설정할 수 있습니다. |
| SQL Server 2000에 도입되었습니다. | SQL Server 2012에 도입되었습니다. |
| 이 속성은 내림차순으로 ID 값을 생성할 수 없습니다. | 내림차순으로 값을 생성할 수 있습니다. |
결론
이 문서에서는 SQL Server의 IDENTITY 속성에 대한 전체 개요를 제공합니다. 여기서 우리는 항등 속성이 언제 어떻게 사용되는지, 그 다양한 기능과 오해, 그리고 서열과 어떻게 다른지 배웠습니다.