통계의 Z-점수 데이터 포인트가 분포 평균으로부터 얼마나 많은 표준 편차를 가지고 있는지를 측정한 것입니다. 통계에서 z 점수를 찾아보겠습니다. z-점수 0은 데이터 포인트의 점수가 평균 점수와 동일함을 나타냅니다. 양수 z-점수는 데이터 포인트가 평균보다 높음을 나타내고, 음수 z-점수는 데이터 포인트가 평균보다 낮음을 나타냅니다.
Z-점수 계산 공식은 다음과 같습니다. z = (x – μ)/p
어디:
- 엑스: 테스트 값입니다
- 중: 평균이다
- 에: 표준값이다
이 기사에서는 다음 개념에 대해 논의할 것입니다.
내용의 테이블
- Z-점수란 무엇입니까?
- Z-점수를 계산하는 방법은 무엇입니까?
- Z-점수의 특성
- Z-점수 값을 사용하여 이상값 계산
- Python에서 Z-Score 구현
- Z-점수 적용
- Z 점수와 표준 편차
- Z-점수를 표준 점수라고 부르는 이유는 무엇입니까?
Z-점수란 무엇입니까?
표준 점수라고도 알려진 Z-점수는 평균 위 또는 아래의 표준 편차로 표현하여 평균에서 데이터 포인트의 편차를 알려줍니다. 이를 통해 데이터 포인트가 평균에서 얼마나 떨어져 있는지 알 수 있습니다. 따라서 Z-점수는 평균과의 표준편차로 측정됩니다. 예를 들어, Z-점수가 2라는 것은 해당 값이 평균에서 2 표준편차 떨어져 있음을 나타냅니다. z-점수를 사용하려면 모집단 평균(μ)과 모집단 표준편차(σ)를 알아야 합니다.
Z-점수 공식
z-점수는 다음 공식을 사용하여 계산할 수 있습니다.
z = (X – μ) / p
어디,
- z = Z-점수
- X = 요소의 값
- μ = 모집단 평균
- σ = 모집단 표준편차
Z-점수를 계산하는 방법은 무엇입니까?
모집단 평균(μ), 모집단 표준 편차(σ), 문제 설명의 관측값(x)을 Z-점수 방정식에 대입하면 Z-점수 값이 생성됩니다. 주어진 Z-Score가 양수인지 음수인지에 따라 다음을 사용할 수 있습니다. 포지티브 Z-테이블 또는 음의 Z 테이블 온라인이나 부록의 통계 교과서 뒷면에서 확인할 수 있습니다.
{kind=link}
{kind=link}
예시 1:
귀하는 GATE 시험에 응시하여 500점을 받았습니다. GATE의 평균 점수는 390점이고 표준 편차는 45입니다. 평균 응시자와 비교하여 귀하의 시험 점수는 얼마나 됩니까?
해결책:
위의 질문 설명에서 다음 데이터를 쉽게 사용할 수 있습니다.
원점수/관찰값 = X = 500
평균 점수 = μ = 390
표준편차 = σ = 45
z-점수 공식을 적용하면,
z = (X – μ) / p
z = (500 – 390) / 45
z = 110 / 45 = 2.44
이는 귀하의 z-점수가 다음과 같다는 것을 의미합니다. 2.44 .
Z-Score는 양수 2.44이므로 양수 Z-Table을 사용하겠습니다.
이제 살펴 보겠습니다. Z 테이블 (CC-BY) 다른 응시자들과 비교하여 당신의 점수가 얼마나 좋은지 알아보십시오.
아래 지침에 따라 표에서 확률을 찾아보세요.
여기, z-점수 = 2.44, 어느 나 는 데이터 포인트가 평균보다 2.44 표준편차 높다는 것을 나타냅니다.
- 먼저 Y축의 처음 두 자리 2.4를 매핑합니다.
- 그런 다음 X축을 따라 0.04를 매핑합니다.
- 두 축을 모두 결합합니다. 둘의 교차점은 찾고 있는 Z 점수 값과 관련된 누적 확률을 제공합니다.
