R 프로그래밍의 로지스틱 회귀는 이벤트 성공 확률과 이벤트 실패 확률을 찾는 데 사용되는 분류 알고리즘입니다. 로지스틱 회귀분석은 종속변수가 본질적으로 이진(0/1, True/False, Yes/No)인 경우에 사용됩니다. 로짓 함수는 이항 분포에서 연결 함수로 사용됩니다.
이진 결과 변수의 확률은 로지스틱 회귀라고 알려진 통계 모델링 기술을 사용하여 예측할 수 있습니다. 마케팅, 금융, 사회 과학, 의학 연구 등 다양한 산업 분야에서 널리 사용되고 있습니다.
일반적으로 시그모이드 함수라고 하는 로지스틱 함수는 로지스틱 회귀를 뒷받침하는 기본 아이디어입니다. 이 시그모이드 함수는 로지스틱 회귀 분석에서 예측 변수와 이항 결과의 가능성 사이의 상관 관계를 설명하는 데 사용됩니다.

R 프로그래밍의 로지스틱 회귀
로지스틱 회귀라고도 함 이항 물류 회귀 . 이는 출력이 확률이고 입력이 -무한대에서 +무한대까지일 수 있는 시그모이드 함수를 기반으로 합니다.
이론
로지스틱 회귀는 일반화 선형 모델이라고도 합니다. 정성적 반응을 예측하기 위한 분류 기법으로 사용되므로 y 값의 범위는 0~1이며 다음 수식으로 나타낼 수 있습니다.
R 프로그래밍의 로지스틱 회귀
피 관심 특성의 확률입니다. 승산비는 실패 확률 대비 성공 확률로 정의됩니다. 이는 로지스틱 회귀 계수의 주요 표현이며 0과 무한대 사이의 값을 가질 수 있습니다. 승산비는 성공 확률과 실패 확률이 같을 때 1입니다. 승산비가 2인 경우는 성공 확률이 실패 확률의 2배인 경우입니다. 승산비는 0.5로 실패 확률이 성공 확률의 2배인 경우입니다.
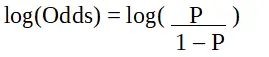
R 프로그래밍의 로지스틱 회귀
이항분포(종속변수)를 사용하고 있으므로 이 분포에 가장 적합한 연결함수를 선택해야 합니다.
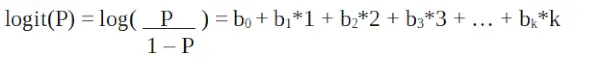
R 프로그래밍의 로지스틱 회귀
이것은 로짓 함수 . 위 방정식에서는 (일반 회귀와 마찬가지로) 오차 제곱의 합을 최소화하는 대신 표본 값을 관찰할 가능성을 최대화하기 위해 괄호를 선택했습니다. 로짓은 확률 로그라고도 합니다. 로짓 함수는 독립 변수와 선형적으로 관련되어 있어야 합니다. 이는 방정식 A에서 나온 것입니다. 여기서 왼쪽은 x의 선형 조합입니다. 이는 y가 x와 선형 관계에 있다는 OLS 가정과 유사합니다. 변수 b0, b1, b2 … 등은 알 수 없으며 사용 가능한 훈련 데이터를 사용하여 추정해야 합니다. 로지스틱 회귀 모델에서 b1에 1단위를 곱하면 로짓이 b0으로 변경됩니다. 1단위 변화로 인한 P 변화는 곱해진 값에 따라 달라집니다. b1이 양수이면 P는 증가하고, b1이 음수이면 P는 감소합니다.
데이터세트
엠티카 (모터트렌드카 로드테스트)는 자동차 32대를 대상으로 연비, 성능, 자동차 디자인의 10가지 측면으로 구성됩니다. 사전 설치되어 제공됩니다. dplyr R로 패키지를 만듭니다.
아르 자형
# Installing the package> install.packages>(>'dplyr'>)> # Loading package> library>(dplyr)> # Summary of dataset in package> summary>(mtcars)> |
문자열 java의 하위 문자열
>
>
데이터세트에 대한 로지스틱 회귀 수행
로지스틱 회귀는 R에서 다음을 사용하여 구현됩니다. 글름() 데이터 세트의 기능이나 변수를 사용하여 모델을 훈련합니다.
