Java는 다양성, 이식성 및 광범위한 응용 프로그램으로 잘 알려진 세계에서 가장 인기 있는 프로그래밍 언어 중 하나입니다. Java는 기능과 성능으로 인해 Uber, Airbnb, Google, Netflix, Instagram, Spotify, Amazon 등 최고의 기업에서 가장 많이 사용되는 언어입니다.
이 기사에서는 다음을 제공합니다. 200개 이상의 핵심 Java 인터뷰 질문 3년, 5년, 8년의 경험을 가진 신입 전문가와 숙련된 전문가 모두를 위해 맞춤 제작되었습니다. 여기에서는 핵심 Java 개념, 객체 지향 프로그래밍(OOP), 멀티스레딩, 예외 처리, 디자인 패턴, Java 컬렉션 등을 포함하여 Java 인터뷰를 통과하는 데 확실히 도움이 될 모든 것을 다룹니다.

내용의 테이블
신입생을 위한 Java 인터뷰 질문
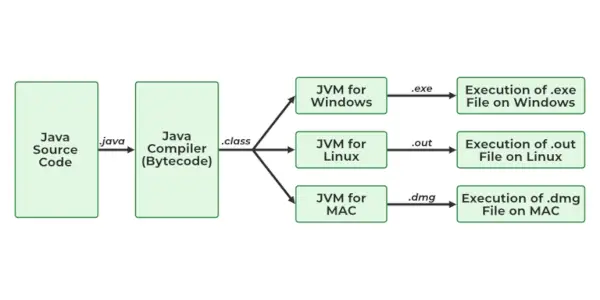
1. 그렇다면 Java 플랫폼은 어떻게 독립적입니까?
예, Java는 플랫폼 독립적인 언어입니다. 많은 프로그래밍 언어와 달리 javac 컴파일러는 프로그램을 컴파일하여 바이트코드 또는 .class 파일을 형성합니다. 이 파일은 실행 중인 소프트웨어나 하드웨어와 독립적이지만 바이트코드를 추가로 실행하려면 운영 체제에 사전 설치된 JVM(Java Virtual Machine) 파일이 필요합니다.
하지만 JVM은 플랫폼에 따라 다릅니다. , 바이트 코드는 모든 시스템에서 생성될 수 있으며 Java 플랫폼을 독립적으로 만드는 하드웨어나 소프트웨어가 사용됨에도 불구하고 다른 시스템에서 실행될 수 있습니다.
2. 최고의 Java 기능은 무엇입니까?
Java는 현실 세계에서 가장 유명하고 가장 많이 사용되는 언어 중 하나입니다. Java에는 다른 언어보다 더 나은 기능을 제공하는 많은 기능이 있으며 그 중 일부는 아래에 언급되어 있습니다.
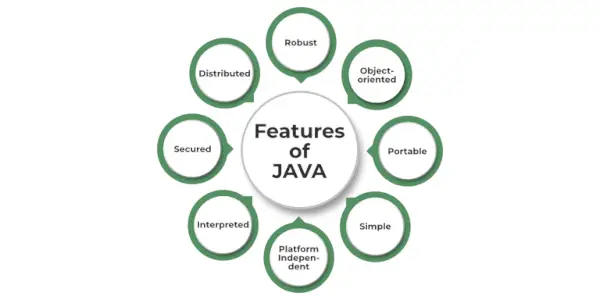
- 단순한 : Java는 이해하기 매우 간단하고 구문도 매우 간단합니다.
- 플랫폼 독립적: Java는 플랫폼 독립적이라는 의미입니다. 즉, 모든 소프트웨어 및 하드웨어에서 동일한 프로그램을 실행할 수 있으며 동일한 결과를 얻을 수 있습니다.
- 해석됨 : Java는 컴파일러 기반 언어와 마찬가지로 해석됩니다.
- 건장한 : 언어를 강력하게 만드는 가비지 수집, 예외 처리 등과 같은 기능입니다.
- 객체지향 : Java는 클래스, 객체, OOPS의 네 가지 기본 개념 등을 지원하는 객체 지향 언어입니다.
- 보안됨 : 실제 프로그램을 공유하지 않고 사용자와 직접 애플리케이션을 공유할 수 있으므로 Java는 안전한 언어입니다.
- 고성능: 다른 전통적인 해석 프로그래밍 언어보다 빠릅니다.
- 동적 : 클래스와 인터페이스의 동적 로딩을 지원합니다.
- 분산 : Java의 기능을 사용하면 연결된 모든 시스템에서 메소드를 호출하여 파일에 액세스할 수 있습니다.
- 멀티스레드 : 여러 스레드를 정의하여 여러 작업을 한 번에 처리
- 아키텍처 중립 : 아키텍처에 의존하지 않습니다.
3. JVM이란 무엇입니까?
JVM은 Java Virtual Machine의 약자로 Java 인터프리터입니다. Java로 생성된 바이트코드를 로드, 확인 및 실행하는 역할을 담당합니다.
플랫폼에 따라 다르지만 JVM의 소프트웨어는 운영 체제마다 다릅니다. 이는 Java 플랫폼을 독립적으로 만드는 데 중요한 역할을 합니다.
주제에 대해 더 자세히 알고 싶으면 다음을 참조하세요. 자바의 JVM .
4. JIT란 무엇인가요?
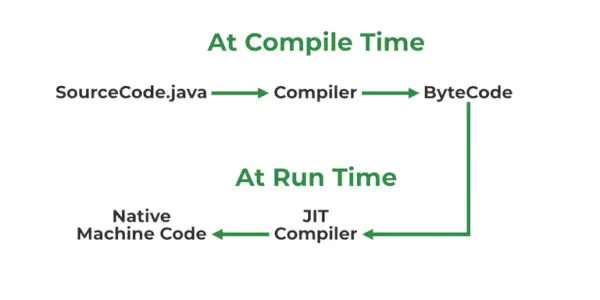
JIT(Just-in-Time) 컴파일러는 JRE(Java Runtime Environment)의 일부로 런타임 중에 Java 애플리케이션의 성능을 향상시키는 데 사용됩니다. JIT의 사용은 아래에 언급된 단계별 프로세스에 언급되어 있습니다.
- 소스 코드는 다음과 같이 컴파일됩니다. javac 바이트코드를 형성하는 컴파일러
- 바이트코드는 JVM으로 추가로 전달됩니다.
- JIT는 JVM의 일부이며, JIT는 런타임에 바이트코드를 기본 기계어 코드로 컴파일하는 역할을 담당합니다.
- JIT 컴파일러는 메소드가 호출될 때 활성화되는 동안 전체적으로 활성화됩니다. 컴파일된 메소드의 경우 JVM은 컴파일된 코드를 해석하는 대신 직접 호출합니다.
- JVM은 실행 성능과 속도를 높이는 컴파일된 코드를 호출합니다.
주제에 대해 더 자세히 알고 싶으면 다음을 참조하세요. 자바의 JIT .
5. JVM에서 사용할 수 있는 메모리 저장소는 무엇입니까?
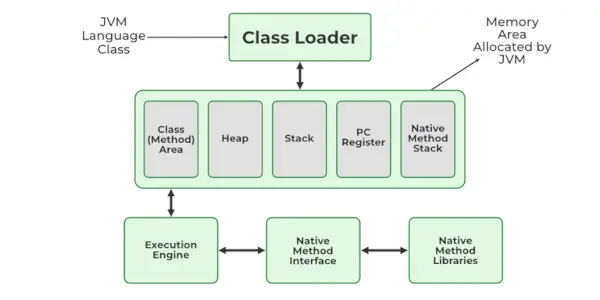
JVM은 아래와 같이 몇 가지 메모리 저장소로 구성됩니다.
- 클래스(메소드) 영역: 런타임 상수 풀, 필드, 메소드 데이터 등 모든 클래스의 클래스 수준 데이터와 메소드에 대한 코드가 저장됩니다.
- 힙: 개체가 생성되거나 개체가 저장됩니다. 런타임 중에 객체에 메모리를 할당하는 데 사용됩니다.
- 스택: 메소드에 대한 값을 반환하고 동적 연결을 수행하는 동안 필요한 데이터 및 부분 결과를 저장합니다.
- 프로그램 카운터 레지스터: 현재 실행 중인 JVM(Java Virtual Machine) 명령어의 주소를 저장합니다.
- 네이티브 메서드 스택: 애플리케이션에 사용되는 모든 네이티브 메서드를 저장합니다.
주제에 대해 더 자세히 알고 싶으면 다음을 참조하세요. JVM 메모리 저장소 .
6. 클래스로더란 무엇입니까?
클래스로더는 JRE(Java Runtime Environment)의 일부로, 바이트코드나 생성된 .class 파일을 실행하는 동안 Java 클래스와 인터페이스를 JVM(Java Virtual Machine)에 동적으로 로드하는 역할을 담당합니다. 클래스로더로 인해 Java 런타임 시스템은 파일 및 파일 시스템에 대해 알 필요가 없습니다.
주제에 대해 더 자세히 알고 싶으면 다음을 참조하세요. Java의 ClassLoader.
7. JVM, JRE, JDK의 차이점.
JVM : Java Virtual Machine이라고도 알려진 JVM은 JRE의 일부입니다. JVM은 바이트코드를 기계가 읽을 수 있는 코드로 변환하는 역할을 하는 일종의 인터프리터입니다. JVM 자체는 플랫폼에 따라 다르지만 Java가 플랫폼 독립적인 이유인 플랫폼 독립적인 이유인 바이트코드를 해석합니다.
JRE : JRE는 Java Runtime Environment의 약자로, 모든 컴퓨터에서 Java 프로그램이나 애플리케이션을 실행할 수 있는 환경을 제공하는 설치 패키지입니다.
JDK : JDK는 Java Development Kit의 약어로, Java 프로그램을 개발하고 실행할 수 있는 환경을 제공합니다. JDK는 Java 프로그램을 개발할 수 있는 환경을 제공하는 개발 도구와 Java 프로그램 또는 응용 프로그램을 실행하는 JRE 두 가지를 포함하는 패키지입니다.
해당 주제에 대한 자세한 내용은 다음을 참조하세요. JVM, JRE 및 JDK의 차이점 .
8. Java와 C++의 차이점은 무엇입니까?
기초 | C++ | 자바 |
|---|---|---|
플랫폼 | C++는 플랫폼에 따라 다릅니다. | Java는 플랫폼 독립적입니다. |
애플리케이션 | C++는 주로 시스템 프로그래밍에 사용됩니다. | Java는 주로 응용 프로그래밍에 사용됩니다. |
하드웨어 | C++는 하드웨어에 더 가깝습니다. | Java는 하드웨어와 대화형이 아닙니다. |
글로벌 범위 | C++는 전역 및 네임스페이스 범위를 지원합니다. | Java는 전역 범위를 지원하지 않습니다. |
지원하지 않음 | Java에서는 지원되지만 C++에서는 지원되지 않는 기능은 다음과 같습니다.
| C++에서는 지원되지만 Java에서는 지원되지 않는 기능은 다음과 같습니다.
|
이런 | C++는 객체 지향 언어입니다. 이는 단일 루트 계층 구조가 아닙니다. | 자바는 객체지향 언어이기도 합니다. 모든 것이 단일 클래스(java.lang.Object)에서 파생되므로 이는 단일 루트 계층 구조입니다. |
상속 트리 | C++에서는 항상 새로운 상속 트리를 만듭니다. | Java의 클래스는 Java의 객체 클래스의 자식이므로 Java는 단일 상속 트리를 사용합니다. |
9. Java의 public static void main(String args[])에 대해 설명하세요.
C, C++ 등과 같은 다른 프로그래밍 언어와 달리 Java에서는 main 함수를 public static void main(String args[])으로 선언했습니다. 용어의 의미는 다음과 같습니다.
- 공공의 : public은 요소나 메서드에 액세스할 수 있는 사람과 제한 사항을 언급하는 역할을 담당하는 액세스 수정자입니다. 주요 기능을 전역적으로 사용할 수 있게 만드는 일을 담당합니다. 현재 클래스에 없기 때문에 JVM이 클래스 외부에서 호출할 수 있도록 공개됩니다.
- 공전 : static은 불필요한 메모리 할당을 피하기 위해 클래스를 시작하지 않고도 요소를 사용할 수 있도록 사용되는 키워드입니다.
- 무효의 : void는 키워드이며 메서드가 아무것도 반환하지 않음을 지정하는 데 사용됩니다. main 함수는 아무것도 반환하지 않으므로 void를 사용합니다.
- 기본 : main은 선언된 함수가 main 함수임을 나타냅니다. 이는 JVM이 선언된 함수가 기본 함수인지 식별하는 데 도움이 됩니다.
- 문자열 인수[] : Java 명령줄 인수를 저장하며 java.lang.String 클래스 유형의 배열입니다.
10. Java 문자열 풀이란 무엇입니까?
Java 문자열 풀은 프로그램에 정의된 모든 문자열이 저장되는 힙 메모리의 장소입니다. 스택의 별도 위치에는 문자열을 저장하는 변수가 저장됩니다. 새 문자열 객체를 생성할 때마다 JVM은 문자열 풀에 객체가 있는지 확인합니다. 문자열이 풀에서 사용 가능한 경우 동일한 객체 참조가 변수와 공유되고, 그렇지 않으면 새 객체가 생성됩니다.
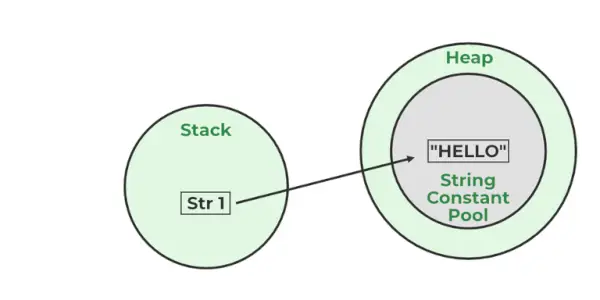
예:
String str1='Hello'; // 'Hello' will be stored in String Pool // str1 will be stored in stack memory>
11. 메인을 정적으로 선언하지 않는다고 선언하면 어떻게 되나요?
정적을 사용하지 않고 오류 없이 기본 메서드를 선언할 수 있습니다. 그러나 기본 메소드는 애플리케이션이나 프로그램의 진입점으로 처리되지 않습니다.
12. Java의 패키지란 무엇입니까?
Java의 패키지는 보호 및 네임스페이스 관리에 대한 액세스를 제공하는 관련 유형의 클래스, 인터페이스 등을 그룹화하는 것으로 정의할 수 있습니다.
13. 패키지를 사용하는 이유는 무엇입니까?
패키지는 이름 충돌을 방지하고 액세스를 제어하며 클래스, 인터페이스 등의 검색/찾기 및 사용을 더 쉽게 만들기 위해 Java에서 사용됩니다.
14. Java 패키지의 장점은 무엇입니까?
Java로 패키지를 정의하면 다양한 이점이 있습니다.
- 패키지는 이름 충돌을 방지합니다.
- 패키지는 더 쉬운 액세스 제어를 제공합니다.
- 외부에 표시되지 않고 패키지에서 사용되는 숨겨진 클래스를 가질 수도 있습니다.
- 관련 클래스를 찾는 것이 더 쉽습니다.
15. Java에는 몇 가지 유형의 패키지가 있습니까?
Java에는 두 가지 유형의 패키지가 있습니다.
- 사용자 정의 패키지
- 빌드인 패키지
16. Java의 다양한 데이터 유형을 설명하십시오.
Java에는 아래와 같이 2가지 유형의 데이터 유형이 있습니다.
- 원시 데이터 유형
- 비기본 데이터 유형 또는 객체 데이터 유형
기본 데이터 유형: 기본 데이터는 특별한 기능이 없는 단일 값입니다. 8가지 기본 데이터 유형이 있습니다.
- 부울 : 값을 true 또는 false로 저장합니다.
- 바이트 : 8비트 부호 있는 2의 보수 정수를 저장합니다.
- 숯 : 단일 16비트 유니코드 문자를 저장합니다.
- 짧은 : 16비트 부호 있는 2의 보수 정수를 저장합니다.
- 정수 : 32비트 부호 있는 2의 보수 정수를 저장합니다.
- 긴 : 64비트 2의 보수 정수를 저장합니다.
- 뜨다 : 단정밀도 32비트 IEEE 754 부동 소수점을 저장합니다.
- 더블 : 배정밀도 64비트 IEEE 754 부동 소수점을 저장합니다.
비원시 데이터 유형: 참조 데이터 유형에는 값을 메모리에 직접 저장할 수 없기 때문에 변수 값의 메모리 주소가 포함됩니다. Non-Primitive의 유형은 다음과 같습니다.
- 문자열
- 정렬
- 수업
- 물체
- 상호 작용
17. 바이트 데이터 유형이 사용되는 경우는 무엇입니까?
바이트는 8비트 부호 있는 2개의 보수 정수입니다. 바이트에서 지원하는 최소값은 -128이고 127이 최대값입니다. 메모리를 절약해야 하는 조건에서 사용되며 필요한 숫자 제한은 -128에서 127 사이입니다.
18. Java에서 포인터를 선언할 수 있나요?
아니요, Java는 포인터를 지원하지 않습니다. Java에서는 포인터의 어떤 기능이 제공되지 않기 때문에 Java가 더 안전해야 했습니다.
19. Java에서 바이트 데이터 유형의 기본값은 무엇입니까?
Java에서 바이트 데이터 유형의 기본값은 0입니다.
20. Java에서 float 및 double 데이터 유형의 기본값은 무엇입니까?
Java에서 float의 기본값은 0.0f이고 double의 기본값은 0.0d입니다.
21. Java의 Wrapper 클래스는 무엇입니까?
일반적으로 래퍼는 더 작은 엔터티를 캡슐화하는 더 큰 엔터티를 말합니다. Java에서 래퍼 클래스는 기본 데이터 유형을 캡슐화하는 객체 클래스입니다.
기본 데이터 유형은 추가 데이터 유형이 생성될 수 있는 유형입니다. 예를 들어, 정수는 long, byte, short 등의 구성으로 이어질 수 있습니다. 반면에 문자열은 그렇게 할 수 없으므로 원시적이지 않습니다.
래퍼 클래스로 돌아가면 Java에는 8개의 래퍼 클래스가 포함되어 있습니다. Boolean, Byte, Short, Integer, Character, Long, Float 및 Double이 있습니다. 또한 C 프로그래밍 언어의 구조 개념과 유사한 사용자 정의 래퍼 클래스를 Java에서도 만들 수 있습니다. 필요한 데이터 유형을 사용하여 자체 래퍼 클래스를 만듭니다.
22. 래퍼 클래스가 필요한 이유는 무엇입니까?
