선형 검색과 이진 검색의 차이점을 이해하기 전에 먼저 선형 검색과 이진 검색을 별도로 알아야 합니다.
선형 검색이란 무엇입니까?
선형 검색은 한 번에 각 요소를 간단히 검색하는 순차 검색이라고도 합니다. 배열이나 목록의 요소를 검색한다고 가정해 보겠습니다. 우리는 단순히 길이를 계산하고 어떤 항목에도 뛰어들지 않습니다.
간단한 예를 생각해 봅시다.
아래 그림과 같이 10개의 요소로 구성된 배열이 있다고 가정합니다.
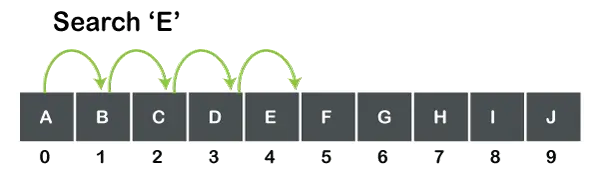
위 그림은 10개의 값을 갖는 문자형 배열을 보여줍니다. 'E'를 검색하려면 0부터 검색을 시작합니다.일요소를 찾아 요소, 즉 'E'를 찾을 수 없을 때까지 각 요소를 검색합니다. 0에서 직접 점프할 수는 없습니다.일4의 요소일즉, 각 요소는 해당 요소를 찾을 수 없을 때까지 하나씩 검색됩니다.
선형 검색의 복잡성
선형 검색은 요소를 찾을 수 없을 때까지 각 요소를 하나씩 검색합니다. 요소 수가 증가하면 스캔할 요소 수도 늘어납니다. 우리는 다음과 같이 말할 수 있습니다. 요소를 검색하는 데 걸리는 시간은 요소 수에 비례합니다. . 따라서 최악의 복잡도는 O(n)입니다.
이진 검색이란 무엇입니까?
이진 검색은 중간 요소를 계산하여 검색하려는 요소보다 작은지 큰지 확인하는 검색입니다. 이진 검색을 사용할 때의 가장 큰 장점은 목록의 각 요소를 검색하지 않는다는 것입니다. 각 요소를 검색하는 대신 목록의 절반까지 검색을 수행합니다. 따라서 이진 검색은 선형 검색에 비해 요소를 검색하는 데 시간이 덜 걸립니다.
하나 이진 검색의 전제 조건 배열은 정렬된 순서로 이루어져야 하는 반면 선형 검색은 정렬된 배열과 정렬되지 않은 배열 모두에서 작동합니다. 이진 검색 알고리즘은 분할 정복 기술을 기반으로 합니다. 즉, 배열을 재귀적으로 분할한다는 의미입니다.
이진 검색에는 세 가지 경우가 사용됩니다.
사례 1: 데이터
사례 2: data>a[mid] then right=mid-1
사례 3: data = a[mid] // 요소가 발견되었습니다.
위의 경우 ' ㅏ '는 배열의 이름입니다. 중반 재귀적으로 계산된 요소의 인덱스입니다. 데이터 검색할 요소입니다. 왼쪽 배열의 왼쪽 요소를 나타내고 오른쪽 배열의 오른쪽에 나타나는 요소를 나타냅니다.
예제를 통해 이진 검색의 작동 방식을 이해해 보겠습니다.
아래 그림과 같이 0부터 9까지 인덱스가 지정된 10 크기의 배열이 있다고 가정합니다.
위 배열에서 70개의 요소를 검색하려고 합니다.
1 단계: 먼저 배열의 중간 요소를 계산합니다. 우리는 두 가지 변수, 즉 왼쪽과 오른쪽을 고려합니다. 처음에는 아래 그림과 같이 left =0, right=9 입니다.

중간 요소 값은 다음과 같이 계산할 수 있습니다.

따라서 mid = 4, a[mid] = 50입니다. 검색할 요소는 70이므로 a[mid]는 data와 동일하지 않습니다. Case 2가 만족된다. 즉, data>a[mid]이다.

2 단계: data>a[mid]이므로 left의 값은 mid+1만큼 증가합니다. 즉, left=mid+1입니다. mid의 값은 4이므로 left의 값은 5가 됩니다. 이제 아래 그림과 같은 하위 배열이 생겼습니다.

이제 다시 위의 공식을 이용하여 mid-value를 계산하면 mid의 값은 7이 됩니다. 이제 mid는 다음과 같이 나타낼 수 있습니다.

위 그림에서 a[mid]>data를 확인할 수 있으므로 다음 단계에서는 mid 값을 다시 계산하게 됩니다.
3단계: a[mid]>데이터이므로 right의 값은 mid-1만큼 감소합니다. mid의 값은 7이므로 right의 값은 6이 됩니다. 배열은 다음과 같이 표현할 수 있습니다.

mid의 값이 다시 계산됩니다. 왼쪽과 오른쪽의 값은 각각 5와 6입니다. 따라서 mid의 값은 5입니다. 이제 mid는 아래와 같이 배열로 표현될 수 있습니다.

