사육사 분산 애플리케이션을 위한 분산 오픈 소스 조정 서비스입니다. 이는 동기화, 구성 유지 관리, 그룹 및 이름 지정을 위한 상위 수준 서비스를 구현하기 위한 간단한 기본 요소 집합을 노출합니다.
분산 시스템에는 서로 통신하고 작업을 조정해야 하는 여러 노드 또는 시스템이 있습니다. ZooKeeper는 이러한 노드가 서로를 인식하고 작업을 조정할 수 있도록 하는 방법을 제공합니다. 이는 데이터 노드의 계층적 트리를 유지함으로써 이를 수행합니다. Z노드 , 데이터를 저장 및 검색하고 상태 정보를 유지하는 데 사용할 수 있습니다. ZooKeeper는 분산 시스템에서 노드의 작업을 조정하는 데 사용할 수 있는 잠금, 장벽, 대기열과 같은 일련의 기본 요소를 제공합니다. 또한 리더 선택, 장애 조치, 복구 등의 기능을 제공하여 시스템 장애에 대한 복원력을 보장합니다. ZooKeeper는 Hadoop, Kafka, HBase 등 분산 시스템에서 널리 사용되며 많은 분산 애플리케이션의 필수 구성 요소가 되었습니다.
왜 필요한가요?
- 조정 서비스 : 분산 환경에서 서비스의 통합/통신.
- 조정 서비스는 제대로 작동하기가 복잡합니다. 특히 경쟁 조건이나 교착 상태와 같은 오류가 발생하기 쉽습니다.
- 경쟁 조건 - 두 개 이상의 시스템이 어떤 작업을 수행하려고 합니다.
- 교착상태 – 두 개 이상의 작업이 서로 기다리고 있습니다.
- 분산 환경 간의 조정을 쉽게 하기 위해 개발자는 조정 서비스 구현 책임을 분산 애플리케이션에서 처음부터 덜어낼 필요가 없도록 주키퍼(zookeeper)라는 아이디어를 내놓았습니다.
분산 시스템이란 무엇입니까?
- 단일 문제를 해결하기 위해 여러 컴퓨터 시스템이 작동합니다.
- 분산 미들웨어를 사용하여 연결된 자율 컴퓨터로 구성된 네트워크입니다.
- 주요 특징들 : 동시, 리소스 공유, 독립적, 전역, 더 큰 내결함성 및 가격 대비 성능 비율이 훨씬 좋습니다.
- 핵심 목표 s: 투명성, 신뢰성, 성능, 확장성.
- 도전과제 : 보안, 결함, 조정 및 리소스 공유.
코디네이션 챌린지
- 분산 시스템에서 조정이 어려운 문제인 이유는 무엇입니까?
- 많은 시스템이 있는 분산 애플리케이션에 대한 조정 또는 구성 관리.
- 클러스터 데이터가 저장되는 마스터 노드입니다.
- 작업자 노드 또는 슬레이브 노드는 이 마스터 노드에서 데이터를 가져옵니다.
- 단일 실패 지점.
- 동기화가 쉽지 않습니다.
- 신중한 설계와 구현이 필요합니다.
아파치 사육사
Apache Zookeeper는 분산 시스템을 위한 분산 오픈 소스 조정 서비스입니다. 이는 분산 애플리케이션이 데이터를 저장하고, 서로 통신하고, 활동을 조정하는 중앙 장소를 제공합니다. Zookeeper는 분산 프로세스와 서비스를 조정하기 위해 분산 시스템에서 사용됩니다. 간단한 트리 구조의 데이터 모델, 간단한 API 및 분산 프로토콜을 제공하여 데이터 일관성과 가용성을 보장합니다. Zookeeper는 안정성과 내결함성이 뛰어나도록 설계되었으며 높은 수준의 읽기 및 쓰기 처리량을 처리할 수 있습니다.
Zookeeper는 Java로 구현되며 분산 시스템, 특히 Hadoop 생태계에서 널리 사용됩니다. 이는 Apache Software Foundation 프로젝트이며 Apache License 2.0에 따라 릴리스됩니다.
사육사의 아키텍처
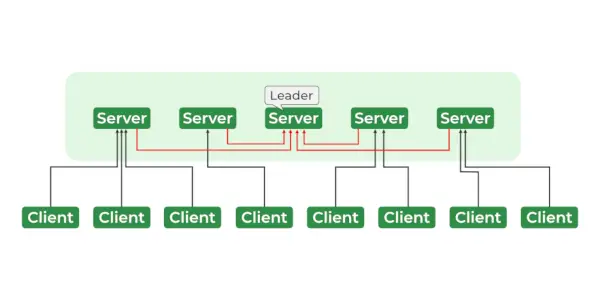
사육사 서비스
ZooKeeper 아키텍처는 트리형 구조로 구성된 znode라는 노드 계층으로 구성됩니다. 각 znode는 데이터를 저장할 수 있으며 znode에 대한 액세스를 제어하는 권한 집합을 갖습니다. znode는 파일 시스템과 유사한 계층적 네임스페이스로 구성됩니다. 계층 구조의 루트에는 루트 znode가 있고 다른 모든 znode는 루트 znode의 하위 노드입니다. 계층 구조는 각 znode가 자식과 손자 등을 가질 수 있는 파일 시스템 계층과 유사합니다.