래퍼 클래스는 기본 데이터 유형을 캡슐화하는 객체 클래스이며 다음과 같은 이유로 필요합니다.
- 래퍼 클래스는 최종적이고 변경할 수 없습니다.
- valueOf(), parsInt() 등과 같은 메소드를 제공합니다.
- Autoboxing 및 Unboxing 기능을 제공합니다.
23. 인스턴스 변수와 지역 변수를 구별하세요.
인스턴스 변수 | 지역변수 |
|---|---|
메소드 외부에 선언되어 메소드에 의해 직접 호출됩니다. | 메서드 내에서 선언됩니다. |
기본값이 있습니다. | 기본값 없음 |
수업 전반에 걸쳐 사용할 수 있습니다. | 범위는 방법으로 제한됩니다. |
24. Java의 변수와 인스턴스에 할당되는 기본값은 무엇입니까?
Java에서는 인스턴스 변수를 초기화하지 않은 경우 컴파일러는 이를 기본값으로 초기화합니다. 인스턴스와 변수의 기본값은 데이터 유형에 따라 다릅니다. 기본 데이터 유형의 몇 가지 일반적인 유형은 다음과 같습니다.
- 숫자 유형(byte, short, int, long, float 및 double)의 기본값은 0입니다.
- 부울 유형의 기본값은 false입니다.
- 객체 유형(클래스, 인터페이스 및 배열)의 기본값은 null입니다.
- null 문자 u0000은 char 유형의 기본값입니다.
예:
자바 // Java Program to demonstrate use of default values import java.io.*; class GFG { // static values static byte b; static int i; static long l; static short s; static boolean bool; static char c; static String str; static Object object; static float f; static double d; static int[] Arr; public static void main(String[] args) { // byte value System.out.println('byte value' + b); // short value System.out.println('short value' + s); // int value System.out.println('int value' + i); // long value System.out.println('long value' + l); System.out.println('boolean value' + bool); System.out.println('char value' + c); System.out.println('float value' + f); System.out.println('double value' + d); System.out.println('string value' + str); System.out.println('object value' + object); System.out.println('Array value' + Arr); } }> 산출
byte value0 short value0 int value0 long value0 boolean valuefalse char value float value0.0 double value0.0 string valuenull object valuenull Array valuenull>
25. 클래스 변수란 무엇입니까?
Java에서 클래스 변수(정적 변수라고도 함)는 클래스 내에서 선언되지만 메서드, 생성자 또는 블록 외부에서 선언되는 변수입니다. 클래스 변수는 static 키워드로 선언되며 클래스 자체뿐만 아니라 클래스의 모든 인스턴스(객체)에서 공유됩니다. 클래스에서 파생된 개체 수에 관계없이 각 클래스 변수는 한 번만 존재합니다.
예:
자바 // Java program to demonstrate use of Clas Variable class GFG { public static int ctr = 0; public GFG() { ctr++; } public static void main(String[] args) { GFG obj1 = new GFG(); GFG obj2 = new GFG(); GFG obj3 = new GFG(); System.out.println('Number of objects created are ' + GFG.ctr); } }> 산출
Number of objects created are 3>
26. 로컬 변수에 저장되는 기본값은 무엇입니까?
지역 변수에 저장된 기본값은 없습니다. 또한 기본 변수와 객체에는 기본값이 없습니다.
27. 인스턴스 변수와 클래스 변수의 차이점을 설명하세요.
인스턴스 변수: 인스턴스 변수로 알려진 정적 한정자가 없는 클래스 변수는 일반적으로 클래스의 모든 인스턴스에서 공유됩니다. 이러한 변수는 여러 개체 간에 고유한 값을 가질 수 있습니다. 인스턴스 변수의 내용은 클래스의 특정 객체 인스턴스와 관련되어 있기 때문에 한 객체 인스턴스에서 다른 객체 인스턴스와 완전히 독립적입니다.
예:
자바 // Java Program to demonstrate Instance Variable import java.io.*; class GFG { private String name; public void setName(String name) { this.name = name; } public String getName() { return name; } public static void main(String[] args) { GFG obj = new GFG(); obj.setName('John'); System.out.println('Name ' + obj.getName()); } }> 산출
Name John>
클래스 변수: 클래스 변수 변수는 static 키워드를 사용하여 클래스 수준 어디에서나 선언할 수 있습니다. 이러한 변수는 다양한 개체에 적용될 때 하나의 값만 가질 수 있습니다. 이러한 변수는 클래스의 특정 개체에 연결되지 않으므로 모든 클래스 멤버가 공유할 수 있습니다.
예:
자바 // Java Program to demonstrate Class Variable import java.io.*; class GFG { // class variable private static final double PI = 3.14159; private double radius; public GFG(double radius) { this.radius = radius; } public double getArea() { return PI * radius * radius; } public static void main(String[] args) { GFG obj = new GFG(5.0); System.out.println('Area of circle: ' + obj.getArea()); } }> 산출
Area of circle: 78.53975>
28. 정적 변수란 무엇입니까?
static 키워드는 특정 클래스의 동일한 변수나 메서드를 공유하는 데 사용됩니다. 정적 변수는 일단 선언되면 변수의 단일 복사본이 생성되어 클래스 수준의 모든 개체에서 공유되는 변수입니다.
29. System.out, System.err 및 System.in의 차이점은 무엇입니까?
시스템아웃 – 문자를 쓰는 데 사용되거나 명령줄 인터페이스 콘솔/터미널에 쓰려는 데이터를 출력할 수 있다고 말할 수 있는 PrintStream입니다.
예:
자바 // Java Program to implement // System.out import java.io.*; // Driver Class class GFG { // Main Function public static void main(String[] args) { // Use of System.out System.out.println(''); } }>
시스템 오류 – 오류 메시지를 표시하는 데 사용됩니다.
예:
자바 // Java program to demonstrate // System.err import java.io.*; // Driver Class class GFG { // Main function public static void main(String[] args) { // Printing error System.err.println( 'This is how we throw error with System.err'); } }> 산출:
This is how we throw error with System.err>
System.err에는 많은 유사점이 있지만 둘 다 상당한 차이점도 있으므로 확인해 보겠습니다.
| 시스템아웃 | 시스템.err |
|---|---|
시스템 외부의 표준으로 인쇄됩니다. | 표준 오류로 인쇄됩니다. |
주로 콘솔에 결과를 표시하는 데 사용됩니다. | 주로 오류 텍스트를 출력하는 데 사용됩니다. |
기본(검은색) 색상으로 콘솔에 출력됩니다. | 또한 콘솔에 출력을 제공하지만 대부분의 IDE는 구별을 위해 빨간색을 제공합니다. |
시스템인 – 터미널 창에서 입력을 읽는 데 사용되는 InputStream입니다. System.in을 직접 사용할 수 없으므로 system.in으로 입력을 받기 위해 Scanner 클래스를 사용합니다.
예:
자바 // Java Program to demonstrate // System.in import java.util.*; // Driver Class class Main { // Main Function public static void main(String[] args) { // Scanner class with System.in Scanner sc = new Scanner(System.in); // Taking input from the user int x = sc.nextInt(); int y = sc.nextInt(); // Printing the output System.out.printf('Addition: %d', x + y); } }> 산출:
3 4 Addition: 7>
30. IO 스트림으로 무엇을 이해합니까?

Java는 사용자가 모든 입출력 작업을 수행하는 데 도움이 되는 I/O 패키지와 함께 다양한 스트림을 제공합니다. 이러한 스트림은 I/O 작업을 완전히 실행하기 위해 모든 유형의 객체, 데이터 유형, 문자, 파일 등을 지원합니다.
31. Reader/Writer 클래스 계층 구조와 InputStream/OutputStream 클래스 계층 구조의 차이점은 무엇입니까?
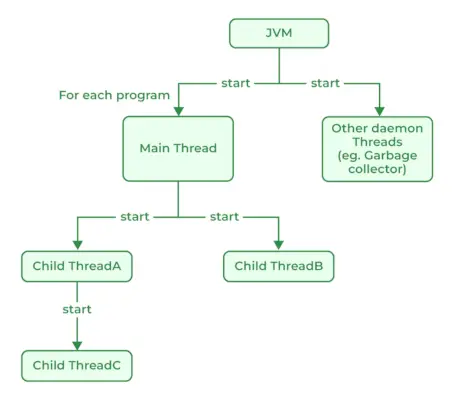
이들 사이의 주요 차이점은 바이트 스트림 데이터가 입력/출력 스트림 클래스에 의해 읽고 쓰여진다는 것입니다. 문자는 Reader 및 Writer 클래스에 의해 처리됩니다. 문자 배열을 매개 변수로 허용하는 판독기/기록기 클래스와 달리 입력/출력 스트림 클래스 메서드는 바이트 배열을 허용합니다. 입력/출력 스트림과 비교하여 Reader/Writer 클래스는 더 효율적이고 모든 유니코드 문자를 처리하며 내부화에 유용합니다. 그렇게 하지 않는 한 그림과 같은 이진 데이터 대신 판독기/작성기 클래스를 사용하십시오.
예:
자바 // Java Program to demonstrate Reading Writing Binary Data // with InputStream/OutputStream import java.io.*; class GFG { public static void main(String[] args) { try { // Writing binary data to a file using OutputStream byte[] data = {(byte) 0xe0, 0x4f, (byte) 0xd0, 0x20, (byte) 0xea}; OutputStream os = new FileOutputStream('data.bin'); os.write(data); os.close(); // Reading binary data from a file using InputStream InputStream is = new FileInputStream('data.bin'); byte[] newData = new byte[5]; is.read(newData); is.close(); // Printing the read data for (byte b : newData) { System.out.println(b); } } catch (IOException e) { e.printStackTrace(); } } }> 산출
-32 79 -48 32 -22>
32. 모든 스트림에서 가장 많은 클래스는 무엇입니까?
모든 스트림 클래스는 ByteStream 클래스와 CharacterStream 클래스라는 두 가지 유형의 클래스로 나눌 수 있습니다. ByteStream 클래스는 다시 InputStream 클래스와 OutputStream 클래스로 나뉩니다. CharacterStream 클래스도 Reader 클래스와 Writer 클래스로 구분됩니다. 모든 InputStream 클래스에 대한 SuperMost 클래스는 java.io.InputStream이고 모든 출력 스트림 클래스에 대한 SuperMost 클래스는 java.io.OutPutStream입니다. 마찬가지로 모든 리더 클래스의 최상위 클래스는 java.io.Reader이고, 모든 라이터 클래스의 경우 java.io.Writer입니다.
33. FileInputStream과 FileOutputStream은 무엇입니까?
데이터를 읽고 쓰기 위해 Java는 I/O 스트림을 제공합니다. Stream은 파일, I/O 장치, 다른 프로그램 등이 될 수 있는 입력 소스 또는 출력 대상을 나타냅니다. 파일입력스트림 Java에서는 파일의 데이터를 바이트 스트림으로 읽는 데 사용됩니다. 주로 이미지, 오디오 파일 또는 직렬화된 개체와 같은 이진 데이터를 읽는 데 사용됩니다.
컴퓨터가 발명된 해는 언제입니까?
예:
File file = new File('path_of_the_file'); FileInputStream inputStream = new FileInputStream(file);>자바에서는 파일출력스트림 함수는 주어진 파일이나 파일 설명자에 바이트 단위로 데이터를 쓰는 데 사용됩니다. 일반적으로 그림과 같은 원시 바이트 데이터는 FileOutputStream을 사용하여 파일에 기록됩니다.
예:
File file = new File('path_of_the_file'); FileOutputStream outputStream = new FileOutputStream(file);>34. BufferedInputStream 및 BufferedOutputStream 클래스를 사용하는 목적은 무엇입니까?
파일이나 스트림으로 작업할 때 프로그램의 입출력 성능을 높이려면 BufferedInputStream 및 BufferedOutputStream 클래스를 사용해야 합니다. 두 클래스 모두 버퍼링 기능을 제공합니다. 즉, 파일에 쓰거나 스트림에서 데이터를 읽기 전에 데이터가 버퍼에 저장된다는 의미입니다. 또한 OS가 네트워크 또는 디스크와 상호 작용하는 데 필요한 횟수도 줄어듭니다. 버퍼링을 사용하면 프로그램이 작은 덩어리로 데이터를 쓰는 대신 대량의 데이터를 쓸 수 있습니다. 이는 또한 네트워크나 디스크에 액세스하는 오버헤드를 줄여줍니다.
BufferedInputStream(InputStream inp); // used to create the bufferinput stream and save the arguments.>
BufferedOutputStream(OutputStream output); // used to create a new buffer with the default size.>
35. FilterStream이란 무엇입니까?
스트림 필터 또는 필터 스트림 주어진 조건과 일치하는 이 스트림의 요소로 구성된 스트림을 반환합니다. filter() 작업 중에는 실제로 필터링을 수행하지 않지만 대신 탐색할 때 주어진 조건과 일치하는 초기 스트림의 요소를 포함하는 새 스트림을 생성합니다.
예:
FileInputStream fis =new FileInoutStream('file_path'); FilterInputStream = new BufferedInputStream(fis);>
36. I/O 필터란 무엇입니까?
입력 출력 필터라고도 정의되는 I/O 필터는 하나의 스트림에서 읽고 입력 및 출력 소스에 데이터를 쓰는 개체입니다. 이 필터를 사용하기 위해 java.io 패키지를 사용했습니다.
37. 콘솔에서 입력을 받을 수 있는 방법은 몇 가지입니까?
아래에 언급된 Java 콘솔에서 입력을 받는 두 가지 방법이 있습니다.
- 명령줄 인수 사용
- 버퍼링된 리더 클래스 사용
- 콘솔 클래스 사용
- 스캐너 클래스 사용
각 방법의 사용을 보여주는 프로그램은 다음과 같습니다.
예:
자바 // Java Program to implement input // using Command line argument import java.io.*; class GFG { public static void main(String[] args) { // check if length of args array is // greater than 0 if (args.length > 0) { System.out.println( 'The command line arguments are:'); // iterating the args array and printing // the command line arguments for (String val : args) System.out.println(val); } else System.out.println('No command line ' + 'arguments found.'); } } // Use below commands to run the code // javac GFG.java // java Main techcodeview.com> 자바 // Java Program to implement // Buffer Reader Class import java.io.*; class GFG { public static void main(String[] args) throws IOException { // Enter data using BufferReader BufferedReader read = new BufferedReader( new InputStreamReader(System.in)); // Reading data using readLine String x = read.readLine(); // Printing the read line System.out.println(x); } }> 자바 // Java program to implement input // Using Console Class public class GfG { public static void main(String[] args) { // Using Console to input data from user String x = System.console().readLine(); System.out.println('You entered string ' + x); } }> 자바 // Java program to demonstrate // working of Scanner in Java import java.util.Scanner; class GfG { public static void main(String args[]) { // Using Scanner for Getting Input from User Scanner in = new Scanner(System.in); String str = in.nextLine(); System.out.println('You entered string ' + str); } }> 산출:
techcodeview.com>
38. print, println, printf 사용의 차이점.
print, println 및 printf는 모두 요소를 인쇄하는 데 사용되지만 print는 모든 요소를 인쇄하고 커서는 같은 줄에 유지됩니다. println은 커서를 다음 줄로 이동시킵니다. 그리고 printf를 사용하면 형식 식별자도 사용할 수 있습니다.
39. 연산자란 무엇입니까?
연산자는 변수와 값에 대해 일부 연산을 수행하는 데 사용되는 특수한 유형의 기호입니다.
40. Java에서는 몇 가지 유형의 연산자를 사용할 수 있습니까?
Java의 모든 유형의 연산자는 아래에 언급되어 있습니다.
후위 연산자는 Java 연산자 우선 순위에 따라 가장 높은 우선 순위로 간주됩니다.
41.>>와>>> 연산자의 차이점을 설명하십시오.
>> 및>>>와 같은 연산자는 동일한 것처럼 보이지만 약간 다르게 작동합니다.>> 연산자는 부호 비트를 이동하고>>> 연산자는 0으로 채워진 비트를 이동하는 데 사용됩니다.
예:
자바 // Java Program to demostrate //>> 및>>> 연산자 import java.io.*; // 드라이버 클래스 GFG { public static void main(String[] args) { int a = -16, b = 1; //>> System.out.println(a >> b); 사용 a = -17; b = 1; //>>> System.out.println(a >>> b); 사용 } }> 산출
-8 2147483639>
42. 어떤 Java 연산자가 올바른 연관입니까?
= 연산자인 우결합 연산자는 단 하나뿐입니다.
43. 도트 연산자란 무엇입니까?
Java의 Dot 연산자는 클래스 객체의 인스턴스 변수와 메서드에 액세스하는 데 사용됩니다. 또한 패키지의 클래스 및 하위 패키지에 액세스하는 데에도 사용됩니다.
44. 공변 반환 유형이란 무엇입니까?
공변 반환 유형은 반환 유형이 하위 클래스와 동일한 방향으로 달라질 수 있음을 지정합니다. 자식 클래스의 재정의 메서드에 대해 서로 다른 반환 유형을 가질 수 있지만 자식의 반환 유형은 부모 반환 유형의 하위 유형이어야 하며 그로 인해 재정의 메서드는 반환 유형에 따라 변형이 됩니다.
우리는 다음과 같은 이유로 공변 반환 유형을 사용합니다.
- 클래스 계층 구조에 존재하는 혼란스러운 유형 캐스트를 방지하고 코드를 읽기 쉽고, 사용 가능하고, 유지 관리 가능하게 만듭니다.
- 메서드를 재정의할 때 더 구체적인 반환 유형을 가질 수 있는 자유를 제공합니다.
- 반품 시 런타임 ClassCastException을 방지하는 데 도움이 됩니다.
45. 임시 키워드는 무엇입니까?
Transient 키워드는 직렬화 시 특정 변수의 값을 파일에 저장하지 않으려는 경우 사용됩니다. JVM은 임시 키워드를 발견하면 변수의 원래 값을 무시하고 해당 변수 데이터 유형의 기본값을 저장합니다.
46. sleep() 메소드와 wait() 메소드의 차이점은 무엇입니까?