위 그림에서 우리는 a[mid]를 볼 수 있습니다.
4단계: as[중간] 이제 mid 값은 이미 논의한 공식을 사용하여 다시 계산됩니다. 왼쪽과 오른쪽의 값은 각각 6과 6이므로 아래 그림과 같이 mid의 값은 6이 됩니다. 위 그림에서 a[mid]=data임을 확인할 수 있습니다. 따라서 검색이 완료되고 요소가 성공적으로 발견되었습니다. 선형 검색과 이진 검색의 차이점은 다음과 같습니다. 설명 선형 검색은 목록에서 해당 요소를 찾을 때까지 해당 요소를 순차적으로 검색하여 목록에서 해당 요소를 찾는 검색입니다. 반면, 이진 검색은 중간 요소가 검색된 요소와 일치할 때까지 목록의 가운데 요소를 반복적으로 찾는 검색입니다. 두 가지 검색 작업 선형 검색은 첫 번째 요소부터 검색을 시작하고 다음 요소로 이동하지 않고 한 번에 하나의 요소를 검색합니다. 반면 이진 검색은 배열의 중간 요소를 계산하여 배열을 절반으로 나눕니다. 구현 선형 검색은 벡터, 단일 연결 리스트, 이중 연결 리스트 등 모든 선형 데이터 구조에서 구현될 수 있습니다. 대조적으로, 이진 검색은 양방향 순회, 즉 순방향 및 역방향 순회를 사용하여 해당 데이터 구조에서 구현될 수 있습니다. 복잡성 선형 검색은 사용하기 쉽습니다. 선형 검색의 경우 요소를 어떤 순서로든 정렬할 수 있으므로 덜 복잡하다고 말할 수 있지만, 이진 검색에서는 요소를 특정 순서로 정렬해야 합니다. 정렬된 요소 선형 검색의 요소는 임의의 순서로 정렬될 수 있습니다. 선형 검색에서는 요소가 정렬된 순서로 정렬되어야 하는 것이 필수는 아닙니다. 반면에 이진 검색에서는 요소를 정렬된 순서로 정렬해야 합니다. 오름차순이나 내림차순으로 배열할 수 있으며 이에 따라 알고리즘이 변경됩니다. 이진 검색은 정렬된 배열을 사용하므로 적절한 위치에 요소를 삽입해야 합니다. 반면 선형 검색에는 정렬된 배열이 필요하지 않으므로 배열 끝에 새 요소를 쉽게 삽입할 수 있습니다. 접근하다 선형 검색은 요소를 찾기 위해 반복적인 접근 방식을 사용하므로 순차 접근 방식이라고도 합니다. 이와 대조적으로 이진 검색은 배열의 중간 요소를 계산하므로 분할 및 정복 접근 방식을 사용합니다. 데이터 세트 선형 검색은 대규모 데이터 세트에는 적합하지 않습니다. 배열의 마지막 요소인 요소를 검색하려는 경우 선형 검색은 첫 번째 요소부터 시작하여 마지막 요소까지 검색하므로 요소를 검색하는 데 걸리는 시간이 길어집니다. 반면에 이진 검색은 시간이 덜 걸리기 때문에 대규모 데이터 세트에 적합합니다. 속도 선형 검색에서 데이터 세트가 크면 계산 비용이 높아지고 속도가 느려집니다. 이진 검색에서 데이터 세트가 크면 선형 검색에 비해 계산 비용이 적고 속도가 빨라집니다. 치수 선형 검색은 단일 및 다차원 배열 모두에서 사용할 수 있지만 이진 검색은 1차원 배열에서만 구현할 수 있습니다. 능률 대규모 데이터 세트를 고려할 때 선형 검색은 효율성이 떨어집니다. 대용량 데이터 세트의 경우 이진 검색이 선형 검색보다 더 효율적입니다. 차이점을 표 형식으로 살펴보겠습니다. 
선형 검색과 이진 검색의 차이점

C의 문자열
비교의 기초 선형 검색 바이너리 검색 정의 선형 검색은 첫 번째 요소부터 검색을 시작하고 해당 요소를 찾을 수 없을 때까지 각 요소를 검색된 요소와 비교합니다. 배열의 중간 요소를 찾아 검색된 요소의 위치를 찾습니다. 정렬된 데이터 선형 검색에서는 요소를 정렬된 순서로 정렬할 필요가 없습니다. 이진 검색의 전제 조건은 요소가 정렬된 순서로 정렬되어야 한다는 것입니다. 구현 선형 검색은 배열, 연결 목록 등과 같은 모든 선형 데이터 구조에서 구현될 수 있습니다. 이진 검색의 구현은 양방향 탐색이 가능한 데이터 구조에서만 구현될 수 있으므로 제한됩니다. 접근하다 이는 순차적 접근 방식을 기반으로 합니다. 이는 분할 및 정복 접근 방식을 기반으로 합니다. 크기 작은 크기의 데이터 세트에 적합합니다. 대규모 데이터 세트에 적합합니다. 능률 대규모 데이터 세트의 경우 효율성이 떨어집니다. 대용량 데이터 세트의 경우 더 효율적입니다. 최악의 시나리오 선형 검색에서 요소를 찾는 최악의 시나리오는 O(n)입니다. 이진 검색에서 요소를 찾는 최악의 시나리오는 O(log2N). 최선의 시나리오 선형 검색에서 목록의 첫 번째 요소를 찾는 가장 좋은 시나리오는 O(1)입니다. 이진 검색에서 목록의 첫 번째 요소를 찾는 가장 좋은 시나리오는 O(1)입니다. 차원 배열 단일 및 다차원 배열 모두에서 구현될 수 있습니다. 다차원 배열에서만 구현할 수 있습니다.