Zookeeper의 중요한 구성 요소
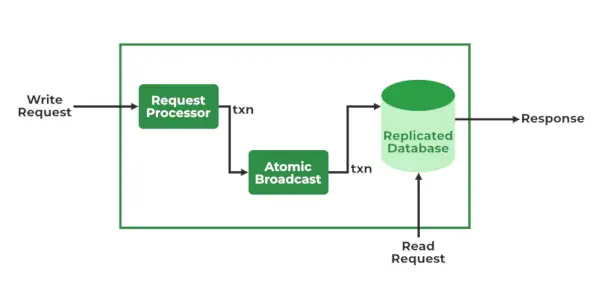
ZooKeeper 서비스
- 리더 & 추종자
- 요청 프로세서 – 리더 노드에서 활동하며 쓰기 요청 처리를 담당합니다. 처리 후 변경 사항을 팔로어 노드로 보냅니다.
- 원자 방송 – 리더 노드와 추종자 노드 모두에 존재합니다. 변경 사항을 다른 노드로 보내는 역할을 담당합니다.
- 인메모리 데이터베이스 (복제된 데이터베이스) - 사육사에 데이터를 저장하는 역할을 담당합니다. 모든 노드에는 자체 데이터베이스가 포함되어 있습니다. 또한 클러스터에 문제가 있는 경우 복구 가능성을 제공하기 위해 데이터가 파일 시스템에 기록됩니다.
기타 구성요소
- 고객 – 분산 애플리케이션 클러스터의 노드 중 하나입니다. 서버의 정보에 액세스합니다. 모든 클라이언트는 서버에 메시지를 보내 클라이언트가 살아 있음을 서버에 알립니다.
- 섬기는 사람 – 클라이언트에게 모든 서비스를 제공합니다. 클라이언트에게 승인을 제공합니다.
- 앙상블 – Zookeeper 서버 그룹. 앙상블을 구성하는 데 필요한 최소 노드 수는 3개입니다.
사육사 데이터 모델
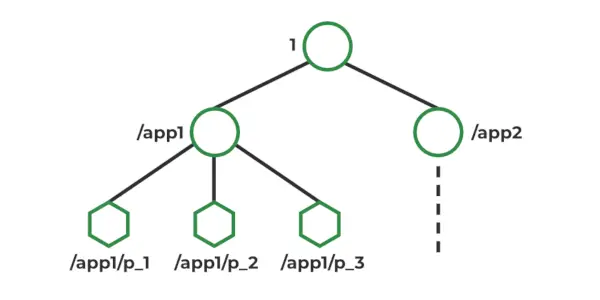
ZooKeeper 데이터 모델
Zookeeper에서 데이터는 파일 시스템과 유사한 계층적 네임스페이스에 저장됩니다. 네임스페이스의 각 노드를 Znode라고 하며 데이터를 저장하고 하위 노드를 가질 수 있습니다. Znode는 파일 시스템의 파일 및 디렉터리와 유사합니다. Zookeeper는 Znode 생성, 읽기, 쓰기 및 삭제를 위한 간단한 API를 제공합니다. 또한 감시 및 트리거와 같이 Znode에 저장된 데이터의 변경 사항을 감지하는 메커니즘도 제공합니다. Znode는 버전 번호, ACL, 타임스탬프, 데이터 길이를 포함하는 통계 구조를 유지합니다.
Znode 유형 :
- 고집 : 명시적으로 삭제될 때까지 살아 있습니다.
- 임시 : 클라이언트 연결이 활성화될 때까지 활성화됩니다.
- 잇달아 일어나는 : 지속적이거나 임시적입니다.
Hadoop에 ZooKeeper가 필요한 이유는 무엇입니까?
Zookeeper는 NameNode, DataNode 및 ResourceManager를 포함하여 Hadoop 클러스터의 노드를 관리하고 조정하는 데 사용됩니다. Hadoop 클러스터에서 Zookeeper는 다음을 지원합니다.
- 구성 정보 유지: Zookeeper는 NameNode, DataNode 및 ResourceManager의 위치를 포함하여 Hadoop 클러스터에 대한 구성 정보를 저장합니다.
- 클러스터 상태 관리: Zookeeper는 Hadoop 클러스터의 노드 상태를 추적하고 노드가 실패하거나 사용할 수 없게 된 시기를 감지하는 데 사용할 수 있습니다.
- 분산 프로세스 조정: Zookeeper를 사용하여 Hadoop 클러스터의 노드 전체에서 작업 예약 및 리소스 할당과 같은 분산 프로세스를 조정할 수 있습니다.
Zookeeper는 클러스터의 노드에 대한 중앙 조정 서비스를 제공하여 Hadoop 클러스터의 가용성과 안정성을 보장하는 데 도움을 줍니다.