아르 자형
# Installing the package> # For Logistic regression> install.packages>(>'caTools'>)> # For ROC curve to evaluate model> install.packages>(>'ROCR'>)> > # Loading package> library>(caTools)> library>(ROCR)> |
>
>
데이터 분할
아르 자형
# Splitting dataset> split <->sample.split>(mtcars, SplitRatio = 0.8)> split> train_reg <->subset>(mtcars, split ==>'TRUE'>)> test_reg <->subset>(mtcars, split ==>'FALSE'>)> # Training model> logistic_model <->glm>(vs ~ wt + disp,> >data = train_reg,> >family =>'binomial'>)> logistic_model> # Summary> summary>(logistic_model)> |
>
>
산출:
Call: glm(formula = vs ~ wt + disp, family = 'binomial', data = train_reg) Deviance Residuals: Min 1Q Median 3Q Max -1.6552 -0.4051 0.4446 0.6180 1.9191 Coefficients: Estimate Std. Error z value Pr(>|z|) (절편) 1.58781 2.60087 0.610 0.5415 wt 1.36958 1.60524 0.853 0.3936 disp -0.02969 0.01577 -1.882 0.0598 . --- 시그니프. 코드: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (이항 모임에 대한 분산 매개변수는 1로 간주됨) 영 이탈도: 24 자유도에서 34.617 잔여 이탈도: 20.212 22 자유도 AIC: 26.212 Fisher Scoring 반복 횟수: 6>
- 호출: 로지스틱 회귀모형을 적합시키기 위해 사용된 함수 호출이 패밀리, 수식, 데이터에 대한 정보와 함께 표시됩니다. 이탈도 잔차: 모형의 적합도를 측정하는 이탈도 잔차입니다. 이는 실제 응답과 로지스틱 회귀 모델에 의해 예측된 확률 간의 불일치를 나타냅니다. 계수: 로지스틱 회귀 분석에서 이러한 계수는 반응 변수의 로그 확률 또는 로짓을 나타냅니다. 추정된 계수와 관련된 표준 오차는 Std. 오류 열입니다. 유의성 코드: 각 예측 변수의 유의성 수준은 유의성 코드로 표시됩니다. 분산 매개변수: 로지스틱 회귀 분석에서 분산 매개변수는 이항 분포에 대한 척도 매개변수 역할을 합니다. 이 경우 1로 설정되어 가정된 분산이 1임을 나타냅니다. 영 이탈도(Null deviance): 귀무 이탈도는 절편만 고려할 때 모델의 편차를 계산합니다. 이는 예측 변수가 없는 모델에서 발생하는 편차를 상징합니다. 잔차 이탈도: 잔차 이탈도는 예측 변수가 적용된 후 모델의 편차를 계산합니다. 예측 변수를 고려한 후의 잔차 편차를 나타냅니다. AIC: 예측 변수의 수를 설명하는 AIC(Akaike Information Criterion)는 모델의 적합도를 측정하는 척도입니다. 과적합을 방지하기 위해 더 복잡한 모델에 불이익을 줍니다. 더 잘 맞는 모델은 더 낮은 AIC 값으로 표시됩니다. Fisher 채점 반복 횟수: 모델 매개변수를 추정하기 위해 Fisher 채점 절차에 필요한 반복 횟수는 반복 횟수로 표시됩니다.
모델을 기반으로 테스트 데이터 예측
아르 자형
로봇 부품
predict_reg <->predict>(logistic_model,> >test_reg, type =>'response'>)> predict_reg> |
>
>
산출:
Hornet Sportabout Merc 280C Merc 450SE Chrysler Imperial 0.01226166 0.78972164 0.26380531 0.01544309 AMC Javelin Camaro Z28 Ford Pantera L 0.06104267 0.02807992 0.01107943>
아르 자형
# Changing probabilities> predict_reg <->ifelse>(predict_reg>0.5, 1, 0)> # Evaluating model accuracy> # using confusion matrix> table>(test_reg$vs, predict_reg)> missing_classerr <->mean>(predict_reg != test_reg$vs)> print>(>paste>(>'Accuracy ='>, 1 - missing_classerr))> # ROC-AUC Curve> ROCPred <->prediction>(predict_reg, test_reg$vs)> ROCPer <->performance>(ROCPred, measure =>'tpr'>,> >x.measure =>'fpr'>)> auc <->performance>(ROCPred, measure =>'auc'>)> auc <- [email protected][[1]]> auc> # Plotting curve> plot>(ROCPer)> plot>(ROCPer, colorize =>TRUE>,> >print.cutoffs.at =>seq>(0.1, by = 0.1),> >main =>'ROC CURVE'>)> abline>(a = 0, b = 1)> auc <->round>(auc, 4)> legend>(.6, .4, auc, title =>'AUC'>, cex = 1)> |
자바 8
>
>
산출:
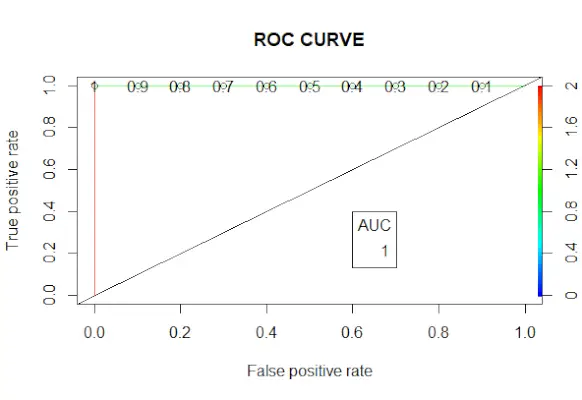
ROC 곡선
예 2:
R에서 설정된 로지스틱 회귀 모델 Titanic Data를 수행할 수 있습니다.