잠() | 기다리다() |
|---|---|
sleep() 메소드는 스레드 클래스에 속합니다. | Wait() 메소드는 객체 클래스에 속합니다. |
Sleep은 현재 스레드가 보유하고 있는 잠금을 해제하지 않습니다. | wait()는 다른 스레드가 잠금을 획득할 수 있도록 잠금을 해제합니다. |
이 방법은 정적 방법입니다. | 이 방법은 정적 방법이 아닙니다. |
| Sleep()은 InterruptedException을 발생시키지 않습니다. | 대기하는 동안 스레드가 중단되면 InterruptedException이 표시됩니다. |
특정 시간 동안 스레드를 지연시키는 데 주로 사용됩니다. | 주로 다른 스레드에서 알림을 받을 때까지 스레드를 일시 중지하는 데 사용됩니다. |
Sleep()에는 두 가지 오버로드된 메서드가 있습니다.
| Wait()에는 세 가지 오버로드된 메서드가 있습니다.
|
47. String과 StringBuffer의 차이점은 무엇입니까?
끈 | 문자열 버퍼 |
|---|---|
| 일련의 문자를 저장합니다. | 문자열 작업을 위한 기능을 제공합니다. |
| 그것은 불변이다. | 변경 가능합니다(수정 가능하며 다른 문자열 작업을 수행할 수 있음). |
| 문자열에는 스레드 작업이 없습니다. | 스레드로부터 안전합니다(두 개의 스레드가 StringBuffer의 메서드를 동시에 호출할 수 없음). |
48. StringBuffer와 StringBuilder의 차이점은 무엇입니까?
문자열 버퍼 | 스트링빌더 |
|---|---|
| StringBuffer는 문자열 작업을 위한 기능을 제공합니다. | StringBuilder는 변경 가능한 문자열을 작성하는 데 사용되는 클래스입니다. |
| 스레드로부터 안전합니다(두 개의 스레드가 StringBuffer의 메서드를 동시에 호출할 수 없음). | 스레드로부터 안전하지 않습니다(두 스레드가 동시에 메서드를 호출할 수 있음). |
| 동기화되기 때문에 비교적 느립니다. | 비동기화되어 구현이 더 빠릅니다. |
49. 데이터에 업데이트가 많이 필요한 경우 문자열 버퍼와 문자열 버퍼 중 어느 것을 선호해야 합니까?
StringBuilder가 StringBuffer보다 빠르기 때문에 StringBuffer보다 문자열이 선호되지만, 더 많은 스레드 안전성을 제공하므로 StringBuffer 객체가 선호됩니다.
50. StringBuffer를 가변이라고 부르는 이유는 무엇입니까?
Java의 StringBuffer 클래스는 변경 가능한 문자열을 나타내는 데 사용됩니다. 새로운 객체를 지속적으로 생성하지 않고도 문자열의 내용을 변경할 수 있도록 하여 불변 String 클래스에 대한 대안을 제공합니다. 변경 가능한(수정 가능한) 문자열은 StringBuffer 클래스의 도움으로 생성됩니다. Java의 StringBuffer 클래스는 변경 가능하다는 점을 제외하면 String 클래스와 동일합니다.
예:
자바 // Java Program to demonstrate use of stringbuffer public class StringBufferExample { public static void main(String[] args) { StringBuffer s = new StringBuffer(); s.append('Geeks'); s.append('for'); s.append('Geeks'); String message = s.toString(); System.out.println(message); } }> 산출
techcodeview.com>
51. new()를 사용하여 문자열을 생성하는 것과 리터럴을 생성하는 것은 어떻게 다릅니까?
new()를 사용하는 문자열은 문자열을 선언하면 스택 메모리 내부에 요소를 저장하는 반면, new()를 사용하여 선언하면 힙 메모리에 동적 메모리를 할당한다는 점에서 리터럴과 다릅니다. 동일한 콘텐츠 객체가 존재하더라도 객체는 힙 메모리에 생성됩니다.
통사론:
String x = new String('ABC');>
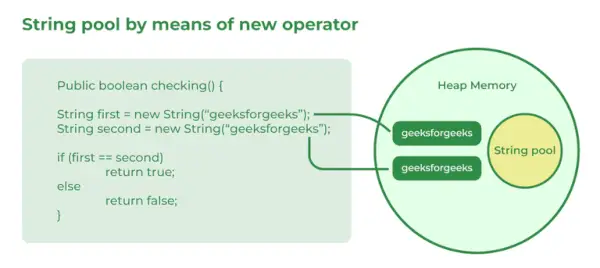
52. Java의 배열이란 무엇입니까?
Java의 배열은 동일한 유형의 고정 크기 시퀀스 요소를 저장하는 데 사용되는 데이터 구조입니다. 배열의 요소는 0부터 시작하여 길이가 마이너스 1까지 올라가는 인덱스로 액세스할 수 있습니다. Java에서 배열 선언은 대괄호를 사용하여 수행되며 선언 중에 크기도 지정됩니다.
통사론:
int[] Arr = new int[5];>
53. Java에서는 어떤 메모리 배열이 생성됩니까?
Java의 배열은 힙 메모리에 생성됩니다. new 키워드를 사용하여 배열이 생성되면 배열 요소를 저장하기 위해 힙에 메모리가 할당됩니다. Java에서 힙 메모리는 JVM(Java Virtual Machine)에 의해 관리되며 Java 프로그램의 모든 스레드 간에 공유됩니다. 프로그램에서 더 이상 사용하지 않는 메모리는 JVM에서 가비지 수집기를 사용하여 메모리를 회수합니다. Java의 배열은 동적으로 생성됩니다. 즉, 배열의 크기는 프로그램 실행 중에 결정됩니다. 배열의 크기는 배열 선언 시 지정되며 배열이 생성된 후에는 변경할 수 없습니다.
54. 배열의 유형은 무엇입니까?
배열에는 기본 배열과 참조 배열의 두 가지 유형이 있습니다.
- 1차원 배열: 1차원 배열(예: 정수 배열 또는 문자열 배열)만 있는 배열을 1차원 배열이라고 합니다.
통사론:
data_type[] Array_Name = new data_type[ArraySize];>
- 다차원 배열: 2차원 또는 3차원 배열과 같이 2차원 이상을 갖는 배열입니다.
55. Java 배열 인덱스는 왜 0으로 시작합니까?
배열의 인덱스는 배열의 시작점으로부터의 거리를 나타냅니다. 따라서 첫 번째 요소의 거리가 0이므로 시작 인덱스는 0입니다.
통사론:
[Base Address + (index * no_of_bytes)]>
56. int array[]와 int[] 배열의 차이점은 무엇입니까?
int array[]와 int[] array는 모두 Java에서 정수 배열을 선언하는 데 사용됩니다. 이들 사이의 유일한 차이점은 구문에 기능적 차이가 없다는 것입니다.
int arr[] is a C-Style syntax to declare an Array.>
int[] arr is a Java-Style syntax to declare an Array.>
그러나 일반적으로 배열을 선언하려면 Java 스타일 구문을 사용하는 것이 좋습니다. 읽고 이해하기 쉽기 때문에 다른 Java 언어 구성과도 더 일관성이 있습니다.
57. Java에서 배열을 복사하는 방법은 무엇입니까?
Java에는 요구 사항에 따라 배열을 복사하는 여러 가지 방법이 있습니다.
- Java의 clone() 메소드: Java에서 이 메소드는 주어진 배열의 얕은 복사본을 만드는 데 사용됩니다. 즉, 새 배열이 원본 배열과 동일한 메모리를 공유한다는 의미입니다.
int[] Arr = { 1, 2, 3, 5, 0}; int[] tempArr = Arr.clone();>- arraycopy() 메서드: 배열의 전체 복사본을 만들려면 원본 배열과 동일한 값을 가진 새 배열을 만드는 이 메서드를 사용할 수 있습니다.
int[] Arr = {1, 2, 7, 9, 8}; int[] tempArr = new int[Arr.length]; System.arraycopy(Arr, 0, tempArr, 0, Arr.length);>- copyOf() 메서드: 이 메서드는 특정 길이의 새 배열을 만들고 원본 배열의 내용을 새 배열에 복사하는 데 사용됩니다.
int[] Arr = {1, 2, 4, 8}; int[] tempArr = Arrays.copyOf(Arr, Arr.length);>- copyOfRange() 메서드: 이 메소드는 Java의 copyOf() 메소드와 매우 유사하지만 이 메소드를 사용하면 원본 배열에서 복사할 요소의 범위를 지정할 수도 있습니다.
int[] Arr = {1, 2, 4, 8}; int[] temArr = Arrays.copyOfRange(Arr, 0, Arr.length);>58. 들쭉날쭉한 배열을 통해 무엇을 이해합니까?
Java의 들쭉날쭉한 배열은 배열의 각 행이 서로 다른 길이를 가질 수 있는 2차원 배열입니다. 2차원 배열의 모든 행은 길이가 동일하지만 들쭉날쭉한 배열을 사용하면 각 행의 크기를 더 유연하게 조정할 수 있습니다. 이 기능은 데이터 길이가 다양하거나 메모리 사용량을 최적화해야 하는 경우에 매우 유용합니다.
통사론:
int[][] Arr = new int[][] { {1, 2, 8}, {7, 5}, {6, 7, 2, 6} };>59. 배열을 휘발성으로 만드는 것이 가능합니까?
Java에서는 휘발성을 만드는 것이 불가능합니다. Java의 휘발성 키워드는 개별 변수에만 적용할 수 있고 배열이나 컬렉션에는 적용할 수 없습니다. 변수의 값은 스레드의 로컬 메모리에 캐시되지 않고 휘발성으로 정의된 경우 항상 주 메모리에서 읽고 쓰여집니다. 이렇게 하면 변수에 액세스하는 모든 스레드가 해당 변수에 대한 변경 사항을 볼 수 있는지 확인하는 것이 더 쉬워집니다.
60. 어레이의 장점과 단점은 무엇입니까?
배열의 장점은 다음과 같습니다.
- 배열을 사용하면 컬렉션의 모든 요소에 직접적이고 효과적으로 액세스할 수 있습니다. 배열의 요소는 O(1) 연산을 사용하여 액세스할 수 있습니다. 즉, 그렇게 하는 데 필요한 시간은 일정하고 배열의 크기와 무관합니다.
- 배열을 사용하면 데이터를 메모리에 효과적으로 저장할 수 있습니다. 배열의 크기는 해당 요소가 연속적인 메모리 영역에 저장되므로 컴파일 타임에 알려집니다.
- 데이터가 인접한 메모리 영역에 저장된다는 사실 때문에 배열은 빠른 데이터 검색을 제공합니다.
- 배열은 구현하고 이해하기 쉬우므로 컴퓨터 프로그래밍을 배우는 초보자에게 이상적인 선택입니다.
배열의 단점은 다음과 같습니다.
- 배열은 그 순간 선택되는 미리 결정된 크기로 생성됩니다. 즉, 어레이의 크기를 확장해야 하는 경우 새 어레이를 만들어야 하고, 이전 어레이에서 새 어레이로 데이터를 복사해야 하므로 많은 시간과 메모리가 소요될 수 있습니다.
- 어레이가 완전히 채워지지 않은 경우 어레이의 메모리 공간에 사용되지 않은 메모리 공간이 있을 수 있습니다. 기억력이 좋지 않으면 문제가 될 수 있습니다.
- 연결된 목록 및 트리와 같은 다른 데이터 구조와 비교할 때 배열은 고정된 크기와 정교한 데이터 유형에 대한 제한된 지원으로 인해 엄격할 수 있습니다.
- 배열의 요소는 모두 동일한 데이터 유형이어야 하기 때문에 객체 및 구조와 같은 복잡한 데이터 유형을 지원하지 않습니다.
61. 객체지향 패러다임이란 무엇입니까?
패러다임은 말 그대로 패턴이나 방법을 뜻한다. 프로그래밍 패러다임은 명령형, 논리형, 기능형, 객체지향의 네 가지 유형의 프로그램을 해결하는 방법입니다. 객체가 메소드가 적용되는 기본 엔터티로 사용되고 캡슐화 또는 상속 기능이 수행되는 경우 이를 객체 지향 패러다임이라고 합니다.
62. Java에서 OOP의 주요 개념은 무엇입니까?
Java에서 OOP의 주요 개념은 다음과 같습니다.
- 계승
- 다형성
- 추출
- 캡슐화
63. 객체 지향 프로그래밍 언어와 객체 기반 프로그래밍 언어의 차이점은 무엇입니까?
객체지향 프로그래밍 언어 | 객체 기반 프로그래밍 언어 |
|---|---|
| 객체 지향 프로그래밍 언어는 상속, 다형성, 추상화 등과 같은 더 큰 개념을 다룹니다. | 객체 기반 프로그래밍의 범위는 객체 사용과 캡슐화로 제한됩니다. |
| 모든 내장 개체를 지원합니다. | 모든 내장 개체를 지원하지는 않습니다. |
| 예: Java, C# 등 | 예: Java 스크립트, 시각적 기본 등 |
64. 'new' 연산자는 Java의 'newInstance()' 연산자와 어떻게 다릅니까?
new 연산자는 객체를 생성하는 데 사용되지만 런타임에 생성할 객체 유형을 결정하려는 경우 new 연산자를 사용할 수 있는 방법이 없습니다. 이 경우에는 다음을 사용해야 합니다. newInstance() 메서드 .
65. Java의 클래스란 무엇입니까?
Java에서 클래스는 유사한 특성과 속성을 공유하는 객체의 모음입니다. 클래스는 객체가 생성되는 청사진이나 템플릿을 나타냅니다. 클래스는 실제 엔터티가 아니지만 실제 엔터티인 개체를 만드는 데 도움이 됩니다.
66. 정적(클래스) 메소드와 인스턴스 메소드의 차이점은 무엇입니까?
정적(클래스) 메서드 | 인스턴스 방법 |
|---|---|
정적 메서드는 개체가 아닌 클래스와 연결됩니다. | 인스턴스 메서드는 클래스가 아닌 개체와 연결됩니다. |
클래스의 인스턴스를 만들지 않고 클래스 이름만 사용하여 정적 메서드를 호출할 수 있습니다. | 인스턴스 메소드는 객체 참조를 사용하여 클래스의 특정 인스턴스에서 호출될 수 있습니다. |
정적 메소드에는 액세스할 수 없습니다. 이것 예어 . | 인스턴스 메소드는 다음에 액세스할 수 있습니다. 이것 예어 . |
이 메서드는 클래스의 정적 멤버에만 액세스할 수 있습니다. | 이 메서드는 클래스의 정적 메서드와 비정적 메서드 모두에 액세스할 수 있습니다. |
67. Java에서 이 키워드는 무엇입니까?
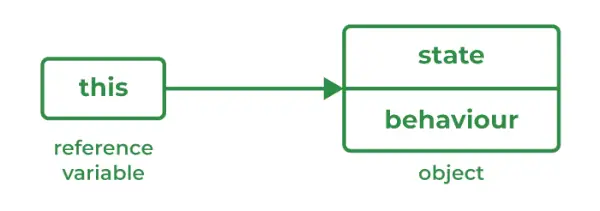
'this'는 현재 객체를 참조하는 변수를 참조하는 데 사용되는 키워드입니다.
: 자바에서
68. 간략한 액세스 지정자와 액세스 지정자 유형은 무엇입니까?
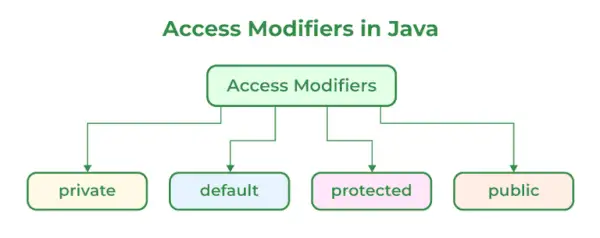
Java의 액세스 지정자는 클래스, 생성자, 변수, 메서드 또는 데이터 멤버의 범위를 제한하는 데 도움이 됩니다. Java에는 아래에 언급된 네 가지 유형의 액세스 지정자가 있습니다.
- 공공의
- 사적인
- 보호됨
- 기본
69. 인스턴스 변수로 정의된 객체 참조의 초기 값은 무엇입니까?
인스턴스 변수로 정의된 객체 참조의 초기값은 NULL 값이다.
70. 물건이란 무엇입니까?
객체는 이와 관련된 특정 속성과 메서드를 가진 실제 엔터티입니다. 객체는 클래스의 인스턴스로도 정의됩니다. new 키워드를 사용하여 객체를 선언할 수 있습니다.
71. Java로 객체를 생성하는 다양한 방법은 무엇입니까?
Java에서 객체를 생성하는 방법은 다음과 같습니다.
- 새 키워드 사용
- 새 인스턴스 사용
- clone() 메소드 사용
- 역직렬화 사용
- 생성자 클래스의 newInstance() 메서드 사용
Java에서 객체를 생성하는 방법에 대한 자세한 내용은 다음을 참조하세요. 이 기사 .
72. 객체 복제의 장점과 단점은 무엇입니까?
아래에 언급된 것처럼 객체 복제를 사용하면 많은 장점과 단점이 있습니다.
장점:
- Java에서 '=' 할당 연산자는 단순히 참조 변수의 복사본을 생성하므로 복제에 사용할 수 없습니다. 이러한 불일치를 극복하기 위해 Object 클래스의 clone() 메서드를 할당 연산자 대신 사용할 수 있습니다.
- clone() 메소드는 Object 클래스의 보호된 메소드입니다. 이는 Employee 클래스만이 Employee 객체를 복제할 수 있음을 의미합니다. 이는 Employee 이외의 클래스는 Employee 클래스의 속성을 모르기 때문에 Employee 객체를 복제할 수 없음을 의미합니다.
- 반복이 줄어들수록 코드 크기는 줄어듭니다.
- 복제(프로토타입 패턴과 유사)를 허용하여 각 필드를 수동으로 초기화하면 객체가 복잡한 경우 큰 코드가 생성되며 복제를 사용하면 속도가 더 빨라집니다.
단점:
- Object.clone() 메서드는 보호되므로 자체 clone()을 제공하고 여기에서 간접적으로 Object.clone()을 호출해야 합니다.
- 메소드가 없으면 객체에서 clone()을 수행할 수 있도록 JVM 정보를 제공해야 하므로 Cloneable 인터페이스를 제공해야 합니다. 그렇지 않은 경우 복제할 수 없습니다. clone은 필드의 얕은 복사본을 수행합니다. 문제가 될 수 있는 복제 메소드에서 super.clone()을 반환하면 됩니다.
73. 이것을 현재 클래스 객체 자체 대신 메소드에 전달하면 어떤 이점이 있습니까?
이를 현재 클래스 객체 자체 대신 메소드에 전달하면 다음과 같은 몇 가지 이점이 있습니다.
- 이는 최종 변수이므로 새 값에 할당할 수 없지만 현재 클래스 개체는 최종이 아닐 수 있으며 변경될 수 있습니다.
- 이는 동기화된 블록에서 사용될 수 있습니다.
74. 생성자는 무엇입니까?
생성자는 객체를 초기화하는 데 사용되는 특별한 방법입니다. 생성자는 객체가 생성될 때 호출됩니다. 생성자의 이름은 클래스의 이름과 동일합니다.