Hadoop의 ZooKeeper는 어떻게 작동하나요?
ZooKeeper는 분산 파일 시스템으로 작동하며 클라이언트가 파일 시스템에서 데이터를 읽고 쓸 수 있도록 하는 간단한 API 세트를 제공합니다. znode라는 트리 구조에 데이터를 저장합니다. znode는 기존 파일 시스템의 파일이나 디렉터리로 생각할 수 있습니다. ZooKeeper는 합의 알고리즘을 사용하여 모든 서버가 Znode에 저장된 데이터에 대한 일관된 보기를 갖도록 합니다. 이는 클라이언트가 znode에 데이터를 쓰면 해당 데이터가 ZooKeeper 앙상블의 다른 모든 서버에 복제된다는 것을 의미합니다.
ZooKeeper의 중요한 기능 중 하나는 시계 개념을 지원하는 기능입니다. watch를 사용하면 znode에 저장된 데이터가 변경될 때 클라이언트가 알림을 등록할 수 있습니다. 이는 ZooKeeper에 저장된 데이터의 변경 사항을 모니터링하고 분산 시스템에서 해당 변경 사항에 대응하는 데 유용할 수 있습니다.
Hadoop에서 ZooKeeper는 다음을 포함한 다양한 목적으로 사용됩니다.
- 구성 정보 저장: ZooKeeper는 여러 Hadoop 구성 요소에서 공유하는 구성 정보를 저장하는 데 사용됩니다. 예를 들어 Hadoop 클러스터의 NameNode 위치나 JobTracker 노드의 주소를 저장하는 데 사용될 수 있습니다.
- 분산 동기화 제공: ZooKeeper는 다양한 Hadoop 구성 요소의 활동을 조정하고 일관된 방식으로 함께 작동하는지 확인하는 데 사용됩니다. 예를 들어 Hadoop 클러스터에서 한 번에 하나의 NameNode만 활성화되도록 하는 데 사용될 수 있습니다.
- 이름 유지 관리: ZooKeeper는 Hadoop 구성 요소에 대한 중앙 집중식 이름 지정 서비스를 유지하는 데 사용됩니다. 이는 분산 시스템에서 리소스를 식별하고 찾는 데 유용할 수 있습니다.
ZooKeeper는 Hadoop의 필수 구성 요소이며 다양한 하위 구성 요소의 활동을 조정하는 데 중요한 역할을 합니다.
Apache Zookeeper에서 읽기 및 쓰기
ZooKeeper는 데이터 읽기 및 쓰기를 위한 간단하고 안정적인 인터페이스를 제공합니다. 데이터는 znode라는 노드가 있는 파일 시스템과 유사한 계층적 네임스페이스에 저장됩니다. 각 znode는 데이터를 저장할 수 있으며 하위 znode를 가질 수 있습니다. ZooKeeper 클라이언트는 각각 getData() 및 setData() 메서드를 사용하여 이러한 znode에 데이터를 읽고 쓸 수 있습니다. 다음은 ZooKeeper Java API를 사용하여 데이터를 읽고 쓰는 예입니다.
자바
// Connect to the ZooKeeper ensemble> ZooKeeper zk =>new> ZooKeeper(>'localhost:2181'>,>3000>,>null>);> // Write data to the znode '/myZnode'> String path =>'/myZnode'>;> String data =>'hello world'>;> zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);> // Read data from the znode '/myZnode'> byte>[] bytes = zk.getData(path,>false>,>null>);> String readData =>new> String(bytes);> // Prints 'hello world'> System.out.println(readData);> // Closing the connection> // to the ZooKeeper ensemble> zk.close();> |
>
>
파이썬3
from> kazoo.client>import> KazooClient> # Connect to ZooKeeper> zk>=> KazooClient(hosts>=>'localhost:2181'>)> zk.start()> # Create a node with some data> zk.ensure_path(>'/gfg_node'>)> zk.>set>(>'/gfg_node'>, b>'some_data'>)> # Read the data from the node> data, stat>=> zk.get(>'/gfg_node'>)> print>(data)> # Stop the connection to ZooKeeper> zk.stop()> |
>
라텍스 매트릭스
>
세션 및 감시
세션
- 세션의 요청은 FIFO 순서로 실행됩니다.
- 세션이 설정되면 다음은 세션 ID 클라이언트에 할당됩니다.
- 클라이언트가 보냅니다. 심장 박동 세션을 유효하게 유지하려면
- 세션 시간 초과는 일반적으로 밀리초 단위로 표시됩니다.
시계
- Watch는 클라이언트가 Zookeeper의 변경 사항에 대한 알림을 받는 메커니즘입니다.
- 클라이언트는 특정 znode를 읽는 동안 볼 수 있습니다.
- Znode 변경은 znode와 관련된 데이터의 수정 또는 znode의 하위 변경입니다.
- 감시는 한 번만 트리거됩니다.
- 세션이 만료되면 시계도 제거됩니다.