다음 아키텍처는 Hive에 쿼리를 제출하는 흐름을 설명합니다.
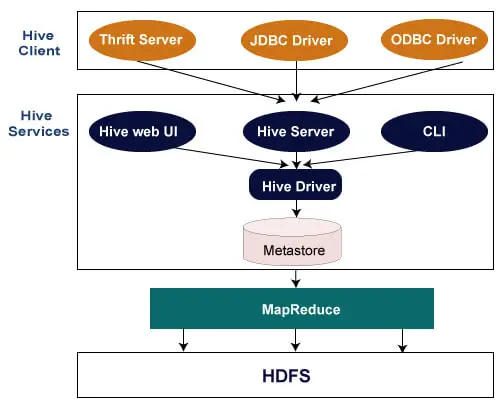
하이브 클라이언트
Hive를 사용하면 Java, Python, C++를 포함한 다양한 언어로 애플리케이션을 작성할 수 있습니다. 다음과 같은 다양한 유형의 클라이언트를 지원합니다.
- Thrift Server - Thrift를 지원하는 모든 프로그래밍 언어의 요청을 처리하는 언어 간 서비스 제공자 플랫폼입니다.
- JDBC 드라이버 - 하이브와 Java 애플리케이션 간의 연결을 설정하는 데 사용됩니다. JDBC 드라이버는 org.apache.hadoop.hive.jdbc.HiveDriver 클래스에 있습니다.
- ODBC 드라이버 - ODBC 프로토콜을 지원하는 애플리케이션이 Hive에 연결할 수 있도록 합니다.
하이브 서비스
Hive에서 제공하는 서비스는 다음과 같습니다.
- Hive CLI - Hive CLI(명령줄 인터페이스)는 Hive 쿼리와 명령을 실행할 수 있는 셸입니다.
- Hive 웹 사용자 인터페이스 - Hive 웹 UI는 Hive CLI의 대안일 뿐입니다. Hive 쿼리 및 명령을 실행하기 위한 웹 기반 GUI를 제공합니다.
- Hive MetaStore - 웨어하우스 내 다양한 테이블과 파티션의 모든 구조 정보를 저장하는 중앙 저장소입니다. 또한 열의 메타데이터와 해당 유형 정보, 데이터를 읽고 쓰는 데 사용되는 직렬 변환기 및 역직렬 변환기, 데이터가 저장되는 해당 HDFS 파일도 포함됩니다.
- Hive 서버 - Apache Thrift 서버라고 합니다. 다양한 클라이언트의 요청을 수락하고 이를 Hive Driver에 제공합니다.
- Hive 드라이버 - 웹 UI, CLI, Thrift 및 JDBC/ODBC 드라이버와 같은 다양한 소스로부터 쿼리를 수신합니다. 쿼리를 컴파일러로 전송합니다.
- Hive 컴파일러 - 컴파일러의 목적은 쿼리를 구문 분석하고 다양한 쿼리 블록 및 표현식에 대한 의미 분석을 수행하는 것입니다. HiveQL 문을 MapReduce 작업으로 변환합니다.
- Hive 실행 엔진 - Optimizer는 맵 축소 작업 및 HDFS 작업의 DAG 형식으로 논리적 계획을 생성합니다. 결국 실행 엔진은 종속성 순서대로 들어오는 작업을 실행합니다.