예:
// Class Created class XYZ{ private int val; // Constructor XYZ(){ val=0; } };>75. 클래스에 생성자를 제공하지 않으면 어떻게 되나요?
Java의 클래스에 생성자를 제공하지 않으면 컴파일러는 인수와 연산이 없는 기본 생성자인 기본 생성자를 자동으로 생성합니다.
76. Java에서는 몇 가지 유형의 생성자가 사용됩니까?
Java에는 아래와 같이 두 가지 유형의 생성자가 있습니다.
- 기본 생성자
- 매개변수화된 생성자
기본 생성자(Default Constructor): 어떠한 매개변수 값도 허용하지 않는 타입입니다. 객체 속성의 초기값을 설정하는 데 사용됩니다.
class_Name(); // Default constructor called>
매개변수화된 생성자(Parameterized Constructor): 매개변수를 인수로 받아들이는 생성자 유형입니다. 이는 객체 초기화 중에 인스턴스 변수에 값을 할당하는 데 사용됩니다.
class_Name(parameter1, parameter2......); // All the values passed as parameter will be // allocated accordingly>
77. 기본 생성자의 목적은 무엇입니까?
생성자는 클래스의 인스턴스를 생성하는 데 도움을 주거나 클래스의 객체를 생성한다고 할 수 있습니다. 객체를 초기화하는 동안 생성자가 호출됩니다. 기본 생성자는 매개 변수를 허용하지 않는 생성자 유형이므로 개체의 속성에 할당된 값은 기본값으로 간주됩니다.
78. Java의 복사 생성자에 대해 무엇을 이해합니까?
복사 생성자는 두 개체의 속성이 동일해 보이기 때문에 다른 개체를 매개 변수로 전달하는 생성자 유형입니다. 따라서 생성자가 개체의 복사본을 만드는 것처럼 보입니다.
79. 개인 생성자를 어디서, 어떻게 사용할 수 있나요?
서브클래싱을 피하기 위해 다른 클래스가 객체를 인스턴스화하는 것을 원하지 않는 경우 비공개 생성자가 사용됩니다. 예제에서는 개인 생성자를 사용하여 구현된 것을 볼 수 있습니다.
예:
자바 // Java program to demonstrate implementation of Singleton // pattern using private constructors. import java.io.*; class GFG { static GFG instance = null; public int x = 10; // private constructor can't be accessed outside the // class private GFG() {} // Factory method to provide the users with instances static public GFG getInstance() { if (instance == null) instance = new GFG(); return instance; } } // Driver Class class Main { public static void main(String args[]) { GFG a = GFG.getInstance(); GFG b = GFG.getInstance(); a.x = a.x + 10; System.out.println('Value of a.x = ' + a.x); System.out.println('Value of b.x = ' + b.x); } }> 산출
Value of a.x = 20 Value of b.x = 20>
80. 생성자와 메소드의 차이점은 무엇입니까?
Java 생성자는 객체를 초기화하는 데 사용됩니다. 생성하는 동안 생성자는 개체 간의 몇 가지 기본 차이점을 제외하고 개체의 특성을 설정하기 위해 호출됩니다.
- 생성자는 객체가 생성될 때만 호출되지만 다른 메서드는 객체 수명 동안 여러 번 호출될 수 있습니다.
- 생성자는 아무 것도 반환하지 않지만 다른 메서드는 무엇이든 반환할 수 있습니다.
- 생성자는 초기 상태를 설정하는 데 사용되지만 메서드는 특정 작업을 수행하는 데 사용됩니다.
81. 인터페이스란 무엇입니까?
Java의 인터페이스는 연결된 클래스 집합에 대한 계약 또는 합의를 정의하는 정적 최종 변수 및 추상 메서드의 모음입니다. 특정 메소드 세트를 구현하려면 인터페이스를 구현하는 모든 클래스가 필요합니다. 클래스가 표시해야 하는 동작을 지정하지만 구현 방법에 대한 구체적인 내용은 지정하지 않습니다.
통사론:
interface { // constant fields // methds that are abstract by default }>예:
자바 // Java Program to demonstrate Interface import java.io.*; interface Shape { double getArea(); double getPerimeter(); } class Circle implements Shape { private double radius; public Circle(double radius) { this.radius = radius; } public double getArea() { return Math.PI * radius * radius; } public double getPerimeter() { return 2 * Math.PI * radius; } } class GFG { public static void main(String[] args) { Circle circle = new Circle(5.0); System.out.println('Area of circle is ' + circle.getArea()); System.out.println('Perimeter of circle is' + circle.getPerimeter()); } }> 산출
Area of circle is 78.53981633974483 Perimeter of circle is31.41592653589793>
82. 인터페이스의 몇 가지 기능을 제공하십시오.
Java 프로그래밍 언어의 인터페이스는 클래스의 동작을 지정하는 데 사용되는 추상 유형으로 정의됩니다. Java의 인터페이스는 동작의 청사진입니다. Java 인터페이스에는 정적 상수와 추상 메소드가 포함되어 있습니다.
인터페이스의 기능은 다음과 같습니다.
- 인터페이스는 전체 추상화를 달성하는 데 도움이 될 수 있습니다.
- Java에서 다중 상속을 사용할 수 있습니다.
- 하나의 클래스가 하나의 클래스만 확장할 수 있는 경우에도 모든 클래스는 여러 인터페이스를 구현할 수 있습니다.
- 또한 느슨한 결합을 달성하는 데에도 사용됩니다.
83. 마커 인터페이스란 무엇입니까?
인터페이스는 빈 인터페이스(필드나 메소드 없음)로 인식되며 이를 마커 인터페이스라고 합니다. 마커 인터페이스의 예로는 직렬화 가능, 복제 가능 및 원격 인터페이스가 있습니다.
84. 추상 클래스와 인터페이스의 차이점은 무엇입니까?
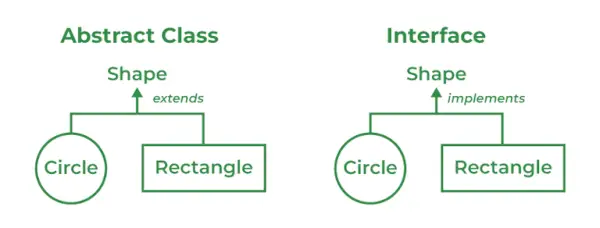
추상 클래스 | 인터페이스 클래스 |
|---|---|
추상 메소드와 비추상 메소드 모두 추상 클래스에서 찾을 수 있습니다. | 인터페이스에는 추상 메서드만 포함되어 있습니다. |
추상 클래스는 Final 메소드를 지원합니다. | 인터페이스 클래스는 Final 메소드를 지원하지 않습니다. |
Abstract 클래스에서는 다중 상속이 지원되지 않습니다. | 인터페이스 클래스는 다중 상속을 지원합니다. |
Abstract 키워드는 Abstract 클래스를 선언하는 데 사용됩니다. | 인터페이스 키워드는 인터페이스 클래스를 선언하는 데 사용됩니다. |
| 연장하다 키워드는 추상 클래스를 확장하는 데 사용됩니다. | 구현하다 키워드는 인터페이스를 구현하는 데 사용됩니다. |
추상 클래스에는 protected, private 등과 같은 멤버가 있습니다. | 모든 클래스 멤버는 기본적으로 공개됩니다. |
85. 데이터 캡슐화란 무엇을 의미합니까?
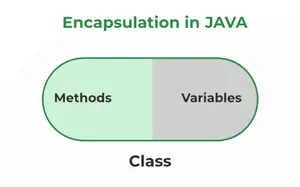
데이터 캡슐화는 인터페이스가 함께 바인딩되는 클래스의 OOPS 속성 및 특성에 대한 개념입니다. 기본적으로 단일 단위 내에서 데이터와 해당 데이터에 대해 작동하는 방법을 묶습니다. 캡슐화는 클래스의 인스턴스 변수를 비공개로 선언하여 달성됩니다. 즉, 해당 변수는 클래스 내에서만 액세스할 수 있습니다.
86. Java에서 캡슐화의 장점은 무엇입니까?
Java Encapsulation의 장점은 다음과 같습니다.
- 데이터 숨기기: 구현 세부 사항을 숨겨 데이터 구성원의 액세스를 제한하는 방법입니다. 캡슐화는 데이터를 숨기는 방법도 제공합니다. 사용자는 클래스의 내부 구현에 대해 전혀 모릅니다.
- 유연성 향상: 요구 사항에 따라 클래스의 변수를 읽기 전용 또는 쓰기 전용으로 만들 수 있습니다.
- 재사용성: 캡슐화는 재사용성을 향상시키고 새로운 요구 사항에 따라 쉽게 변경할 수 있습니다.
- 코드 테스트가 쉽습니다. 단위 테스트를 위해 코드를 쉽게 테스트할 수 있습니다.
87. 캡슐화의 주요 이점은 무엇입니까?
Java에서 캡슐화의 주요 장점은 외부 수정이나 액세스로부터 객체의 내부 상태를 보호하는 기능입니다. 이는 외부 액세스로부터 클래스의 구현 세부 정보를 숨기고 클래스와 상호 작용하는 데 사용할 수 있는 공용 인터페이스만 노출하는 방법입니다. 주요 이점은 객체의 상태와 동작을 제어 및 관리하는 방법을 제공하는 동시에 수정 및 무단 액세스로부터 객체를 보호하는 것입니다.
예:
자바 // Java Program to demonstrate use of Encapsulation import java.io.*; class Person { private String Name; private int age; public String getName() { return Name; } public void setName(String Name) { this.Name = Name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } // Driver class class GFG { // main function public static void main(String[] args) { Person p = new Person(); p.setName('Rohan'); p.setAge(29); System.out.println('Name is ' + p.getName()); System.out.println('Age is ' + p.getAge()); } }> 산출
Name is Rohan Age is 29>
88. 집계란 무엇을 의미합니까?
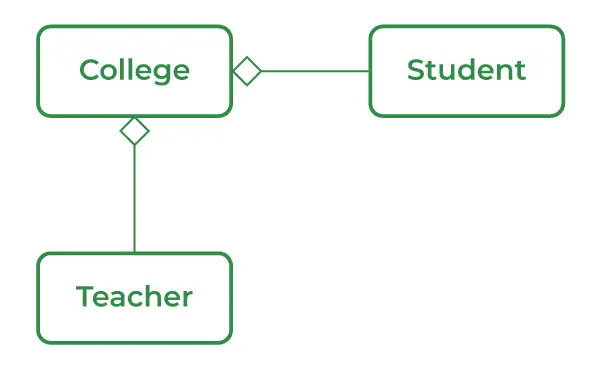
집계는 has-a 관계로 가장 잘 설명되는 두 클래스 간의 관계와 관련된 용어입니다. 이 종류는 협회의 가장 전문화된 버전입니다. 단방향 연관은 단방향 관계를 의미합니다. 여기에는 다른 클래스에 대한 참조가 포함되어 있으며 해당 클래스의 소유권을 갖고 있다고 합니다.
89. OOP Java의 'IS-A' 관계는 무엇입니까?
'IS-A'는 한 클래스가 다른 클래스를 상속하는 OOP Java의 관계 유형입니다.
90. 상속을 정의하십시오.
하위 클래스에 속한 객체가 상위 클래스의 상위 객체의 모든 속성과 동작을 획득하는 것을 상속이라고 합니다. 클래스 내의 클래스를 서브클래스, 후자를 슈퍼클래스라고 합니다. 하위 클래스 또는 하위 클래스는 특정 클래스인 반면, 상위 클래스 또는 상위 클래스는 일반 클래스입니다. 상속은 코드 재사용성을 제공합니다.
91. Java의 다양한 상속 유형은 무엇입니까?
상속은 Child 클래스가 Super 또는 Parent 클래스의 기능을 상속할 수 있는 방법입니다. Java에서 상속은 네 가지 유형이 있습니다.
- 단일 상속: 자식 또는 하위 클래스가 하나의 슈퍼클래스만 확장하는 경우 이를 단일 상속이라고 합니다. 단일 부모 클래스 속성은 자식 클래스에 전달됩니다.
- 다단계 상속: 하위 클래스나 하위 클래스가 다른 하위 클래스를 확장하면 다중 수준 상속이라고 알려진 상속 계층이 생성됩니다. 즉, 한 하위 클래스가 다른 하위 클래스의 상위 클래스가 됩니다.
- 계층적 상속: 여러 하위 클래스가 동일한 상위 클래스에서 파생되는 경우를 계층적 상속이라고 합니다. 즉, 단일 상위 클래스가 있는 클래스에는 많은 하위 클래스가 있습니다.
- 다중 상속: 자식 클래스가 여러 부모 클래스로부터 상속받는 것을 다중 상속이라고 합니다. Java에서는 클래스가 아닌 인터페이스의 다중 상속만 지원합니다.
92. 다중 상속이란 무엇입니까? Java에서 지원됩니까?
다중 상속으로 알려진 객체 지향 개념의 구성 요소를 사용하면 클래스가 많은 상위 클래스로부터 속성을 상속받을 수 있습니다. 동일한 시그니처를 가진 메서드가 슈퍼클래스와 서브클래스 모두에 존재하면 문제가 발생합니다. 메서드의 호출자는 어떤 클래스 메서드를 호출해야 하는지 또는 어떤 클래스 메서드에 우선 순위를 두어야 하는지를 컴파일러에 지정할 수 없습니다.
메모: Java는 다중 상속을 지원하지 않습니다
예:
자바 // Java Program to show multiple Inheritance import java.io.*; interface Animal { void eat(); } interface Mammal { void drink(); } class Dog implements Animal, Mammal { public void eat() { System.out.println('Eating'); } public void drink() { System.out.println('Drinking'); } void bark() { System.out.println('Barking'); } } class GFG { public static void main(String[] args) { Dog d = new Dog(); d.eat(); d.drink(); d.bark(); } }> 산출
Eating Drinking Barking>
93. C++의 상속은 Java와 어떻게 다릅니까?
C++의 상속 | Java의 상속 |
|---|---|
| C++를 사용하면 사용자가 여러 클래스를 상속받을 수 있습니다. | Java는 다중 상속을 지원하지 않습니다. |
| C++에서 클래스가 생성되면 객체 클래스에서 상속되지 않고 자체적으로 존재합니다. | Java는 모든 클래스가 객체 클래스에서 어떤 방식으로든 상속하므로 항상 단일 상속을 갖는다고 합니다. |
94. 상속을 사용하는데 제한이 있나요?
예, Java에서 상속을 사용하는 데는 제한이 있습니다. 상속으로 인해 슈퍼 클래스와 인터페이스에서 모든 것을 상속할 수 있기 때문입니다. 그 이유는 하위 클래스가 너무 클러스터되어 있고 특정 상황에서 동적 재정의 또는 동적 오버로딩이 수행될 때 오류가 발생하기 쉽기 때문입니다.
95. 상속은 널리 사용되는 OOP 개념이지만 구성보다 덜 유리합니다. 설명하다.
상속은 객체지향 프로그래밍(OOP)의 널리 사용되는 개념으로, 클래스가 상위 클래스 또는 슈퍼클래스라고 하는 다른 클래스로부터 속성과 메서드를 상속할 수 있습니다. 반면에 컴포지션에서 클래스는 다른 클래스의 인스턴스를 종종 파트 또는 구성 요소라고 하는 멤버 변수로 포함할 수 있습니다. 다음은 구성이 상속보다 유리한 몇 가지 이유입니다.
- 긴밀한 커플링: 슈퍼클래스가 변경될 때마다 이러한 변경 사항은 모든 하위 클래스 또는 하위 클래스의 동작에 영향을 미칠 수 있습니다. 이 문제는 코드의 유연성을 떨어뜨리고 유지 관리 중에 문제를 야기합니다. 이 문제는 또한 클래스 간의 긴밀한 결합으로 이어집니다.
- 취약한 기본 클래스 문제: 기본 클래스를 변경하면 파생 클래스의 기능이 중단될 수 있습니다. 이 문제로 인해 새로운 기능을 추가하거나 기존 기능을 수정하는 것이 어려워질 수 있습니다. 이 문제는 Fragile Base 클래스 문제로 알려져 있습니다.
- 제한된 재사용: Java의 상속으로 인해 코드 재사용이 제한되고 코드 중복도 발생할 수 있습니다. 하위 클래스는 상위 클래스의 모든 속성과 메서드를 상속하므로 때로는 필요하지 않은 불필요한 코드가 생길 수 있습니다. 이로 인해 유지 관리가 덜한 코드베이스가 발생합니다.
96. 협회란 무엇입니까?
연관은 객체를 통해 설정된 두 개의 개별 클래스 간의 관계입니다. Has-A의 관계를 나타냅니다.
97. 집계란 무엇을 의미합니까?
구성은 두 엔터티가 서로 크게 의존하는 제한된 형태의 집계입니다. 그것은 나타냅니다 부분의 관계.
98. 자바의 구성은 어떻게 되나요?
구성은 아이가 관계를 맺는 것을 의미합니다. 독립적으로 존재할 수 없다 부모의. 예를 들어 인간의 마음, 심장은 인간과 별도로 존재하지 않습니다.
99. 구성과 집합의 차이점을 설명하십시오.
집합 | 구성 |
|---|---|
객체 사이에 관계가 있음을 정의합니다. | 부분관계를 나타냅니다. |
객체는 서로 독립적입니다. | 객체는 서로 의존적입니다. |
채워진 다이아몬드를 이용하여 표현해보세요. | 빈 다이아몬드를 이용하여 표현해보세요. |
하위 개체에는 수명이 없습니다. | 하위 개체에는 수명이 있습니다. |
100. 생성자를 상속받을 수 있나요?
아니요, 생성자를 상속할 수 없습니다.
101. 다형성이란 무엇입니까?
다형성은 두 가지 이상의 형식을 취할 수 있는 능력으로 정의됩니다. 즉, 컴파일 시간 다형성 또는 메소드 오버로딩(컴파일 시간 동안 호출되는 함수)이라는 두 가지 유형이 있습니다. 예를 들어 '지역'이라는 수업을 들어보세요. 매개변수의 수에 따라 정사각형, 삼각형 또는 원의 면적을 계산할 수 있습니다. 런타임 다형성 또는 메서드 재정의 - 런타임 중 링크. 클래스 내부의 메서드는 상위 클래스의 메서드를 재정의합니다.
102. 런타임 다형성 또는 동적 메소드 디스패치란 무엇입니까?
