균형 이진 트리는 높이 균형 트리라고도 합니다. 왼쪽 하위 트리와 오른쪽 하위 트리의 높이 차이가 m 이하일 때 이진 트리로 정의됩니다. 여기서 m은 일반적으로 1과 같습니다. 트리의 높이는 두 트리 사이의 가장 긴 경로에 있는 간선의 수입니다. 루트 노드와 리프 노드.
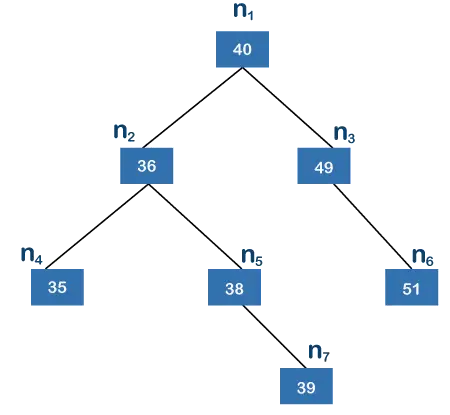
위의 트리는 이진 검색 트리 . 이진 검색 트리는 왼쪽에 있는 각 노드가 상위 노드보다 낮은 값을 갖고, 오른쪽에 있는 노드가 상위 노드보다 높은 값을 갖는 트리입니다. 위 트리에서 n1은 루트 노드이고 n4, n6, n7은 리프 노드입니다. n7 노드는 루트 노드에서 가장 먼 노드입니다. n4와 n6에는 2개의 간선이 있고 루트 노드와 n7 노드 사이에는 3개의 간선이 있습니다. n7이 루트 노드에서 가장 멀기 때문에; 따라서 위 트리의 높이는 3입니다.
문자를 문자열로 변환
이제 위의 트리가 균형을 이루고 있는지 여부를 살펴보겠습니다. 왼쪽 하위 트리에는 노드 n2, n4, n5 및 n7이 포함되어 있고 오른쪽 하위 트리에는 노드 n3 및 n6이 포함되어 있습니다. 왼쪽 하위 트리에는 두 개의 리프 노드, 즉 n4와 n7이 있습니다. 노드 n2와 n4 사이에는 단 하나의 간선이 있고 노드 n7과 n2 사이에는 두 개의 간선만 있습니다. 따라서 노드 n7은 루트 노드에서 가장 멀리 떨어져 있습니다. 왼쪽 하위 트리의 높이는 2입니다. 오른쪽 하위 트리에는 리프 노드가 하나만 포함되어 있습니다(예: n6). 가장자리도 하나만 있습니다. 따라서 오른쪽 하위 트리의 높이는 1입니다. 왼쪽 하위 트리와 오른쪽 하위 트리의 높이 차이는 1입니다. 값이 1이므로 위 트리는 높이 균형 트리라고 말할 수 있습니다. 높이 차이를 계산하는 이 과정은 n2, n3, n4, n5, n6, n7과 같은 각 노드에 대해 수행되어야 합니다. 각 노드를 처리하면 k의 값이 1보다 크지 않다는 것을 알 수 있으므로 위의 트리는 균형 잡힌 트리라고 말할 수 있습니다. 이진 트리 .

위 트리에서 n6, n4, n3은 리프 노드이며, 여기서 n6은 루트 노드에서 가장 먼 노드입니다. 루트 노드와 리프 노드 사이에는 세 개의 간선이 존재합니다. 따라서 위 트리의 높이는 3입니다. n1을 루트 노드로 간주하면 왼쪽 하위 트리에는 노드 n2, n4, n5 및 n6이 포함되고 하위 트리에는 노드 n3이 포함됩니다. 왼쪽 하위 트리에서 n2는 루트 노드이고, n4와 n6은 리프 노드입니다. n4 및 n6 노드 중 n6은 루트 노드에서 가장 먼 노드이고 n6에는 두 개의 가장자리가 있습니다. 따라서 왼쪽 하위 트리의 높이는 2입니다. 오른쪽 하위 트리에는 왼쪽과 오른쪽에 자식이 있습니다. 따라서 오른쪽 하위 트리의 높이는 0입니다. 왼쪽 하위 트리의 높이는 2이고 오른쪽 하위 트리의 높이는 0이므로 왼쪽 하위 트리와 오른쪽 하위 트리의 높이 차이는 2입니다. 정의에 따르면 차이는 다음과 같습니다. 왼쪽 하위 트리와 오른쪽 하위 트리 사이의 높이는 1보다 클 수 없습니다. 이 경우 차이는 2가 되며 이는 1보다 큽니다. 따라서 위의 이진 트리는 불균형 이진 검색 트리입니다.
균형 잡힌 이진 트리가 필요한 이유는 무엇입니까?
예를 통해 균형 이진 트리의 필요성을 이해해 보겠습니다.

위 트리는 모든 왼쪽 하위 트리 노드가 상위 노드보다 작고 모든 오른쪽 하위 트리 노드가 상위 노드보다 크기 때문에 이진 검색 트리입니다. 위의 트리에서 값 79를 찾고 싶다고 가정해 보겠습니다. 먼저 노드 n1의 값을 79와 비교합니다. 79의 값은 35와 같지 않고 35보다 크므로 노드 n3, 즉 48로 이동합니다. 값 79는 48과 같지 않고 79는 48보다 크므로 오른쪽으로 이동합니다. 48의 자식. 노드 48의 오른쪽 자식 값은 검색할 값과 동일한 79입니다. 요소 79를 검색하는 데 필요한 홉 수는 2이고, 어떤 요소를 검색하는 데 필요한 최대 홉 수는 2입니다. 요소를 검색하는 평균 경우는 O(logn)입니다.

위 트리는 모든 왼쪽 하위 트리 노드가 상위 노드보다 작고 모든 오른쪽 하위 트리 노드가 상위 노드보다 크기 때문에 이진 검색 트리이기도 합니다. 위의 트리에서 값 79를 찾고 싶다고 가정해 보겠습니다. 먼저 값 79를 노드 n4, 즉 13과 비교합니다. 값 79가 13보다 크므로 노드 13의 오른쪽 자식, 즉 n2(21)로 이동합니다. 노드 n2의 값은 79보다 작은 21이므로 다시 노드 21의 오른쪽으로 이동합니다. 노드 21의 오른쪽 자식 값은 29입니다. 값 79가 29보다 크므로 오른쪽으로 이동합니다. 노드 29의 자식입니다. 노드 29의 오른쪽 자식 값은 35로 79보다 작으므로 노드 35의 오른쪽 자식, 즉 48로 이동합니다. 값 79는 48보다 크므로 오른쪽 자식으로 이동합니다. 노드 48의 오른쪽 자식 노드 48의 값은 검색할 값과 동일한 79입니다. 이 경우 요소를 찾는 데 필요한 홉 수는 5이다. 이 경우 최악의 경우는 O(n)이다.
노드 수가 증가하면 수형도1에 사용된 수식은 수형도2에 사용된 수식보다 효율적입니다. 위의 두 트리 모두에서 사용 가능한 노드 수가 100,000개라고 가정합니다. 트리 다이어그램2에서 요소를 검색하는 데 걸리는 시간은 100,000μs인 반면 트리 다이어그램에서 요소를 검색하는 데 걸리는 시간은 log(100,000)이며 이는 16.6μs와 같습니다. 우리는 위의 두 나무 사이에 엄청난 시간 차이가 있음을 관찰할 수 있습니다. 따라서 균형 이진 트리가 선형 트리 데이터 구조보다 더 빠른 검색을 제공한다고 결론을 내립니다.