[이 확률은 Z-점수 왼쪽의 표준 정규 곡선 아래 영역을 나타냅니다.]
자바 csv 읽기
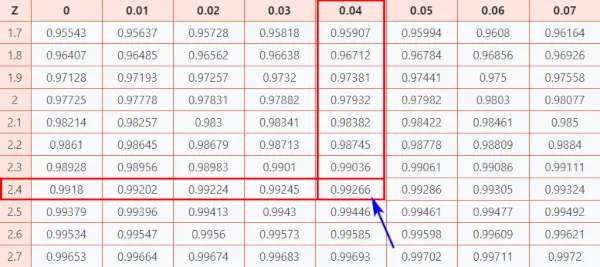
정규분포표
결과적으로 최종 값은 다음과 같습니다. 0.99266 .
이제 GATE 시험의 원래 점수인 500점을 배치의 평균 점수와 비교해야 합니다. 이를 위해서는 Z-점수와 관련된 누적 확률을 백분율 값으로 변환해야 합니다.
0.99266 × 100 = 99.266%
마지막으로, 거의 모든 것보다 좋은 성과를 냈다고 말할 수 있습니다. 99% 다른 수험생들.
실시예 2 : 학생의 점수가 350에서 400 사이일 확률은 얼마입니까(평균 점수 μ는 390, 표준 편차 σ는 45)?
해결책:
최소 점수 = X1= 350
최대 점수 = X2= 400
z-점수 공식을 적용하면,
와 함께1= (X1 – m) / p
와 함께1= (350 – 390) / 45
와 함께1= -40 / 45 = -0.88
와 함께2= (엑스2– m) / p
z2 = (400 – 390) / 45
와 함께2= 10 / 45 = 0.22
z1이 음수이므로 음수를 살펴봐야 합니다. Z-테이블 첫 번째 확률인 누적 확률 p1은 다음과 같습니다. 0.18943 .
와 함께2양수이므로 누적 확률 p를 산출하는 양수 Z-테이블을 사용합니다.2~의 0.58706 .
최종 확률은 p에서 p1을 빼서 계산됩니다.2:
p = p2– 피1
p = 0.58706 - 0.18943 = 0.39763
학생의 점수가 350에서 400 사이일 확률은 다음과 같습니다. 39.763% (0.39763 * 100).
Z-점수의 특성
- Z-점수의 크기는 표준 편차 측면에서 데이터 포인트가 평균에서 얼마나 떨어져 있는지를 반영합니다.
- z-점수가 0보다 작은 요소는 해당 요소가 평균보다 작다는 것을 나타냅니다.
- Z-점수를 사용하면 다양한 분포의 데이터 포인트를 비교할 수 있습니다.
- 0보다 큰 z-점수를 갖는 요소는 해당 요소가 평균보다 크다는 것을 나타냅니다.
- z-점수가 0인 요소는 해당 요소가 평균과 동일함을 나타냅니다.
- z-점수가 1인 요소는 해당 요소가 평균보다 1 표준편차 더 크다는 것을 나타냅니다. z-점수는 2, 평균보다 2개의 표준편차가 더 큰 등입니다.
- -1과 같은 z-점수를 갖는 요소는 해당 요소가 평균보다 1 표준편차 적음을 나타냅니다. z-점수는 -2, 평균보다 2 표준편차 작은 등입니다.
- 주어진 세트의 요소 수가 많으면 요소의 약 68%가 -1과 1 사이의 z-점수를 갖습니다. 약 95%는 -2와 2 사이의 z-점수를 가집니다. 약 99%는 -3과 3 사이의 z-점수를 가집니다. 이는 경험적 법칙으로 알려져 있으며, 아래 이미지에서 볼 수 있듯이 정규 분포에서 평균과 특정 표준 편차 내에 있는 데이터의 비율을 나타냅니다.