동적 메서드 디스패치는 런타임 중 메서드 재정의를 해결하는 메커니즘입니다. 메소드 오버라이딩은 서브클래스의 메소드가 슈퍼클래스의 메소드와 동일한 이름, 매개변수 및 반환 유형을 갖는 것입니다. 재정의된 메서드가 슈퍼클래스 참조를 통해 호출되면 java는 호출이 발생할 때 참조되는 객체의 유형에 따라 실행할 해당 메서드의 버전(슈퍼클래스 또는 하위 클래스)을 결정합니다. 따라서 결정은 런타임에 이루어집니다. 이를 동적 메서드 디스패치라고 합니다.
103. 메소드 재정의란 무엇입니까?
런타임 다형성이라고도 알려진 메서드 재정의는 자식 클래스에 부모 클래스와 동일한 메서드가 포함되어 있는 것입니다. 예를 들어 상위 클래스에 'gfg()'라는 메서드가 있습니다. gfg() 메소드가 하위 클래스에 다시 정의됩니다. 따라서 하위 클래스에서 gfg()가 호출되면 클래스 ID 내의 메서드가 실행됩니다. 여기서 클래스 내의 gfg()는 외부 메서드를 재정의했습니다.
104. 메소드 오버로딩이란 무엇입니까?
메소드 재정의는 Java에서 런타임 다형성을 달성하는 방법입니다. 메서드 재정의는 부모 클래스 중 하나에서 이미 제공한 메서드의 특정 구현을 자식 클래스에서 제공할 수 있도록 하는 기능입니다. 하위 클래스의 메소드가 상위 클래스의 메소드와 이름, 매개변수 또는 시그니처, 반환 유형(또는 하위 유형)이 동일한 경우 하위 클래스의 메소드가 하위 클래스의 메소드를 재정의한다고 합니다. 슈퍼클래스.
105. 정적 메서드를 재정의할 수 있나요?
아니요, 정적 메서드는 객체가 아닌 클래스의 일부이므로 재정의할 수 없습니다.
106. 오버로드된 메서드를 재정의할 수 있나요?
예, 오버로드된 메서드는 컴파일러의 관점에서 완전히 다른 메서드이기 때문입니다. 재정의는 전혀 같은 것이 아닙니다. 어떤 메서드를 호출할지에 대한 결정은 런타임에 연기됩니다.
107. main() 메소드를 오버로드할 수 있나요?
예, Java에서는 미리 정의된 호출 메서드를 사용하여 기본 메서드를 오버로드하여 기본 메서드를 호출할 수 있습니다.
108. 메소드 오버로딩과 메소드 오버라이딩이란 무엇입니까?
메소드 오버로딩: 컴파일 타임 다형성이라고도 합니다. 메서드 오버로드에서는 두 개 이상의 메서드가 다른 시그니처를 사용하여 동일한 클래스에서 공유됩니다.
예:
자바 // Java Program to demonstrate use of Method Overloading import java.io.*; class GFG { static int multiply(int a, int b) { return a * b; } static int multiply(int a, int b, int c) { return a * b * c; } static int multiply(int a, int b, int c, int d) { return a * b * c * d; } public static void main(String[] args) { System.out.println('multiply() with 2 parameters'); System.out.println(multiply(4, 5)); System.out.println('multiply() with 3 parameters'); System.out.println(multiply(2, 3, 4)); System.out.println('multiply() with 4 parameters'); System.out.println(multiply(2, 3, 4, 1)); } }> 산출
multiply() with 2 parameters 20 multiply() with 3 parameters 24 multiply() with 4 parameters 24>
메소드 재정의: 메서드 재정의는 하위 클래스가 부모 클래스나 슈퍼클래스에 이미 정의된 메서드의 구현을 제공할 수 있을 때 발생합니다. 반환 유형, 이름 및 인수는 슈퍼클래스의 메서드와 유사해야 합니다.
예:
자바 // Java Program to demonstrate use of Method Overriding import java.io.*; class Vehicle { void drive() { System.out.println('drive() method of base class'); System.out.println('driving the Car.'); } } class Car extends Vehicle { void drive() { System.out.println( 'drive() method of derived class'); System.out.println('Car is driving.'); } } class GFG { public static void main(String[] args) { Car c1 = new Car(); Vehicle v1 = new Vehicle(); c1.drive(); v1.drive(); Vehicle vehicle = new Car(); // drive() method of Vehicle class is overridden by // Car class drive() vehicle.drive(); } }> 산출
drive() method of derived class Car is driving. drive() method of base class driving the Car. drive() method of derived class Car is driving.>
메소드 오버로딩 | 메소드 재정의 |
|---|---|
두 개 이상의 메서드가 매개 변수는 다르지만 이름은 동일한 동일한 클래스에 있는 경우입니다. | 하위 클래스가 상위 클래스에 이미 정의된 메서드의 자체 구현을 제공하는 경우. |
메서드 오버로딩은 동일한 클래스 내에서나 하위 클래스나 상위 클래스 사이에서만 발생할 수 있습니다. | 메소드 오버라이딩은 서브클래스에서만 가능합니다. |
오류가 발생하면 프로그램의 컴파일 타임에 포착됩니다. | 오류가 발생하면 프로그램 런타임에서 포착됩니다. |
컴파일 시간 다형성의 예. | 런타임 다형성의 예. |
메서드 오버로딩에는 상속이 필요할 수도 있고 필요하지 않을 수도 있습니다. | 메서드 재정의에는 항상 상속이 필요합니다. |
수업 내에서 발생합니다. | 이는 상속 관계를 갖는 두 클래스에서 수행됩니다. |
109. 프라이빗 메서드를 재정의할 수 있나요?
Java에서는 개인 메소드를 대체할 수 없습니다. 메서드 재정의는 부모 클래스의 메서드 대신 하위 클래스의 메서드를 구현하는 것입니다. 프라이빗 메서드는 해당 메서드가 선언된 클래스 내에서만 액세스할 수 있습니다. 이 메서드는 다른 클래스에 표시되지 않고 액세스할 수 없으므로 재정의할 수 없습니다.
110. 하위 클래스에서 재정의된 메서드의 범위를 변경할 수 있나요?
Java에서는 재정의된 메서드의 범위를 수정할 수 없습니다. 서브클래스 메서드의 범위는 슈퍼클래스 메서드의 재정의된 메서드 범위와 같거나 넓어야 합니다. 예를 들어, 하위 클래스의 재정의된 메서드는 공개 범위를 가질 수도 있고, 슈퍼클래스의 재정의된 메서드에 공개 범위가 있는 경우 protected나 default와 같은 더 접근하기 쉬운 범위를 가질 수도 있습니다. 그러나 개인처럼 더 배타적인 범위를 가질 수는 없습니다.
111. 하위 클래스에서 이를 재정의하면서 슈퍼 클래스 메서드의 throws 절을 수정할 수 있습니까?
몇 가지 제한 사항이 있지만 슈퍼클래스 메서드의 throws 절을 수정할 수 있으며, 하위 클래스에서 이를 재정의하는 동안 슈퍼클래스 메서드의 throws 절을 변경할 수 있습니다. 서브클래스 재정의 메서드는 슈퍼클래스 메서드가 예외를 선언하지 않는 경우에만 확인되지 않은 예외를 지정할 수 있습니다. 슈퍼클래스 메서드가 예외를 선언하는 경우 하위 클래스 메서드는 동일한 예외를 선언하거나, 하위 클래스 예외를 선언하거나, 전혀 예외를 선언하지 않을 수 있습니다. 그러나 하위 클래스 메서드는 상위 클래스 메서드에서 선언된 것보다 더 넓은 부모 예외를 선언할 수 없습니다.
112. Java에서 가상 기능을 사용할 수 있나요?
예, Java는 가상 기능을 지원합니다. 함수는 기본적으로 가상이며 final 키워드를 사용하여 비가상으로 만들 수 있습니다.
113. 추상화란 무엇입니까?
추상화는 배경 세부 정보를 포함하지 않고 필수 기능을 표현하는 행위를 의미합니다. 자세한 정보나 구현은 숨겨져 있습니다. 추상화의 가장 일반적인 예는 자동차입니다. 우리는 엔진을 켜고 가속하고 움직이는 방법을 알고 있지만 엔진이 작동하는 방식과 내부 구성 요소는 일반 사용자에게 숨겨진 복잡한 논리입니다. 이는 일반적으로 복잡성을 처리하기 위해 수행됩니다.
114. 추상 클래스란 무엇입니까?
abstract로 선언된 클래스는 인스턴스화할 수 없습니다. 즉, 개체를 만들 수 없습니다. 추상 메소드를 포함할 수도 있고 포함하지 않을 수도 있지만 클래스에 하나 이상의 추상 메소드가 있는 경우 추상으로 선언해야 합니다.
추상 메서드가 있는 추상 클래스의 예:
자바 // Java Program to implement // abstract method import java.io.*; // Abstract class abstract class Fruits { abstract void run(); } // Driver Class class Apple extends Fruits { void run() { System.out.println('Abstract class example'); } // main method public static void main(String args[]) { Fruits obj = new Apple(); obj.run(); } }> 115. 추상 메소드는 언제 사용되나요?
추상 메소드는 메소드를 사용하고 싶지만 하위 클래스가 구현을 결정하도록 하려는 경우에 사용됩니다. 이 경우 상위 클래스와 함께 추상 메소드를 사용합니다.
116. 기본 클래스가 직렬화 가능 인터페이스를 구현하는 경우 하위 클래스의 직렬화를 어떻게 피할 수 있습니까?
기본 클래스가 직렬화 가능 인터페이스를 구현하는 경우 하위 클래스의 직렬화는 writeObject() 메소드를 정의하고 NotSerializedException()을 발생시켜 이를 피할 수 있습니다.
117. Java의 컬렉션 프레임워크란 무엇입니까?
컬렉션은 Java의 객체 단위입니다. 컬렉션 프레임워크는 다양한 방법으로 개체 컬렉션을 표현하고 조작하는 데 사용되는 Java의 인터페이스 및 클래스 집합입니다. 컬렉션 프레임워크에는 클래스(ArrayList, Vector, LinkedList, PriorityQueue, TreeSet)와 여러 인터페이스(Set, List, Queue, Deque)가 포함되어 있으며 모든 인터페이스는 특정 유형의 데이터를 저장하는 데 사용됩니다.
118. Collection 프레임워크에서 사용되는 다양한 인터페이스를 설명하세요.
컬렉션 프레임워크 구현
- 수집 인터페이스
- 목록 인터페이스
- 인터페이스 설정
- 대기열 인터페이스
- 그리고 인터페이스
- 지도 인터페이스
컬렉션 인터페이스: Collection은 java.util.Collection을 사용하여 가져올 수 있는 기본 인터페이스입니다.
통사론:
public interface Collection extends iterable>
119. Java에서 ArrayList를 어떻게 동기화할 수 있나요?
ArrayList는 아래에 언급된 두 가지 방법을 사용하여 동기화할 수 있습니다.
- Collections.synchronizedList() 사용
- CopyOnWriteArrayList 사용
Collections.synchronizedList() 사용:
public static List synchronizedList(List list)>
CopyOnWriteArrayList 사용:
- 빈 목록을 만듭니다.
- List 인터페이스를 구현합니다.
- ArrayList의 스레드로부터 안전한 변형입니다.
- T는 일반을 나타냅니다
120. Java에 벡터(동기화됨)가 있을 때 동기화된 ArrayList가 필요한 이유는 무엇입니까?
ArrayList는 특정 이유 때문에 벡터가 있는 경우에도 필요합니다.
- ArrayList는 벡터보다 빠릅니다.
- ArrayList는 멀티스레딩을 지원하는 반면 벡터는 단일 스레드 사용만 지원합니다.
- 벡터는 단일 스레드를 지원하고 개별 작업은 덜 안전하고 동기화하는 데 시간이 더 오래 걸리므로 ArrayList를 사용하는 것이 더 안전합니다.
- 벡터는 동기화된 특성으로 인해 Java에서 오래된 것으로 간주됩니다.
121. 왜 일반 배열을 만들 수 없나요?
일반 배열은 다음과 같은 이유로 생성될 수 없습니다. 정렬 운반하다 런타임 시 해당 요소의 유형 정보로 인해 런타임 중에 요소 유형이 유사하지 않으면 'ArrayStoreException'이 발생합니다. 제네릭 유형 정보는 컴파일 시 Type Erasure에 의해 지워지기 때문에 배열 저장소 검사는 실패했어야 하는 곳에서 통과되었을 것입니다.
122. 연속된 메모리 위치는 일반적으로 배열에 실제 값을 저장하는 데 사용되지만 ArrayList에는 사용되지 않습니다. 설명하다.
배열의 요소는 인접한 메모리 위치에 저장됩니다. 즉, 각 요소는 배열 내에 있는 요소를 기준으로 별도의 블록에 저장됩니다. 배열의 요소는 인접한 위치에 저장되므로 요소의 위치를 기반으로 요소 주소를 계산할 수 있으므로 인덱스를 통해 모든 요소에 상대적으로 쉽게 액세스할 수 있습니다. 그러나 Java는 ArrayList를 동적 배열로 구현합니다. 즉, 요소가 제거되거나 추가됨에 따라 크기가 변경될 수 있습니다. ArrayList 요소는 이러한 동적 특성을 수용하기 위해 인접한 메모리 위치에 저장되지 않습니다. 대신 ArrayList는 기본 배열이 필요에 따라 더 큰 크기로 확장되고 요소가 새 위치에 복사되는 확장 가능한 배열이라는 메서드를 사용합니다. 동적 크기를 가지며 해당 요소를 인접한 메모리 위치에 저장하지 않는 ArrayList와 달리 배열은 고정된 크기를 가지며 해당 요소가 해당 위치에 저장됩니다.
123. ArrayList를 Array로, Array를 ArrayList로 변환하는 방법을 설명하십시오.
목록을 ArrayList로 변환
List를 ArrayList로 변환하는 방법에는 여러 가지가 있습니다.
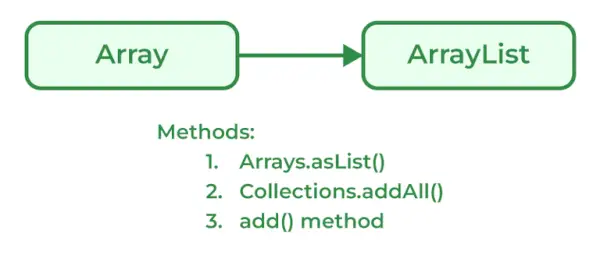
프로그래머는 Arrays 클래스의 asList() 메서드를 사용하여 Array를 ArrayList로 변환할 수 있습니다. List 객체를 허용하는 Arrays 클래스의 정적 메서드입니다.
통사론:
Arrays.asList(item)>
예:
자바 // Java program to demonstrate conversion of // Array to ArrayList of fixed-size. import java.util.*; // Driver Class class GFG { // Main Function public static void main(String[] args) { String[] temp = { 'Abc', 'Def', 'Ghi', 'Jkl' }; // Conversion of array to ArrayList // using Arrays.asList List conv = Arrays.asList(temp); System.out.println(conv); } }> 산출
[Abc, Def, Ghi, Jkl]>
ArrayList를 배열로 변환
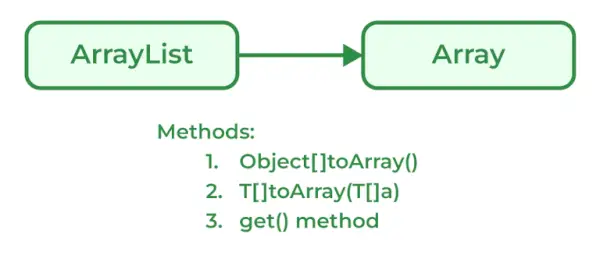
Java 프로그래머는 ArrayList를 다음으로 변환할 수 있습니다.
통사론:
List_object.toArray(new String[List_object.size()])>
예:
자바 // Java program to demonstrate working of // Objectp[] toArray() import java.io.*; import java.util.List; import java.util.ArrayList; // Driver Class class GFG { // Main Function public static void main(String[] args) { // List declared List<Integer> arr = new ArrayList<Integer>(); arr.add(1); arr.add(2); arr.add(3); arr.add(2); arr.add(1); // Conversion Object[] objects = arr.toArray(); // Printing array of objects for (Object obj : objects) System.out.print(obj + ' '); } }> 산출
1 2 3 2 1>
124. ArrayList의 크기는 어떻게 동적으로 커지나요? 또한 내부적으로 어떻게 구현되는지 명시하십시오.
ArrayLists의 배열 기반 특성으로 인해 크기가 동적으로 증가하므로 요소를 위한 충분한 공간이 항상 확보됩니다. ArrayList 요소가 처음 생성될 때 기본 용량은 기본적으로 Java 버전에 따라 달라지는 약 10-16 요소입니다. ArrayList 요소는 원본 배열의 용량이 가득 차면 원본 배열에서 새 배열로 복사됩니다. ArrayList 크기가 동적으로 증가함에 따라 클래스는 더 큰 크기의 새 배열을 만들고 이전 배열의 모든 요소를 새 배열로 복사합니다. 이제 새 배열의 참조가 내부적으로 사용됩니다. 배열을 동적으로 늘리는 과정을 크기 조정이라고 합니다.
125. 자바에서 벡터란 무엇인가?
Java의 벡터는 유사하며 그 안에 여러 요소를 저장할 수 있습니다. 벡터는 아래에 언급된 특정 규칙을 따릅니다.
- 벡터는 Java.util.Vector를 사용하여 가져올 수 있습니다.
- 벡터는 삽입된 요소에 따라 벡터의 크기가 증가하거나 감소함에 따라 동적 배열을 사용하여 구현됩니다.
- 인덱스 번호를 사용하는 벡터의 요소입니다.
- 벡터는 사실상 단일 스레드만 사용한다는 의미로 동기화됩니다(특정 시간에 하나의 프로세스만 수행됨).
- 벡터에는 컬렉션 프레임워크의 일부가 아닌 많은 메서드가 포함되어 있습니다.
통사론:
Vector gfg = new Vector(size, increment);>
126. Java ArrayList를 읽기 전용으로 만드는 방법은 무엇입니까?
ArrayList는 Collections.unmodifyingList() 메서드를 사용하여 컬렉션에서 제공하는 메서드를 통해서만 준비할 수 있습니다.
