이번 글에서는 데이터 구조의 BFS 알고리즘에 대해 설명하겠습니다. 너비 우선 탐색은 루트 노드부터 그래프 순회를 시작하고 모든 인접 노드를 탐색하는 그래프 순회 알고리즘입니다. 그런 다음 가장 가까운 노드를 선택하고 탐색되지 않은 모든 노드를 탐색합니다. 순회를 위해 BFS를 사용하는 동안 그래프의 모든 노드는 루트 노드로 간주될 수 있습니다.
그래프를 탐색하는 방법에는 여러 가지가 있지만 그 중 BFS가 가장 일반적으로 사용되는 방법입니다. 트리 또는 그래프 데이터 구조의 모든 정점을 검색하는 재귀 알고리즘입니다. BFS는 그래프의 모든 정점을 방문 및 방문하지 않음이라는 두 가지 범주로 분류합니다. 그래프에서 단일 노드를 선택한 후 선택한 노드에 인접한 모든 노드를 방문합니다.
BFS 알고리즘의 응용
너비 우선 알고리즘의 적용은 다음과 같습니다.
- BFS는 주어진 소스 위치에서 주변 위치를 찾는 데 사용될 수 있습니다.
- P2P 네트워크에서는 BFS 알고리즘을 탐색 방법으로 사용하여 모든 인접 노드를 찾을 수 있습니다. BitTorrent, uTorrent 등과 같은 대부분의 토렌트 클라이언트는 이 프로세스를 사용하여 네트워크에서 '시드'와 '피어'를 찾습니다.
- BFS는 웹 크롤러에서 웹 페이지 색인을 생성하는 데 사용될 수 있습니다. 웹페이지 색인을 생성하는 데 사용할 수 있는 주요 알고리즘 중 하나입니다. 소스 페이지에서 탐색을 시작하고 페이지와 연결된 링크를 따라갑니다. 여기서 모든 웹 페이지는 그래프의 노드로 간주됩니다.
- BFS는 최단 경로와 최소 스패닝 트리를 결정하는 데 사용됩니다.
- BFS는 가비지 수집을 복제하는 Cheney의 기술에도 사용됩니다.
- 이것은 흐름 네트워크의 최대 흐름을 계산하기 위해 Ford-Fulkerson 방법에서 사용될 수 있습니다.
연산
그래프를 탐색하기 위한 BFS 알고리즘과 관련된 단계는 다음과 같습니다.
1 단계: SET STATUS = G의 각 노드에 대해 1(준비 상태)
2 단계: 시작 노드 A를 큐에 넣고 STATUS = 2(대기 상태)로 설정합니다.
3단계: QUEUE가 빌 때까지 4단계와 5단계를 반복합니다.
4단계: 노드 N을 대기열에서 빼냅니다. 이를 처리하고 STATUS = 3(처리된 상태)으로 설정합니다.
5단계: 준비 상태(STATUS = 1)에 있는 N의 모든 이웃을 대기열에 넣고 설정합니다.
파이썬의 eol
상태 = 2
(대기 상태)
스위치 메소드 자바
[루프 종료]
6단계: 출구
BFS 알고리즘의 예
이제 예제를 통해 BFS 알고리즘의 작동을 이해해 보겠습니다. 아래 예제에는 7개의 꼭짓점을 갖는 방향성 그래프가 있습니다.
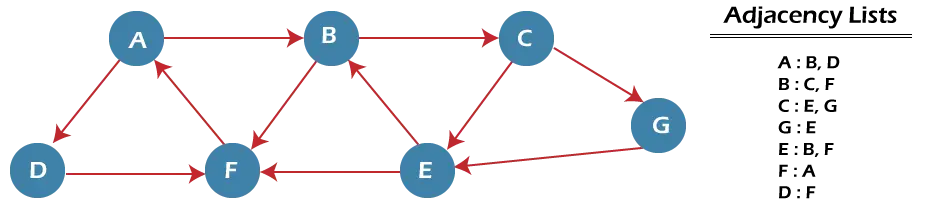
위 그래프에서 Node A에서 시작하여 Node E에서 끝나는 BFS를 사용하여 최소 경로 'P'를 찾을 수 있습니다. 알고리즘은 QUEUE1과 QUEUE2라는 두 개의 대기열을 사용합니다. QUEUE1은 처리될 모든 노드를 보유하고, QUEUE2는 QUEUE1에서 처리되고 삭제된 모든 노드를 보유합니다.
이제 노드 A부터 그래프를 살펴보겠습니다.
