Python에서는 나중에 사용하기 위해 개체를 디스크에 저장해야 하는 경우가 있습니다. 이는 Python 피클을 사용하여 수행할 수 있습니다. 이 기사에서는 몇 가지 예와 함께 Python의 피클에 대해 알아봅니다.
Python Pickle — Python 객체 직렬화
파이썬 피클 모듈 Python 객체 구조를 직렬화 및 역직렬화하는 데 사용됩니다. Python의 모든 객체는 디스크에 저장될 수 있도록 피클링될 수 있습니다. Pickle이 하는 일은 객체를 파일에 쓰기 전에 먼저 객체를 직렬화하는 것입니다. 피클링은 Python 객체(목록, 사전 등)를 문자 스트림으로 변환하는 방법입니다. 아이디어는 이 문자 스트림이 다른 객체에서 객체를 재구성하는 데 필요한 모든 정보를 포함한다는 것입니다. 파이썬 스크립트. 이는 Python 객체를 바이트 스트림으로 변환하는 기능을 제공합니다. 이 바이트 스트림에는 객체에 대한 모든 필수 정보가 포함되어 있어 Python에서 객체를 재구성하거나 피클 해제하고 원래 형식으로 되돌릴 수 있습니다.
자바 메소드 오버라이딩
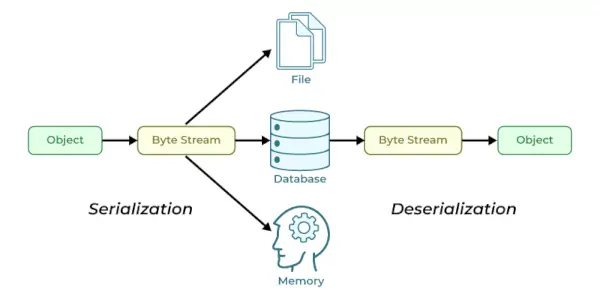
직렬화 작업
Python 피클 예
파일 없이 피클링
이 예에서는 사전 데이터를 직렬화하고 이를 바이트 스트림에 저장합니다. 그런 다음 이 데이터는 다음을 사용하여 역직렬화됩니다. 피클.로드() 함수를 원래 Python 객체로 되돌립니다.
파이썬3
import> pickle> # initializing data to be stored in db> Omkar>=> {>'key'> :>'Omkar'>,>'name'> :>'Omkar Pathak'>,> 'age'> :>21>,>'pay'> :>40000>}> Jagdish>=> {>'key'> :>'Jagdish'>,>'name'> :>'Jagdish Pathak'>,> 'age'> :>50>,>'pay'> :>50000>}> # database> db>=> {}> db[>'Omkar'>]>=> Omkar> db[>'Jagdish'>]>=> Jagdish> # For storing> # type(b) gives ;> b>=> pickle.dumps(db)> # For loading> myEntry>=> pickle.loads(b)> print>(myEntry)> |
>
str을 int로
>
산출:
지도용 자바 반복자
{'Omkar': {'key': 'Omkar', 'name': 'Omkar Pathak', 'age': 21, 'pay': 40000}, 'Jagdish': {'key': 'Jagdish', 'name': 'Jagdish Pathak', 'age': 50, 'pay': 50000}}> 파일로 피클링
이 예에서는 피클 파일을 사용하여 먼저 pickle.dump() 함수를 사용하여 데이터를 작성합니다. 그런 다음 pickle.load() 함수를 사용하여 Python 스크립트에 피클 파인을 로드하고 해당 데이터를 Python 사전 형식으로 인쇄합니다.
파이썬3
# Python3 program to illustrate store> # efficiently using pickle module> # Module translates an in-memory Python object> # into a serialized byte stream—a string of> # bytes that can be written to any file-like object.> import> pickle> def> storeData():> ># initializing data to be stored in db> >Omkar>=> {>'key'> :>'Omkar'>,>'name'> :>'Omkar Pathak'>,> >'age'> :>21>,>'pay'> :>40000>}> >Jagdish>=> {>'key'> :>'Jagdish'>,>'name'> :>'Jagdish Pathak'>,> >'age'> :>50>,>'pay'> :>50000>}> ># database> >db>=> {}> >db[>'Omkar'>]>=> Omkar> >db[>'Jagdish'>]>=> Jagdish> > ># Its important to use binary mode> >dbfile>=> open>(>'examplePickle'>,>'ab'>)> > ># source, destination> >pickle.dump(db, dbfile)> >dbfile.close()> def> loadData():> ># for reading also binary mode is important> >dbfile>=> open>(>'examplePickle'>,>'rb'>)> >db>=> pickle.load(dbfile)> >for> keys>in> db:> >print>(keys,>'=>'>, db[keys])> >dbfile.close()> if> __name__>=>=> '__main__'>:> >storeData()> >loadData()> |
>
자바에서 잡아보세요
>
산출:
Omkar =>{'key': 'Omkar', 'name': 'Omkar Pathak', 'age': 21, 'pay': 40000} Jagdish => {'key ': 'Jagdish', 'name': 'Jagdish Pathak', '나이': 50, '지불': 50000}> Python에서 Pickle을 사용하면 얻을 수 있는 이점
- 재귀 객체(자신에 대한 참조를 포함하는 객체): Pickle은 이미 직렬화된 객체를 추적하므로 나중에 동일한 객체에 대한 참조가 다시 직렬화되지 않습니다. (이 때문에 마샬 모듈이 중단됩니다.)
- 객체 공유(다른 장소의 동일한 객체에 대한 참조): 이는 자기 참조 객체와 유사합니다. Pickle은 객체를 한 번 저장하고 다른 모든 참조가 마스터 복사본을 가리키는지 확인합니다. 공유 객체는 공유된 상태로 유지되며 이는 변경 가능한 객체에 매우 중요할 수 있습니다.
- 사용자 정의 클래스 및 해당 인스턴스: Marshal은 이를 전혀 지원하지 않지만 Pickle은 클래스 인스턴스를 투명하게 저장하고 복원할 수 있습니다. 클래스 정의는 가져올 수 있어야 하며 객체가 저장되었을 때와 동일한 모듈에 있어야 합니다.
Python에서 Pickle을 사용할 때의 단점
- Python 버전 종속성: picle의 데이터는 생성된 Python 버전에 매우 민감합니다. 다양한 버전에서는 피클 해제되지 않을 수 있는 Python의 한 버전으로 생성된 피클된 개체입니다.
- 읽을 수 없음: 피클의 형식은 바이너리이며 사람이 쉽게 읽거나 편집할 수 없습니다. JSON 또는 XML 형식의 계약은 쉽게 수정할 수 있습니다.
- 대용량 데이터의 비효율성: 데이터 세트가 크면 산세 및 산세 해제 속도가 느려질 수 있습니다. 이러한 사용 사례에는 직렬화가 더 적합할 수 있습니다.
결론
Python Pickle은 객체 직렬화 기능을 제공하지만 개발자는 특히 다양한 Python 버전에서 작업하거나 대규모 데이터 세트를 처리하는 동안 제한 사항을 유지해야 합니다. ickle 또는 JSON, XML과 같은 대안이 직렬화에 적합한지 결정하려면 항상 애플리케이션의 특정 요구 사항을 고려하는 것이 중요합니다.