통사론:
array_readonly = Collections.unmodifiableList(ArrayList);>
예:
자바 // Java program to demonstrate // unmodifiableList() method import java.util.*; public class Main { public static void main(String[] argv) throws Exception { try { // creating object of ArrayList <Character> ArrayList<Character> temp = new ArrayList<Character>(); // populate the list temp.add('X'); temp.add('Y'); temp.add('Z'); // printing the list System.out.println('Initial list: ' + temp); // getting readonly list // using unmodifiableList() method List<Character> new_array = Collections.unmodifiableList(temp); // printing the list System.out.println('ReadOnly ArrayList: ' + new_array); // Adding element to new Collection System.out.println('
If add element in ' + ' the ReadOnly ArrayList'); new_array.add('A'); } catch (UnsupportedOperationException e) { System.out.println('Exception is thrown : ' + e); } } }> 산출
Initial list: [X, Y, Z] ReadOnly ArrayList: [X, Y, Z] If add element in the ReadOnly ArrayList Exception is thrown : java.lang.UnsupportedOperationException>
127. Java의 우선순위 큐란 무엇입니까?

우선순위 큐는 일반 큐 또는 스택 데이터 구조와 유사한 추상 데이터 유형입니다. 요소에 저장된 요소는 낮은 것부터 높은 것까지 정의된 우선순위에 따라 달라집니다. PriorityQueue는 우선순위 힙을 기반으로 합니다.
통사론:
자바 // Java program to demonstrate the // working of PriorityQueue import java.util.*; class PriorityQueueDemo { // Main Method public static void main(String args[]) { // Creating empty priority queue PriorityQueue<Integer> var1 = new PriorityQueue<Integer>(); // Adding items to the pQueue using add() var1.add(10); var1.add(20); var1.add(15); // Printing the top element of PriorityQueue System.out.println(var1.peek()); } }> 산출
10>
128. LinkedList 클래스를 설명해보세요.
LinkedList 클래스는 이중 연결 목록을 사용하여 요소를 저장하는 Java입니다. AbstractList 클래스를 상속하고 List 및 Deque 인터페이스를 구현합니다. LinkedList 클래스의 속성은 다음과 같습니다.
- LinkedList 클래스는 동기화되지 않습니다.
- 게재 순서를 유지합니다.
- 목록, 스택 또는 대기열로 사용할 수 있습니다.
통사론:
LinkedList list_name=new LinkedList();>
129. Java의 Stack 클래스는 무엇이며, 이 클래스에서 제공하는 다양한 메소드는 무엇입니까?
Java의 Stack 클래스는 Last In First Out 데이터 구조를 구현하는 LIFO 데이터 구조입니다. Vector 클래스에서 파생되지만 스택과 관련된 기능이 있습니다. Java의 Stack 클래스는 다음 메소드를 제공합니다.
- 몰래 엿보다(): 스택의 맨 위 항목을 제거하지 않고 반환합니다.
- 비어 있는(): 스택이 비어 있으면 true를 반환하고 그렇지 않으면 false를 반환합니다.
- 푸시(): 항목을 스택의 맨 위로 밀어 넣습니다.
- 팝(): 스택의 맨 위 항목을 제거하고 반환합니다.
- 찾다(): 스택 상단에서 객체의 위치를 1로 반환합니다. 객체가 스택에 없으면 -1을 반환합니다.
130. Java 컬렉션 프레임워크에서 Set은 무엇이며 다양한 구현을 나열합니까?
세트는 중복된 요소를 저장하지 않는 컬렉션입니다. 요소의 순서를 유지하지 않습니다. Java 컬렉션 프레임워크는 다음을 포함하여 Set 인터페이스의 여러 구현을 제공합니다.
- 해시세트: Java의 HashSet은 더 빠른 조회와 더 빠른 삽입을 제공하는 has 테이블에 요소를 저장합니다. HashSet이 주문되지 않았습니다.
- LinkedHashSet: LinkedHashSet은 요소의 삽입 순서를 유지하는 HashSet의 구현입니다.
- 트리세트: TreeSet은 요소의 자연스러운 순서 또는 생성 시 제공된 사용자 정의 비교기에 의해 결정되는 정렬된 순서로 요소를 저장합니다.
131. Java의 HashSet 클래스는 무엇이며 요소를 어떻게 저장합니까?
HashSet 클래스는 Java Collections Framework의 Set 인터페이스를 구현하며 HashSet 클래스의 멤버입니다. 중복 값과 달리 고유한 요소의 컬렉션을 저장합니다. 이 구현에서는 각 요소가 해시 함수를 사용하여 배열의 인덱스에 매핑되고, 인덱스를 사용하여 해당 요소에 빠르게 액세스합니다. 입력 요소를 기반으로 저장된 배열의 요소에 대한 인덱스를 생성합니다. 해시 함수가 버킷에 요소를 적절하게 배포한다고 가정하면 HashSet 클래스는 기본 작업(추가, 제거, 포함 및 크기 조정)에 일정한 시간 성능을 제공합니다.
132. Java 컬렉션 프레임워크의 LinkedHashSet은 무엇입니까?
LinkedHashSet은 모든 요소에 걸쳐 이중 연결 목록에 의해 유지 관리되는 Hashset의 정렬된 버전입니다. 반복 순서가 필요할 때 매우 유용합니다. LinkedHashSet에서 반복하는 동안 요소는 삽입된 순서와 동일한 순서로 반환됩니다.
통사론:
LinkedHashSet hs = new LinkedHashSet();>
예:
자바 // Java Program to implement // LinkedHashSet import java.io.*; import java.util.*; // Driver Class class GFG { // Main Function public static void main(String[] args) { // LinkedHashSet declared LinkedHashSet<Integer> hs = new LinkedHashSet<Integer>(); // Add elements in HashSet hs.add(1); hs.add(2); hs.add(5); hs.add(3); // Print values System.out.println('Values:' + hs); } }> 산출
Values:[1, 2, 5, 3]>
133. Java의 Map 인터페이스란 무엇입니까?
맵 인터페이스는 Java 컬렉션에 있으며 Java.util 패키지와 함께 사용할 수 있습니다. 맵 인터페이스는 키-값 형식으로 값을 매핑하는 데 사용됩니다. 맵에는 모든 고유 키가 포함되어 있습니다. 또한 ContainsKey(), 값 포함() 등과 같은 관련 메서드를 제공합니다.
아래에 언급된 것처럼 지도 인터페이스에는 여러 유형의 지도가 있습니다.
- 정렬된 지도
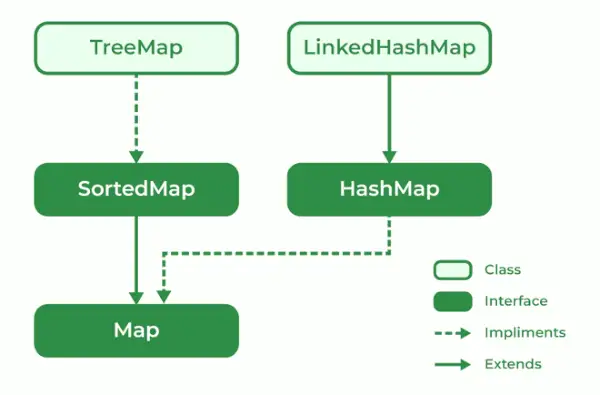
- 트리맵
- 해시맵
- LinkedHashMap
134. 자바에서 트리맵 설명하기
TreeMap은 키-값 쌍의 형태로 데이터를 저장하는 맵 유형입니다. 이는 레드-블랙 트리를 사용하여 구현됩니다. TreeMap의 특징은 다음과 같습니다.
- 고유한 요소만 포함되어 있습니다.
- NULL 키를 가질 수 없습니다.
- 여러 개의 NULL 값을 가질 수 있습니다.
- 비동기화되어 있습니다.
- 오름차순을 유지합니다.
135. EnumSet이란 무엇입니까?
EnumSet은 열거 유형과 함께 사용하기 위한 Set 인터페이스의 특수 구현입니다. EnumSet의 몇 가지 기능은 다음과 같습니다.
- 비동기화되어 있습니다.
- HashSet보다 빠릅니다.
- EnumSet의 모든 요소는 단일 열거 유형에서 나와야 합니다.
- null 개체를 허용하지 않으며 예외에 대해 NullPointerException을 발생시킵니다.
- 이는 오류 방지 반복자를 사용합니다.
통사론:
public abstract class EnumSet>
매개변수: E는 요소를 지정합니다.
136. BlockingQueue란 무엇입니까?
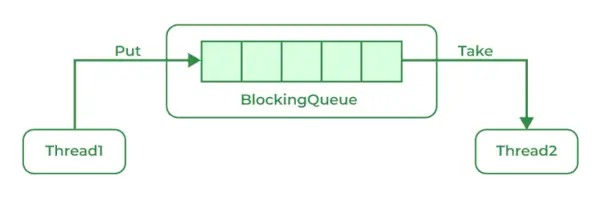
차단 대기열은 요소를 검색하고 제거하는 동안 대기열이 비어 있지 않을 때까지 기다리고, 요소를 추가하는 동안 대기열에서 공간을 사용할 수 있을 때까지 기다리는 작업을 지원하는 대기열입니다.
통사론:
public interface BlockingQueue extends Queue>
매개변수: E는 컬렉션에 저장된 요소의 유형입니다.
137. Java의 ConcurrentHashMap은 무엇이며 구현합니까?
ConcurrentHashMap은 Hashtable을 사용하여 구현됩니다.
통사론:
public class ConcurrentHashMap extends AbstractMap implements ConcurrentMap, Serializable>
매개변수 : K는 키 객체 유형이고 V는 값 객체 유형입니다.
138. 어떤 클래스든 맵 키로 사용할 수 있나요?
예, 아래에 언급된 사전 정의된 특정 규칙을 따르는 경우 모든 클래스를 맵 키로 사용할 수 있습니다.
- equals() 메서드를 재정의하는 클래스는 hashCode() 메서드도 재정의해야 합니다.
- ConcurrentHashMap 클래스는 스레드로부터 안전합니다.
- ConcurrentHashMap의 기본 동시성 수준은 16입니다.
- ConcurrentHashMap에 null 개체를 키나 값으로 삽입하는 것은 불가능합니다.
139. 반복자(Iterator)란 무엇입니까?
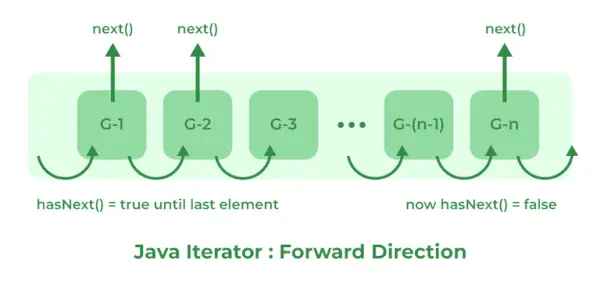
Iterator 인터페이스는 Java의 모든 컬렉션을 반복하는 메소드를 제공합니다. Iterator는 Java 컬렉션 프레임워크의 열거를 대체합니다. _iterator()_ 메서드를 사용하여 컬렉션에서 반복자 인스턴스를 가져올 수 있습니다. 또한 호출자가 반복 중에 기본 컬렉션에서 요소를 제거할 수도 있습니다.
140. 열거형이란 무엇입니까?
열거형은 사용자 정의 데이터 유형입니다. 이는 주로 정수 상수에 이름을 지정하는 데 사용되며, 이름은 프로그램을 읽고 유지하기 쉽게 만듭니다. 열거형의 주요 목적은 사용자 정의 데이터 유형을 정의하는 것입니다.
예:
// A simple enum example where enum is declared // outside any class (Note enum keyword instead of // class keyword) enum Color { RED, GREEN, BLUE; }>141. 컬렉션과 컬렉션의 차이점은 무엇입니까?
수집 | 컬렉션 |
|---|---|
컬렉션은 인터페이스입니다. | 컬렉션은 클래스입니다. |
이는 데이터 구조의 표준 기능을 제공합니다. | 컬렉션 요소를 정렬하고 동기화하는 것입니다. |
데이터 구조에 사용할 수 있는 메소드를 제공합니다. | 다양한 작업에 사용할 수 있는 정적 메서드를 제공합니다. |
142. 자바에서 Array와 ArrayList를 구별하세요.
정렬 | 배열목록 |
|---|---|
단일차원 또는 다차원 | 1차원 |
반복에 사용되는 각각에 대해 | 여기서 반복자는 riverArrayList를 순회하는 데 사용됩니다. |
length 키워드는 배열의 크기를 반환합니다. | size() 메소드는 ArrayList의 크기를 계산하는 데 사용됩니다. |
배열에는 고정 크기가 있습니다. | ArrayList 크기는 동적이며 필요한 경우 크기를 늘리거나 줄일 수 있습니다. |
위와 같이 고정된 크기로 표시되는 것처럼 더 빠릅니다. | 동적 특성으로 인해 상대적으로 느립니다. |
원시 데이터 유형은 가능성이 낮은 객체에 직접 저장될 수 있습니다. | 원시 데이터 유형은 예상치 못한 배열에 직접 추가되지 않으며, 자동박싱 및 언박싱을 통해 간접적으로 추가됩니다. |
여기에 추가할 수 없으므로 유형이 안전하지 않습니다. | 여기에 추가할 수 있으므로 ArrayList 유형이 안전해집니다. |
할당 연산자는 목적만 수행합니다. | 여기서는 add() 메소드라는 특수 메소드가 사용됩니다. |
143. Java에서 배열과 컬렉션의 차이점은 무엇입니까?
정렬 | 컬렉션 |
|---|---|
Java의 배열은 고정된 크기를 갖습니다. | Java의 컬렉션에는 동적 크기가 있습니다. |
배열에서 요소는 인접한 메모리 위치에 저장됩니다. | 컬렉션에서 요소는 반드시 인접한 메모리 위치에 저장되지는 않습니다. |
객체와 기본 데이터 유형을 배열에 저장할 수 있습니다. | 컬렉션에는 개체만 저장할 수 있습니다. |
배열 크기를 조정하려면 수동 조작이 필요합니다. | 컬렉션의 크기 조정은 자동으로 처리됩니다. |
배열에는 조작을 위한 기본 방법이 있습니다. | 컬렉션에는 조작 및 반복을 위한 고급 방법이 있습니다. |
배열은 Java 시작부터 사용할 수 있습니다. | 컬렉션은 Java 1.2에서 도입되었습니다. |
144. ArrayList와 LinkedList의 차이점
배열목록 | 링크드리스트 |
|---|---|
ArrayList는 확장 가능한 배열로 구현됩니다. | LinkedList는 이중 연결 목록으로 구현됩니다. |
ArrayList에서 요소는 인접한 메모리 위치에 저장됩니다. | LinkedList 요소는 각 요소가 다음 및 이전 요소에 대한 참조를 가지므로 연속되지 않은 메모리 위치에 저장됩니다. |
ArrayList는 임의 액세스가 더 빠릅니다. | LinkedList는 삽입 및 삭제 작업이 더 빠릅니다. |
ArrayList는 메모리 효율성이 더 높습니다. | LinkedList는 메모리 효율성이 낮습니다. |
ArrayLists 배열 크기를 유지하기 때문에 더 많은 메모리를 사용합니다. | LinkedList 요소에 대한 참조만 있으므로 메모리를 덜 사용합니다. |
ArrayList에서는 검색 작업이 더 빠릅니다. | LinkedList에서 검색 작업이 느려집니다. |
145. 자바에서 ArrayList와 Vector를 구별하세요.
배열목록 | 벡터 |
|---|---|
ArrayList는 확장 가능한 배열로 구현됩니다. | 벡터는 확장 가능한 배열로 구현됩니다. |
ArrayList가 동기화되지 않았습니다. | 벡터가 동기화되었습니다. |
ArrayList는 비동시 작업의 경우 더 빠릅니다. | 추가된 동기화 오버헤드로 인해 비동시 작업의 경우 벡터가 느려집니다. |
ArrayList는 Java 1.2에서 도입되었습니다. | 벡터는 JDK 1.0에서 도입되었습니다. |
단일 스레드 환경에서 사용하는 것이 좋습니다. | 멀티스레드 환경에서는 벡터를 사용하는 것이 좋습니다. |
ArrayList의 기본 초기 용량은 10입니다. | 벡터에서 기본 초기 용량은 10이지만 기본 증분은 크기의 두 배입니다. |
ArrayList 성능이 높습니다. | 벡터 성능이 낮습니다. |
146. Iterator와 ListIterator의 차이점은 무엇입니까?
반복자 | 목록반복자 |
|---|---|
컬렉션에 있는 요소는 정방향으로만 탐색할 수 있습니다. | 컬렉션에 있는 요소를 정방향과 역방향으로 모두 탐색할 수 있습니다. arraylist 정렬 자바 |
Map, List, Set을 순회하는 데 사용됩니다. | List만 순회할 수 있고 다른 두 개는 순회할 수 없습니다. |
Iterator를 사용하여 인덱스를 얻을 수 없습니다. | List를 순회하는 동안 언제든지 요소의 인덱스를 얻을 수 있는 nextIndex() 및 PreviousIndex()와 같은 메서드가 있습니다. |
컬렉션에 있는 요소를 수정하거나 교체할 수 없습니다. | set(E e)를 사용하여 요소를 수정하거나 교체할 수 있습니다. |
요소를 추가할 수 없으며 ConcurrentModificationException도 발생합니다. | 언제든지 컬렉션에 요소를 쉽게 추가할 수 있습니다. |
Iterator의 특정 메소드는 next(), Remove() 및 hasNext()입니다. | ListIterator의 특정 메소드는 next(), 이전(), hasNext(), hasPrevious(), add(E e)입니다. |
147. HashMap과 HashTable을 구별하세요.
해시맵 | 해시테이블 |
|---|---|
HashMap이 동기화되지 않았습니다. | HashTable이 동기화되었습니다. |
하나의 키는 NULL 값이 될 수 있습니다. | NULL 값은 허용되지 않습니다. |
반복자는 HashMap을 순회하는 데 사용됩니다. | Iterator와 Enumertar를 모두 사용할 수 있습니다. |
HashMap이 더 빠릅니다. | HashTable은 HashMap에 비해 속도가 느립니다. |
148. 반복자와 열거의 차이점은 무엇입니까?
반복자 | 열거 |
|---|---|
Iterator는 레거시 요소와 레거시가 아닌 요소를 모두 탐색할 수 있습니다. | 열거형은 레거시 요소만 순회할 수 있습니다. |
Iterator는 실패하지 않습니다. | 열거는 실패하지 않습니다. |
반복자는 더 느립니다. | 열거가 더 빠릅니다. |
Iterator는 컬렉션을 탐색하는 동안 제거 작업을 수행할 수 있습니다. | 열거는 컬렉션에 대해 순회 작업만 수행할 수 있습니다. |
149. 비교 가능과 비교기의 차이점은 무엇입니까?