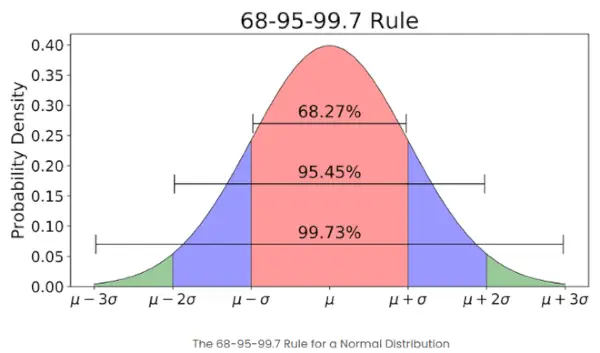
정규 분포의 경험적 규칙
Z-점수 값을 사용하여 이상값 계산
데이터 포인트의 z-점수 값을 사용하여 데이터의 이상값을 계산할 수 있습니다. 이상치 데이터 포인트를 고려하는 단계는 다음과 같습니다.
- 먼저 이상값을 확인하려는 데이터 세트를 수집합니다.
- 데이터세트의 평균과 표준편차를 계산합니다. 이 값은 각 데이터 포인트의 z-점수 값을 계산하는 데 사용됩니다.
- 각 데이터 포인트의 z-점수 값을 계산합니다. z-점수 값을 계산하는 공식은 다음과 같습니다.
Z = frac{{X – mu}}{{sigma}}
여기서 X는 데이터 포인트, μ는 데이터의 평균, σ는 데이터 세트의 표준 편차입니다. - 데이터 포인트가 이상치로 간주될 수 있는 z-점수에 대한 구분 값을 결정합니다. 이 컷오프 값은 프로젝트에 따라 결정되는 하이퍼파라미터입니다.
- z-점수 값이 3보다 큰 데이터 포인트는 해당 데이터 포인트가 데이터 세트의 99.73% 포인트에 속하지 않음을 의미합니다.
- z-점수가 결정된 컷오프 값보다 큰 모든 데이터 포인트는 이상값으로 간주됩니다.
확인하다: 이상치 감지를 위한 Z 점수
Python에서 Z-Score 구현
Python을 사용하여 데이터세트에 있는 데이터 포인트의 z-점수 값을 계산할 수 있습니다. 또한 numpy 라이브러리를 사용하여 데이터 세트의 평균 및 표준 편차를 계산합니다.
파이썬3 import numpy as np def calculate_z_score(data): # Mean of the dataset mean = np.mean(data) # Standard Deviation of tha dataset std_dev = np.std(data) # Z-score of tha data points z_scores = (data - mean) / std_dev return z_scores # Example dataset dataset = [3,9, 23, 43,53, 4, 5,30, 35, 50, 70, 150, 6, 7, 8, 9, 10] z_scores = calculate_z_score(dataset) print('Z-Score :',z_scores) # Data points which lies outside 3 standard deviatioms are outliers # i.e outside range of99.73% values outliers = [data_point for data_point, z_score in zip(dataset, z_scores) if z_score>3] print(f'
데이터세트의 이상값은 {outliers}')> 산출:
Z 점수 : [-0.7574907 -0.59097335 -0.20243286 0.35262498 0.6301539 -0.72973781
-0.70198492 -0.00816262 0.13060185 0.54689523 1.10195307 3.32218443
-0.67423202 -0.64647913 -0.61872624 -0.59097335 -0.56322046]
데이터세트의 이상값은 [150]입니다.
Z-점수 적용
- Z-점수는 다양한 기능을 공통 규모로 가져오기 위해 기능 확장에 자주 사용됩니다. 기능을 정규화하면 평균 및 단위 분산이 0이 되며, 이는 특정 기계 학습 알고리즘, 특히 거리 측정에 의존하는 알고리즘에 유용할 수 있습니다.
- Z-점수는 데이터세트의 이상값을 식별하는 데 사용할 수 있습니다. 특정 임계값(일반적으로 평균에서 3 표준 편차)을 초과하는 Z-점수를 갖는 데이터 포인트는 이상값으로 간주될 수 있습니다.