아르 자형
# Load the dataset> data>(Titanic)> # Convert the table to a data frame> data <->as.data.frame>(Titanic)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # View the summary of the model> summary>(model)> |
>
>
산출:
Call: glm(formula = Survived ~ Class + Sex + Age, family = binomial, data = data) Deviance Residuals: Min 1Q Median 3Q Max -1.177 -1.177 0.000 1.177 1.177 Coefficients: Estimate Std. Error z value Pr(>|z|) (절편) 4.022e-16 8.660e-01 0 1 Class2nd -9.762e-16 1.000e+00 0 1 Class3rd -4.699e-16 1.000e+00 0 1 ClassCrew -5.551e-16 1.000e+ 00 0 1 Sex Female -3.140e-16 7.071e-01 0 1 AgeAdult 5.103e-16 7.071e-01 0 1 (이항 모임에 대한 분산 매개변수는 1로 간주됨) 영 이탈도: 31 자유도에서 44.361 잔여 이탈도: 44.361 26 자유도 AIC: 56.361 Fisher 득점 반복 횟수: 2>
타이타닉 데이터 세트에 대한 ROC 곡선 그리기
아르 자형
# Install and load the required packages> install.packages>(>'ROCR'>)> library>(ROCR)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # Make predictions on the dataset> predictions <->predict>(model, type =>'response'>)> # Create a prediction object for ROCR> prediction_objects <->prediction>(predictions, titanic_df$Survived)> # Create an ROC curve object> roc_object <->performance>(prediction_obj, measure =>'tpr'>, x.measure =>'fpr'>)> # Plot the ROC curve> plot>(roc_object, main =>'ROC Curve'>, col =>'blue'>, lwd = 2)> # Add labels and a legend to the plot> legend>(>'bottomright'>, legend => >paste>(>'AUC ='>,>round>(>performance>(prediction_objects, measure =>'auc'>)> >@y.values[[1]], 2)), col =>'blue'>, lwd = 2)> |
>
>
산출:
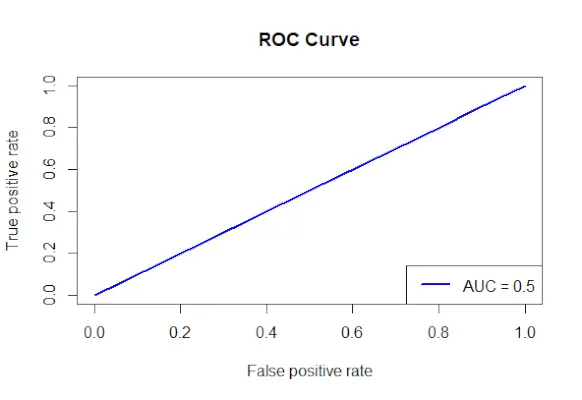
ROC 곡선
- 생존자를 예측하는 데 사용되는 요인이 지정되고, 생존자 클래스 + 성별 + 연령 공식을 사용하여 로지스틱 회귀 모델을 생성합니다.
- 예측() 함수를 사용하면 적합 모델을 사용하여 데이터 세트에 대한 예측이 이루어집니다.
- 예상 확률은 실제 결과 값과 결합되어 ROCR 패키지의 예측() 메서드를 사용하여 예측 개체를 만듭니다.
- 참양성률(tpr) 측정값과 거짓양성률(fpr)의 x축 측정값을 지정하고 ROCR 패키지의 Performance() 함수를 사용하여 ROC 곡선 객체를 생성합니다.
- 기본 제목, 색상, 선 너비를 지정하는 ROC 곡선 객체(roc_obj)는plot() 함수를 사용하여 그려집니다.
- AUC(곡선 아래 영역) 값을 결정하기 위해 측정값 = auc인 Performance() 함수를 사용하고 플롯에 레이블과 범례를 추가합니다.