유사한 | 비교기 |
|---|---|
인터페이스는 java.lang 패키지에 있습니다. | 인터페이스는 java.util 패키지에 있습니다. |
요소를 정렬하는 CompareTo() 메서드를 제공합니다. | 요소를 정렬하는 Compare() 메서드를 제공합니다. |
단일 정렬 순서를 제공합니다. | 여러 정렬 순서를 제공합니다. |
정렬 논리는 정렬하려는 개체와 동일한 클래스에 있어야 합니다. | 객체의 다양한 속성을 기반으로 다양한 정렬을 작성하려면 정렬 논리가 별도의 클래스에 있어야 합니다. |
메서드는 고정된 정렬 순서에 따라 데이터를 정렬합니다. | 방법은 사용자 정의된 정렬 순서에 따라 데이터를 정렬합니다. |
원래 클래스에 영향을 미칩니다. | 원래 클래스에는 영향을 미치지 않습니다. |
달력, 래퍼 클래스, 날짜 및 문자열을 통해 API에서 자주 구현됩니다. | 타사 클래스의 인스턴스를 정렬하기 위해 구현되었습니다. |
150. 세트와 맵의 차이점은 무엇입니까?
세트 | 지도 |
|---|---|
Set 인터페이스는 java.util 패키지를 사용하여 구현됩니다. | 지도는 java.util 패키지를 사용하여 구현됩니다. |
컬렉션 인터페이스를 확장할 수 있습니다. | 컬렉션 인터페이스를 확장하지 않습니다. |
중복된 값은 허용되지 않습니다. | 중복된 값을 허용합니다. |
세트는 하나의 null 값만 정렬할 수 있습니다. | 맵은 여러 null 값을 정렬할 수 있습니다. |
자바 중급 면접 질문
151. FailFast 반복자와 FailSafe 반복자를 각각의 예와 함께 설명하세요.
FailFast 반복자는 다음을 던지는 반복자입니다. ConcurrentModificationException 반복자가 사용되는 동안 기본 컬렉션이 수정된 것을 감지한 경우. 이는 Java 컬렉션 프레임워크에서 반복자의 기본 동작입니다. 예를 들어 HashMap의 반복자는 FailFast입니다.
예:
자바 예외 처리자바
// Java Program to demonstrate FailFast iterator import java.io.*; import java.util.HashMap; import java.util.Iterator; import java.util.Map; class GFG { public static void main(String[] args) { HashMap<Integer, String> map = new HashMap<>(); map.put(1, 'one'); map.put(2, 'two'); Iterator<Map.Entry<Integer, String> > iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<Integer, String> entry = iterator.next(); // this will throw a // ConcurrentModificationException if (entry.getKey() == 1) { map.remove(1); } } } }> 산출:
Exception in thread 'main' java.util.ConcurrentModificationException>
FailSafe 반복자는 ConcurrentModificationException 반복자가 사용되는 동안 기본 컬렉션이 수정되는 경우. 또는 반복자가 생성될 때 컬렉션의 스냅샷을 생성하고 스냅샷을 반복합니다. 예를 들어 ConcurrentHashMap의 반복자는 FailSafe입니다.
예:
자바
// Java Program to demonstrate FailSafe import java.io.*; import java.util.Iterator; import java.util.Map; import java.util.concurrent.ConcurrentHashMap; class GFG { public static void main(String[] args) { ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap<>(); map.put(1, 'one'); map.put(2, 'two'); Iterator<Map.Entry<Integer, String> > iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<Integer, String> entry = iterator.next(); // this will not throw an exception if (entry.getKey() == 1) { map.remove(1); } } } }> 152. 예외 처리란 무엇입니까?
안 예외 프로그램의 정상적인 흐름을 방해하고 특별한 처리가 필요한 이벤트입니다. 프로그램 실행 중 오류 및 예상치 못한 발생은 Java 예외 처리 메커니즘을 사용하여 처리할 수 있습니다. 다음은 Java에서 예외가 발생하는 몇 가지 이유입니다.
- 장치 고장
- 네트워크 연결 끊김
- 코드 오류
- 사용할 수 없는 파일 열기
- 잘못된 사용자 입력
- 물리적 제한(디스크 메모리 부족)
153. Java 프로그램에서는 몇 가지 유형의 예외가 발생할 수 있습니까?
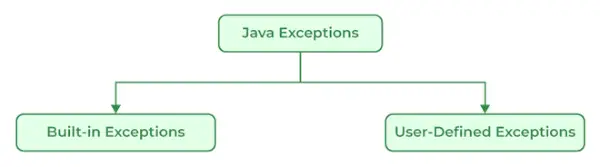
Java에는 일반적으로 두 가지 유형의 예외가 있습니다.
- 내장된 예외: Java의 내장 예외는 Java 라이브러리에서 제공됩니다. 이러한 예외는 확인된 예외와 확인되지 않은 예외라는 두 가지 하위 범주로 더 나눌 수 있습니다. 다음은 Java에 내장된 몇 가지 예외입니다.
- ArrayIndexOutOfBoundsExceptions
- ClassNotFoundException
- FileNotFoundException
- IO예외
- NullPointer예외
- 산술 예외
- 중단된 예외
- 런타임예외
- 사용자 정의 예외: 사용자 정의 예외는 내장 예외에서 다루지 않는 특정 상황이나 오류를 처리하기 위해 프로그래머가 직접 정의합니다. 사용자 정의 예외를 정의하려면 해당 예외 클래스를 확장하는 새 클래스를 정의해야 합니다. Java의 사용자 정의 예외는 내장 예외가 Java에 있을 때 사용됩니다.
154. 오류와 예외의 차이
오류 | 예외 |
|---|---|
오류 복구는 불가능합니다. | try-catch 블록을 사용하거나 호출자에게 예외를 다시 던져 예외로부터 복구합니다. |
오류는 모두 Java에서 확인되지 않은 유형입니다. | 여기에는 확인된 유형과 확인되지 않은 유형이 모두 포함됩니다. |
오류는 대부분 프로그램이 실행되는 환경으로 인해 발생합니다. | 프로그램은 대부분 예외 발생을 담당합니다. |
런타임뿐만 아니라 컴파일 타임에도 오류가 발생할 수 있습니다. 컴파일 시간: 구문 오류, 런타임: 논리적 오류. | 모든 예외는 런타임에 발생하지만 확인된 예외는 컴파일러에 알려진 반면 확인되지 않은 예외는 그렇지 않습니다. |
이는 java.lang.Error 패키지에 정의되어 있습니다. | java.lang.Exception 패키지에 정의되어 있습니다. |
예 : java.lang.StackOverflowError, java.lang.OutOfMemoryError | 예 : 확인된 예외: SQLException, IOException 확인되지 않은 예외: ArrayIndexOutOfBoundException, NullPointerException, ArithmeticException. |
155. Java Exception 클래스의 계층구조를 설명하세요.
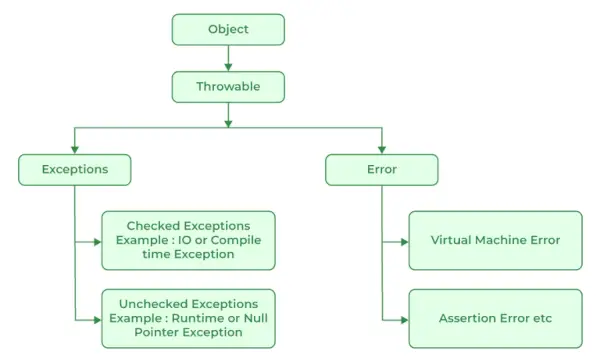
Java의 모든 예외 및 오류 유형은 계층 구조의 기본 클래스인 throwable 클래스의 하위 클래스입니다. 그런 다음 이 클래스는 사용자 프로그램이 포착해야 하는 예외 조건에 사용됩니다. NullPointerException은 이러한 예외의 예입니다. 또 다른 분기인 오류는 Java 런타임 시스템에서 JRE와 관련된 오류를 나타내는 데 사용됩니다. StackOverflowError는 이러한 오류 중 하나의 예입니다.
156. 런타임 예외를 설명하세요.
런타임 예외는 컴파일 중에 발생하는 컴파일 타임 예외와 달리 코드 실행 중에 발생하는 예외입니다. 런타임 예외는 JVM에서 설명되지 않으므로 확인되지 않은 예외입니다.
Java의 런타임 예외의 예는 다음과 같습니다.
- NullPointerException: 응용 프로그램이 null 개체 참조를 사용하려고 할 때 발생합니다.
- ArrayIndexOutOfBoundsException: 이는 애플리케이션이 범위를 벗어난 배열 인덱스에 액세스하려고 할 때 발생합니다.
- ArithmeticException: 응용 프로그램이 0으로 나누려고 할 때 발생합니다.
- IllegalArgumentException: 메서드가 불법적이거나 부적절한 인수에 전달될 때 발생합니다.
확인된 예외와 달리 런타임 예외에는 throws 절의 선언이나 try-catch 블록의 캡처가 필요하지 않습니다. 그러나 의미 있는 오류 메시지를 제공하고 시스템 충돌을 방지하려면 런타임 예외를 처리하는 것이 좋습니다. 런타임 예외는 확인된 예외보다 문제에 대해 더 구체적인 정보를 제공하므로 개발자는 프로그래밍 오류를 더 쉽고 빠르게 감지하고 수정할 수 있습니다.
157. NullPointerException이란 무엇입니까?
이는 프로그램이 null 값이 있는 개체 참조를 사용하려고 할 때 발생하는 일종의 런타임 예외입니다. NullPointerException의 주요 용도는 참조 변수에 값이 할당되지 않았음을 나타내는 것이며 연결된 목록 및 트리와 같은 데이터 구조를 구현하는 데에도 사용됩니다.
158. ArrayStoreException은 언제 발생하나요?
ArrayStoreException은 객체 배열에 잘못된 유형의 객체를 저장하려고 시도할 때 발생합니다.
예:
자바
// Java Program to implement // ArrayStoreException public class GFG { public static void main(String args[]) { // Since Double class extends Number class // only Double type numbers // can be stored in this array Number[] a = new Double[2]; // Trying to store an integer value // in this Double type array a[0] = new Integer(4); } }> 예:
Exception in thread 'main' java.lang.ArrayStoreException: java.lang.Integer at GFG.main(GFG.java:6)>
159. Checked Exception과 Unchecked Exception의 차이점은 무엇입니까?
확인된 예외:
확인된 예외는 프로그램 컴파일 시간 동안 확인되는 예외입니다. 프로그램에서 메소드 내의 일부 코드가 확인된 예외를 발생시키는 경우 메소드는 예외를 처리하거나 throws 키워드를 사용하여 예외를 지정해야 합니다.
확인된 예외에는 두 가지 유형이 있습니다.
- 완전히 검사된 예외: IOException 및 InterruptedException과 같은 모든 하위 클래스도 검사됩니다.
- 부분적으로 확인된 예외: 예외처럼 하위 클래스 중 일부가 선택 해제되어 있습니다.
확인되지 않은 예외:
선택 취소는 프로그램 컴파일 타임에 확인되지 않는 예외입니다. Error 및 RuntimeException 클래스 아래의 예외는 확인되지 않은 예외이며, throwable 아래의 다른 모든 항목은 확인됩니다.
160. Error와 Exception의 기본 클래스는 무엇입니까?
에러는 사용자가 수행한 불법적인 연산으로 인해 프로그램에 이상이 발생하는 것입니다. 예외는 프로그램을 실행하는 동안 발생하는 예상치 못한 이벤트나 조건이며, 예외는 프로그램 명령의 정상적인 흐름을 방해합니다.
오류와 예외 모두 java.lang.Throwable 클래스인 공통 상위 클래스를 갖습니다.
161. 각 try 블록 뒤에는 catch 블록이 와야 합니까?
아니요. Java에서는 finally 블록과 다른 조합을 만들 수 있으므로 try 블록 다음에 catch 블록을 사용할 필요가 없습니다. 마지막으로 예외가 발생했는지 여부에도 불구하고 실행되는 블록입니다.
162. 예외 전파란 무엇입니까?
예외 전파는 예외가 스택의 위에서 아래로 삭제되는 프로세스입니다. 한 번도 포착되지 않으면 예외는 다시 이전 메서드로 떨어지고, 포착되거나 호출 스택의 맨 아래에 도달할 때까지 계속됩니다.
163. Try 또는 catch 블록에 System.exit(0)을 넣으면 어떻게 됩니까? 드디어 블록이 실행되나요?
System.exit(int)에는 SecurityException을 발생시키는 기능이 있습니다. 따라서 보안상의 경우 예외가 발생하면 finally 블록이 실행되고 그렇지 않으면 JVM이 System을 호출하는 동안 닫힙니다. exit(0) 때문에 finally 블록이 실행되지 않습니다.
164. 객체 복제에 대해 무엇을 이해하고 있으며 Java에서 이를 어떻게 달성합니까?
이는 모든 개체의 정확한 복사본을 만드는 프로세스입니다. 이를 지원하려면 Java 클래스는 java.lang 패키지의 Cloneable 인터페이스를 구현하고 Object 클래스에서 제공하는 clone() 메서드를 재정의해야 하며 그 구문은 다음과 같습니다.
Protected Object clone() throws CloneNotSupportedException{ return (Object)super.clone();}Cloneable 인터페이스가 구현되지 않고 메서드만 재정의된 경우 Java에서 CloneNotSupportedException이 발생합니다.
165. 예외를 처리하지 않는 경우 예외는 프로그램에 어떤 영향을 미치나요?
예외는 프로그램 실행 중에 프로그램 실행을 갑자기 종료하는 책임이 있으며 예외가 발생한 후에 작성된 코드는 실행되지 않습니다.
166. 최종 키워드의 용도는 무엇입니까?
final 키워드는 함수를 비가상으로 만드는 데 사용됩니다. 기본적으로 모든 함수는 가상이므로 비가상으로 만들기 위해 final 키워드를 사용합니다.
167. final, finally, finalize 키워드는 어떤 목적을 달성합니까?
나). 결정적인:
final은 재정의할 수 없도록 변수, 메서드 또는 클래스와 함께 사용되는 키워드입니다.
예:
자바
// Java Program to use final // keyword import java.io.*; // Driver Class class GFG { // Main function public static void main(String[] args) { final int x = 100; x = 50; } }> 산출:
./GFG.java:6: error: cannot assign a value to final variable x x=50; ^ 1 error>
ii). 마지막으로
finally는 예외 처리에서 try-catch와 함께 사용되는 코드 블록입니다. finally 블록에 작성된 코드는 예외가 발생했는지 여부에도 불구하고 실행됩니다.
예:
자바
// Java Program to implement finally import java.io.*; // Driver class class GFG { // Main function public static void main(String[] args) { int x = 10; // try block try { System.out.println('Try block'); } // finally block finally { System.out.println( 'Always runs even without exceptions'); } } }> 산출
Try block Always runs even without exceptions>
iii). 마무리하다
가비지 수집 대상 객체를 삭제/파괴하기 직전에 호출되어 정리 활동을 수행하는 메소드입니다.
예:
자바
/*package whatever // do not write package name here */ import java.io.*; class GFG { public static void main(String[] args) { System.out.println('Main function running'); System.gc(); } // Here overriding finalize method public void finalize() { System.out.println('finalize method overridden'); } }> 산출
Main function running>
168. Java에서 this()와 super()의 차이점은 무엇입니까?
이것( ) | 슈퍼( ) |
|---|---|
이는 클래스의 현재 인스턴스를 나타냅니다. | 이는 상위 클래스의 현재 인스턴스를 나타냅니다. |
동일한 클래스의 기본 생성자를 호출합니다. | 기본 클래스의 기본 생성자를 호출합니다. |
동일한 클래스의 메서드에 액세스합니다. | 상위 클래스의 메서드에 액세스합니다. |
현재 클래스 인스턴스를 가리킵니다. | 슈퍼클래스 인스턴스를 가리킵니다. |
169. 멀티태스킹이란 무엇입니까?
Java에서 멀티태스킹이란 한 번에 여러 작업을 수행할 수 있는 프로그램의 능력을 말합니다. 단일 프로그램 내에 포함된 빠른 작업인 스레드가 이를 수행할 수 있습니다. 한 번에 여러 가지 작업을 수행하는 것을 멀티태스킹이라고 합니다.
예:
자바
// Java program for multitasking import java.io.*; public class MyThread extends Thread { public void run() { // Code to be executed in this thread for (int i = 0; i < 10; i++) { System.out.println( 'Thread ' + Thread.currentThread().getId() + ': ' + i); } } } public class GFG { public static void main(String[] args) { MyThread thread1 = new MyThread(); MyThread thread2 = new MyThread(); // Start the threads thread1.start(); thread2.start(); } }> 170. 멀티스레드 프로그램이란 무엇을 의미합니까?
Java의 다중 스레드 프로그램에는 순차적으로 실행되는 대신 동시에 실행되는 스레드가 포함되어 있습니다. 컴퓨터는 여러 작업을 동시에 결합하여 리소스를 보다 효율적으로 사용할 수 있습니다. 멀티스레딩 기능이 있는 모든 프로그램에서는 여러 복사본을 실행하지 않고도 두 명 이상의 사용자가 동시에 프로그램을 사용할 수 있습니다. 다중 스레드 프로그램은 동시에 여러 프로세스를 실행하도록 설계되어 프로그램 성능을 향상시키고 프로그램이 여러 프로세서를 활용하여 전체 처리량을 향상시킬 수 있습니다.
171. 멀티스레딩의 장점은 무엇입니까?
멀티스레딩을 사용하면 다음과 같은 여러 가지 이점이 있습니다.
- 응답성: 멀티스레딩 대화형 응용 프로그램을 사용하면 섹션이 차단되거나 긴 프로세스를 실행하는 경우에도 코드를 실행할 수 있으므로 사용자 응답성이 높아집니다.
- 자원 공유: 프로세스는 멀티스레딩으로 인해 메시지 전달 및 공유 메모리를 수행할 수 있습니다.
- 경제성: 프로세스가 경제적이기 때문에 메모리를 공유할 수 있습니다.
- 확장성: 여러 CPU 시스템의 멀티스레딩은 병렬성을 높입니다.
- 향상된 통신: 스레드 동기화 기능은 프로세스 간 통신을 향상시킵니다.
- 멀티프로세서 아키텍처 활용
- 시스템 리소스 사용 최소화
172. Thread를 생성할 수 있는 두 가지 방법은 무엇입니까?
멀티스레딩은 CPU 활용도를 최대화하기 위해 프로그램의 두 부분 이상을 동시에 실행할 수 있는 Java 기능입니다. 일반적으로 스레드는 별도의 실행 경로가 있는 작고 가벼운 프로세스입니다. 이러한 스레드는 공유 메모리를 사용하지만 독립적으로 작동하므로 한 스레드가 실패하더라도 다른 스레드에는 영향을 미치지 않습니다. 스레드를 생성하는 방법에는 두 가지가 있습니다.