- Z-점수는 이상 탐지 알고리즘에 사용되어 예상되는 동작에서 크게 벗어나는 인스턴스를 식별할 수 있습니다.
- Z-점수를 적용하면 치우친 분포를 보다 정규 분포로 변환할 수 있습니다.
- 회귀 모델로 작업할 때 잔차의 Z-점수를 분석하여 동질성(잔차의 일정한 분산)을 확인할 수 있습니다.
- Z 점수는 평균과의 표준 편차를 확인하여 기능 확장에 사용할 수 있습니다.
Z 점수와 표준 편차
Z-점수 | 표준 편차 |
|---|---|
원시 데이터를 표준화된 규모로 변환합니다. | 값 집합의 변동 또는 분산 정도를 측정합니다. |
원래 측정 단위를 없애기 때문에 다양한 데이터세트의 값을 더 쉽게 비교할 수 있습니다. | 표준 편차는 원래 측정 단위를 유지하므로 단위가 다른 데이터 세트 간의 직접 비교에는 적합하지 않습니다. |
표준 편차 측면에서 데이터 포인트가 평균에서 얼마나 떨어져 있는지 표시하여 분포 내에서 데이터 포인트의 상대적 위치에 대한 척도를 제공합니다. | 원래 데이터와 동일한 단위로 표현되어 값이 평균을 중심으로 얼마나 분산되어 있는지에 대한 절대적인 측정값을 제공합니다. |
확인하다: Z-점수 테이블
Z-점수를 표준 점수라고 부르는 이유는 무엇입니까?
Z-점수는 무작위 변수의 값을 표준화하기 때문에 표준 점수라고도 합니다. 이는 표준화된 점수 목록의 평균이 0이고 표준편차가 1.0임을 의미합니다. Z-점수를 사용하면 다양한 종류의 변수에 대한 점수를 비교할 수도 있습니다. 이는 서로 다른 변수나 분포의 점수를 동일시하기 위해 상대 순위를 사용하기 때문입니다.
Z-점수는 변수를 표준 정규 분포(μ = 0 및 σ = 1)와 비교하는 데 자주 사용됩니다.
통계의 Z-점수 – FAQ
양수 및 음수 Z-점수의 중요성은 무엇입니까?
양수 Z-점수는 평균보다 높은 값을 나타내고, 음수 Z-점수는 평균보다 낮은 값을 나타냅니다. 부호는 평균에서 벗어나는 방향을 반영합니다.
Z-Score가 0이라는 것은 무엇을 의미합니까?
Z-점수 0은 데이터 포인트의 값이 정확히 데이터 세트의 평균에 있음을 나타냅니다. 이는 데이터 포인트가 평균보다 높지도 낮지도 않다는 것을 나타냅니다.
Z-점수와 관련된 68-95-99.7 규칙은 무엇입니까?
경험적 법칙이라고도 알려진 68-95-99.7 규칙은 다음과 같이 명시합니다.
라텍스의 부분 차별화
- 데이터의 약 68%가 평균에서 1 표준편차 내에 속합니다.
- 약 95%가 2 표준편차 내에 속합니다.
- 약 99.7%가 3 표준편차 내에 속합니다.
비정규 분포에 Z-Score를 사용할 수 있나요?
Z-점수는 데이터가 정규 분포를 따른다는 가정을 기반으로 합니다. 그러나 실제로 Z-Score는 정규 분포를 따르는 데이터에 유용합니다. Z-점수는 모든 분포에 대해 계산될 수 있지만 비정규 분포 데이터를 처리할 때 해석의 신뢰성과 단순성이 떨어집니다.
Z-Score를 실제 상황에 어떻게 적용할 수 있나요?
Z-Score는 포트폴리오 분석을 위한 재무, 표준화된 테스트를 위한 교육, 임상 평가를 위한 건강 등과 같은 다양한 응용 프로그램을 갖추고 있습니다. 이는 데이터를 비교하고 해석하기 위한 표준화된 척도를 제공합니다.