1 단계 - 먼저 queue1에 A를 추가하고 queue2에 NULL을 추가합니다.
QUEUE1 = {A} QUEUE2 = {NULL} 2 단계 - 이제 queue1에서 노드 A를 삭제하고 queue2에 추가합니다. 노드 A의 모든 이웃을 queue1에 삽입합니다.
QUEUE1 = {B, D} QUEUE2 = {A} 3단계 - 이제 queue1에서 노드 B를 삭제하고 queue2에 추가합니다. 노드 B의 모든 이웃을 queue1에 삽입합니다.
QUEUE1 = {D, C, F} QUEUE2 = {A, B} 4단계 - 이제 queue1에서 노드 D를 삭제하고 queue2에 추가합니다. 노드 D의 모든 이웃을 queue1에 삽입합니다. Node D의 유일한 이웃은 F이므로 이미 삽입되어 있으므로 다시 삽입되지 않습니다.
문자열.형식 자바
QUEUE1 = {C, F} QUEUE2 = {A, B, D} 5단계 - queue1에서 노드 C를 삭제하고 queue2에 추가합니다. 노드 C의 모든 이웃을 queue1에 삽입합니다.
QUEUE1 = {F, E, G} QUEUE2 = {A, B, D, C} 5단계 - queue1에서 노드 F를 삭제하고 queue2에 추가합니다. 노드 F의 모든 이웃을 queue1에 삽입합니다. 노드 F의 모든 이웃이 이미 존재하므로 다시 삽입하지 않습니다.
QUEUE1 = {E, G} QUEUE2 = {A, B, D, C, F} 6단계 - queue1에서 노드 E를 삭제합니다. 모든 이웃이 이미 추가되었으므로 다시 삽입하지 않겠습니다. 이제 모든 노드를 방문하고 대상 노드 E를 queue2에서 만나게 됩니다.
QUEUE1 = {G} QUEUE2 = {A, B, D, C, F, E} BFS 알고리즘의 복잡성
BFS의 시간 복잡도는 그래프를 표현하는 데 사용되는 데이터 구조에 따라 달라집니다. BFS 알고리즘의 시간 복잡도는 다음과 같습니다. O(V+E) , 최악의 경우 BFS 알고리즘은 모든 노드와 에지를 탐색하기 때문입니다. 그래프에서 꼭짓점의 개수는 O(V)이고, 간선의 개수는 O(E)입니다.
BFS의 공간복잡도는 다음과 같이 표현될 수 있다. 오(V) , 여기서 V는 정점의 수입니다.
BFS 알고리즘 구현
이제 Java에서 BFS 알고리즘의 구현을 살펴보겠습니다.
이 코드에서는 인접 목록을 사용하여 그래프를 나타냅니다. Java에서 너비 우선 검색 알고리즘을 구현하면 노드가 대기열의 헤드(또는 시작)에서 대기열에서 제거된 후 각 노드에 연결된 노드 목록을 통해서만 이동하면 되므로 인접 목록을 처리하는 것이 훨씬 쉬워집니다.
이 예에서 코드를 시연하기 위해 사용하는 그래프는 다음과 같습니다.

import java.io.*; import java.util.*; public class BFSTraversal { private int vertex; /* total number number of vertices in the graph */ private LinkedList adj[]; /* adjacency list */ private Queue que; /* maintaining a queue */ BFSTraversal(int v) { vertex = v; adj = new LinkedList[vertex]; for (int i=0; i<v; i++) { adj[i]="new" linkedlist(); } que="new" void insertedge(int v,int w) adj[v].add(w); * adding an edge to the adjacency list (edges are bidirectional in this example) bfs(int n) boolean nodes[]="new" boolean[vertex]; initialize array for holding data int a="0;" nodes[n]="true;" que.add(n); root node is added top of queue while (que.size() !="0)" n="que.poll();" remove element system.out.print(n+' '); print (int i="0;" < adj[n].size(); iterate through linked and push all neighbors into if (!nodes[a]) only insert nodes they have not been explored already nodes[a]="true;" que.add(a); public static main(string args[]) bfstraversal graph="new" bfstraversal(10); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, graph.insertedge(6, graph.insertedge(7, 8); system.out.println('breadth first traversal is:'); graph.bfs(2); pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/64/bfs-algorithm-3.webp" alt="Breadth First Search Algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the Breadth-first search technique along with its example, complexity, and implementation in java programming language. Here, we have also seen the real-life applications of BFS that show it the important data structure algorithm.</p> <p>So, that's all about the article. Hope, it will be helpful and informative to you.</p> <hr></v;>