- Thread 클래스를 확장하여
- Runnable 인터페이스를 구현합니다.
Thread 클래스를 확장하여
우리는 java.lang.Thread 클래스 . 이 클래스는 Thread 클래스에서 사용할 수 있는 run() 메서드를 재정의합니다. 스레드는 run() 메서드 내에서 수명을 시작합니다.
통사론:
public class MyThread extends Thread { public void run() { // thread code goes here } }>Runnable 인터페이스를 구현함으로써
구현하는 새 클래스를 만듭니다. java.lang.실행 가능 인터페이스를 사용하고 run() 메서드를 재정의합니다. 그런 다음 Thread 객체를 인스턴스화하고 이 객체에 대해 start() 메서드를 호출합니다.
통사론:
public class MyRunnable implements Runnable { public void run() { // thread code goes here } }>173. 스레드란 무엇입니까?
Java의 스레드는 가장 작은 프로세스 단위로 경량화된 하위 프로세스이며 별도의 실행 경로를 갖습니다. 이러한 스레드는 공유 메모리를 사용하지만 동일한 메모리를 공유함에도 불구하고 다른 스레드의 작업에 영향을 주지 않는 스레드에 예외가 있는 경우 독립적으로 작동합니다. 스레드에는 자체 프로그램 카운터, 실행 스택 및 지역 변수가 있지만 동일한 프로세스의 다른 스레드와 동일한 메모리 공간을 공유합니다. Java는 다음을 통해 멀티스레딩을 기본적으로 지원합니다. 실행 가능한 인터페이스 그리고 스레드 클래스 .
174. 프로세스와 스레드를 구별하나요?
프로세스와 스레드는 모두 컴퓨터 시스템의 실행 단위이지만 여러 면에서 다릅니다.
프로세스 | 실 |
|---|---|
프로세스는 실행 중인 프로그램입니다. | 스레드는 프로세스 내의 단일 명령 시퀀스입니다. |
프로세스를 종료하는 데 더 많은 시간이 걸립니다. | 스레드를 종료하는 데 시간이 덜 걸립니다. |
프로세스는 컨텍스트 전환에 더 많은 시간이 걸립니다. | 스레드는 컨텍스트 전환에 더 적은 시간이 걸립니다. |
이 프로세스는 의사소통 측면에서 효율성이 떨어집니다. | 스레드는 통신 측면에서 더 효율적입니다. |
프로세스가 격리되어 있습니다. | 스레드는 메모리를 공유합니다. |
프로세스에는 자체 프로세스 제어 블록, 스택 및 주소 공간이 있습니다. | 스레드는 상위 PCB, 자체 스레드 제어 블록, 스택 및 공통 주소 공간을 갖습니다. |
프로세스는 서로 데이터를 공유하지 않습니다. | 스레드는 서로 데이터를 공유합니다. |
175. 스레드의 수명주기를 설명해주세요.
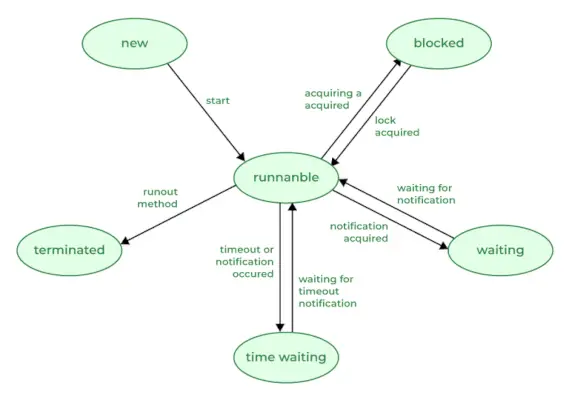
ㅏ 실 Java에서는 특정 시점에 다음 상태 중 하나에 존재합니다. 스레드는 언제든지 표시된 상태 중 하나에만 있습니다.
- 새로운: 스레드가 생성되었지만 아직 시작되지 않았습니다.
- 실행 가능: 스레드가 실행 중이거나 해당 작업을 실행 중이거나 우선 순위가 더 높은 다른 스레드가 없는 경우 실행할 준비가 되어 있습니다.
- 막힌: 스레드가 일시적으로 중단되어 리소스나 이벤트를 기다리고 있습니다.
- 대기 중: 스레드는 다른 스레드가 작업을 수행하거나 지정된 시간이 경과할 때까지 기다리고 있습니다.
- 종료됨: 스레드가 작업을 완료했거나 다른 스레드에 의해 종료되었습니다.
176. Thread 클래스의 suspens() 메소드를 설명하세요.
Java에서 Thread 클래스의 suspens() 메소드는 스레드의 실행을 일시적으로 중단합니다. 스레드가 일시 중단되면 차단된 상태가 되며 운영 체제에 의해 예약되지 않습니다. 즉, 스레드는 재개될 때까지 해당 작업을 실행할 수 없습니다. 최신 Java 프로그래밍 언어에는 suspens() 메서드보다 더 안전하고 유연한 대안이 있습니다. 이 메서드는 어떤 값도 반환하지 않습니다.
통사론:
public final void suspend();>
예:
자바
// Java program to show thread suspend() method import java.io.*; class MyThread extends Thread { public void run() { for (int i = 0; i < 10; i++) { System.out.println(' Running thread : ' + i); try { Thread.sleep(1000); } catch (Interrupted_Exception e) { e.printStackTrace(); } } } } class GFG { public static void main(String[] args) { MyThread t1 = new MyThread(); t1.start(); try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } // suspend the execution of the thread t1.suspend(); System.out.println('Suspended thread '); try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } // resume the execution of the thread t1.resume(); System.out.println('Resumed thread'); } }> 산출:
Thread running: 0 Thread running: 1 Thread running: 2 Suspended thread Resumed thread Thread running: 3 Thread running: 4 Thread running: 5 Thread running: 6 Thread running: 7 Thread running: 8 Thread running: 9>
177. Thread 클래스 실행에서 메인 스레드를 설명하세요.
Java는 다중 스레드 프로그래밍을 기본적으로 지원합니다. 메인 스레드는 프로그램 실행 중에 생성되는 다른 모든 스레드의 상위 스레드로 간주됩니다. 메인 스레드는 프로그램이 실행되기 시작하면 자동으로 생성됩니다. 이 스레드는 프로그램의 기본 메소드를 실행합니다. Java 프로그램의 기본 논리를 실행하고 사용자 입력 작업을 처리하는 역할을 담당합니다. 메인 스레드는 다른 모든 하위 스레드가 생성되는 기본 스레드 역할을 합니다.
178. 데몬 스레드란 무엇입니까?
Java의 데몬 스레드는 백그라운드 작업이나 지속적으로 수행하는 데 사용되는 작업을 수행하는 데 사용되는 우선 순위가 낮은 스레드입니다. 가비지 수집, 신호 디스패치, 액션 리스너 등과 같은 Java의 데몬 스레드는 사용자 스레드보다 우선순위가 낮습니다. 즉, 실행 중인 사용자 스레드가 없을 때만 실행할 수 있습니다. Java의 데몬 스레드는 명시적인 종료 또는 종료가 필요하지 않은 백그라운드 작업에 필요한 유용한 기능입니다. 이를 통해 시스템 리소스를 보다 효율적으로 사용할 수 있으며 리소스를 단순화하고 장기 실행 작업을 단순화할 수 있습니다.
179. 스레드가 대기 상태에 들어갈 수 있는 방법은 무엇입니까?
스레드는 단일 프로세스 내에서 다른 스레드와 동시에 실행되는 경량 프로세스입니다. 각 스레드는 서로 다른 작업을 실행하고 단일 프로세스 내에서 리소스를 공유할 수 있습니다. Java의 스레드는 다양한 방법으로 대기 상태로 들어갈 수 있습니다.
- Sleep() 메소드 호출: 수면 () 메소드는 특정 시간 동안 스레드 실행을 일시 중지하는 데 사용됩니다. 스레드가 일시 중지된 동안 대기 상태로 전환됩니다.
- 대기() 메서드: 이 메서드는 다른 스레드가 깨어나라는 신호를 보낼 때까지 스레드를 기다리는 데 사용됩니다. 스레드는 다른 스레드로부터 알림을 받을 때까지 대기 상태로 전환됩니다.
- Join() 메서드: Join() 메서드를 사용하여 스레드가 실행을 마칠 때까지 기다릴 수 있습니다. 호출 스레드는 대상 스레드가 완료될 때까지 대기 상태로 전환됩니다.
- I/O 작업을 기다리는 중: 스레드가 입출력 작업이 완료되기를 기다리고 있으면 작업이 완료될 때까지 대기 상태로 들어갑니다.
- 동기화 문제: 다중 스레드 애플리케이션에 동기화 문제가 있는 경우 스레드는 동기화 문제가 해결될 때까지 대기 상태가 될 수 있습니다.
180. 단일 CPU를 사용하는 컴퓨터에서 멀티스레딩은 어떻게 발생합니까?
Java는 일반적으로 시간 분할이라고 하는 시간 공유라는 기술을 사용하여 단일 CPU가 있는 컴퓨터에서 멀티스레딩을 구현합니다. 병렬 실행의 모양은 CPU가 활성 스레드 간을 전환함으로써 생성됩니다. 운영 체제는 각 스레드에 CPU 시간을 순차적으로 할당하고 스레드를 예약하는 역할을 담당합니다.
스레드가 서로 상호 작용하고 경합 상황이나 기타 문제가 발생하는 것을 방지하기 위해 Java에는 동기화 및 잠금을 포함하여 스레드의 동작을 제어하는 여러 가지 방법이 있습니다. 스레드 간의 상호 작용을 조절하고 중요한 코드 부분이 동기화되는지 확인함으로써 단일 CPU가 있는 시스템에서 정확하고 효과적으로 작동하는 멀티 스레드 프로그래머를 만드는 것이 가능합니다. 다중 CPU 또는 코어가 있는 컴퓨터에서 동일한 프로그램을 실행하는 것과 달리 단일 CPU에서의 다중 스레딩은 병렬 처리처럼 보일 뿐이며 실제 성능 향상은 미미할 수 있습니다. 운영 체제는 단일 CPU에서 수많은 스레드가 실행될 때 사용 가능한 CPU 시간을 작은 시간 조각으로 나누고 각 스레드에 실행할 시간 조각을 제공합니다. 운영 체제에 의한 스레드 간의 신속한 전환은 병렬 실행처럼 보입니다. 스레드 간의 전환은 시간 분할이 밀리초 또는 마이크로초 단위로 매우 작기 때문에 즉각적인 것처럼 보입니다.
경험이 풍부한 Java 면접 질문
181. Java의 다양한 스레드 우선순위 유형은 무엇입니까? 그리고 JVM이 할당한 스레드의 기본 우선순위는 무엇입니까?
스레드의 우선순위는 모든 스레드가 우선순위를 갖는 개념으로, 일반인의 언어에서는 모든 개체가 여기에서 1부터 10까지의 숫자로 표시되는 우선순위를 갖는다고 말할 수 있습니다. 아래에 언급된 Java에는 다양한 유형의 스레드 속성이 있습니다.
- MIN_PRIORITY
- MAX_PRIORITY
- NORM_PRIORITY
기본적으로 스레드에는 NORM_PRIORITY가 할당됩니다.
182. Java에서 가비지 수집이 필요한 이유는 무엇입니까?
Java의 경우 프로그램이 중단되고 불안정해질 수 있는 메모리 누수를 방지하려면 가비지 수집이 필요합니다. Java에서는 가비지 수집을 피할 수 있는 방법이 없습니다. C++와 달리 Java의 가비지 수집은 프로그래머가 메모리 리소스를 관리하고 메모리 누수를 걱정하는 대신 애플리케이션 개발에 집중할 수 있도록 도와줍니다. JVM(Java Virtual Machine)은 애플리케이션에서 사용되지 않는 메모리를 해제하는 가비지 수집기를 실행하여 메모리를 주기적으로 자동 관리합니다. 가비지 수집은 힙 메모리에서 참조되지 않은 객체를 제거하므로 Java 메모리를 효율적으로 만듭니다.
183. 가비지컬렉션의 단점은 무엇인가요?
많은 장점 외에도 Garbage Collector에는 아래에 언급된 몇 가지 단점이 있습니다.
- 가비지 수집의 가장 큰 단점은 응용 프로그램의 성능을 저하시키는 메모리를 지우기 때문에 응용 프로그램 실행이 일시 중지될 수 있다는 것입니다.
- 가비지 수집 프로세스는 비결정적이므로 가비지 수집이 발생하는 시기를 예측하기 어렵고 이로 인해 애플리케이션에서 예측할 수 없는 동작이 발생합니다. 예를 들어, 프로그램을 작성하는 경우 프로그래머는 문제가 가비지 수집으로 인해 발생했는지 아니면 프로그램의 다른 요인으로 인해 발생했는지 판단하기 어렵습니다.
- 프로그램이 수명이 짧은 개체를 많이 생성하고 삭제하는 경우 가비지 수집으로 인해 메모리 사용량이 늘어날 수도 있습니다.
184. 마이너, 메이저, 전체 가비지 컬렉션의 차이점을 설명하세요.
JVM(Java Virtual Machine)은 주기적으로 개체를 확인하고 제거하는 가비지 수집기를 사용하여 더 이상 사용되지 않는 개체를 제거합니다. JVM에는 다양한 유형의 가비지 수집이 있으며 각각 특성과 성능에 미치는 영향이 다릅니다. 가비지 수집의 주요 유형은 다음과 같습니다.
- 사소한 가비지 수집: 젊은 세대 가비지 수집이라고도 하는 이 유형의 가비지 수집은 수명이 짧은 개체(빠르게 생성되고 삭제되는 개체)에서 사용하는 메모리를 수집하고 회수하는 데 사용됩니다.
- 주요 가비지 수집: 구세대 가비지 수집이라고도 하는 이 유형의 가비지 수집은 수명이 긴 개체(여러 번의 사소한 가비지 수집 후에도 유지되고 이전 세대로 승격되는 개체)에서 사용하는 메모리를 수집하고 회수하는 데 사용됩니다.
- 전체 가비지 수집: 전체 가비지 수집 중에는 젊은이와 노인의 기억을 포함하여 모든 세대의 기억이 수집되고 재생됩니다. 전체 가비지 수집은 일반적으로 해당 앱이 일시적으로 중지되는 사소한 또는 주요 가비지 수집보다 완료하는 데 시간이 더 오래 걸립니다.
185. Java에서 주요 및 사소한 가비지 수집을 어떻게 식별합니까?
주요 가비지 수집은 생존 공간에서 작동하고 사소한 가비지 수집은 Eden 공간에서 작동하여 표시 및 청소 루틴을 수행합니다. 그리고 마이너 컬렉션이 GC를 인쇄하는 반면, 가비지 컬렉션 로깅이 -XX:PrintGCDetails 또는 verbose:gc로 활성화된 경우 메이저 컬렉션은 전체 GC를 인쇄하는 출력을 기반으로 두 가지를 모두 식별할 수 있습니다.
186. 메모리 누수란 무엇이며, 가비지 수집에 어떤 영향을 미치나요?
Java 메모리 누수는 리소스를 제대로 닫지 않거나, 필요 이상으로 객체 참조를 오래 유지하거나, 불필요하게 너무 많은 객체를 생성하는 등 다양한 요인으로 인해 발생할 수 있습니다. 해당 개체에 대한 참조가 있기 때문에 가비지 수집기가 개체를 수집하지 않는 상황이 있습니다. 애플리케이션이 많은 객체를 생성하고 이를 사용하지 않고 모든 객체에 유효한 참조가 있는 이러한 상황에서는 Java의 가비지 수집기가 객체를 삭제할 수 없습니다. 프로그램에 아무런 가치도 제공하지 않는 이러한 쓸모없는 개체를 메모리 누수라고 합니다. 메모리 누수는 가비지 수집기가 사용되지 않은 메모리를 회수하지 못하게 하여 가비지 수집에 부정적인 영향을 미칠 수 있습니다. 이 동작으로 인해 성능이 저하되거나 때로는 시스템 오류가 발생합니다. 프로그램에서는 리소스와 개체 참조를 적절하게 관리하여 메모리 누수를 방지하는 것이 중요합니다.
예:
자바
// Java Program to demonstrate memory leaks import java.io.*; import java.util.Vector; class GFG { public static void main(String[] args) { Vector a = new Vector(21312312); Vector b = new Vector(2147412344); Vector c = new Vector(219944); System.out.println('Memory Leak in Java'); } }> 산출:
Exception in thread 'main' java.lang.OutOfMemoryError: Java heap space at java.base/java.util.Vector.(Vector.java:142) at java.base/java.util.Vector.(Vector.java:155) at GFG.main(GFG.java:9)>
187. java.util.regex 패키지에 존재하는 일부 클래스의 이름을 지정하십시오.
Java의 정규식 또는 Regex는 Java에서 문자열을 검색하고 조작하는 데 사용되는 API입니다. 문자열에서 필요한 데이터를 추출하거나 패턴을 일반화할 수 있는 문자열 패턴을 생성합니다.
java.util.regex에는 아래에 언급된 3개의 클래스가 있습니다.
- 패턴 클래스: 패턴을 정의할 수 있습니다.
- Matcher 클래스: 패턴을 사용하여 텍스트에 대한 일치 작업을 수행할 수 있습니다.
- PatternSyntaxException 클래스: 정규식 패턴의 구문 오류를 나타낼 수 있습니다.
또한 3개 클래스 패키지 외에도 일치 작업의 결과를 나타내는 데 사용할 수 있는 단일 인터페이스 MatchResult 인터페이스로 구성됩니다.
188. 비밀번호의 유효성을 검사하는 정규식을 작성하세요. 비밀번호는 알파벳으로 시작하고 그 뒤에 영숫자가 와야 합니다. 길이는 8에서 20 사이여야 합니다.
regex = ^(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[@#$%^&-+=()])(?=S+$).{8, 20}$>설명:
- ^ 문자열의 시작 문자에 사용됩니다.
- (?=.*[0-9]) 숫자에 사용되는 문자는 적어도 한 번 이상 발생해야 합니다.
- (?=.*[a-z])는 알파벳 소문자로 한 번 이상 나타나야 합니다.
- (?=.*[A-Z])는 하위 문자열에 한 번 이상 나타나야 하는 대문자 알파벳에 사용됩니다.
- (?=.*[@#$%^&-+=()] 적어도 한 번 이상 발생해야 하는 특수 문자에 사용됩니다.
- (?=S+$) 공백은 전체 문자열에서 허용되지 않습니다.
- .{8, 20}은 최소 8자, 최대 20자에 사용됩니다.
- $는 문자열의 끝 부분에 사용됩니다.
189. JDBC란 무엇인가?
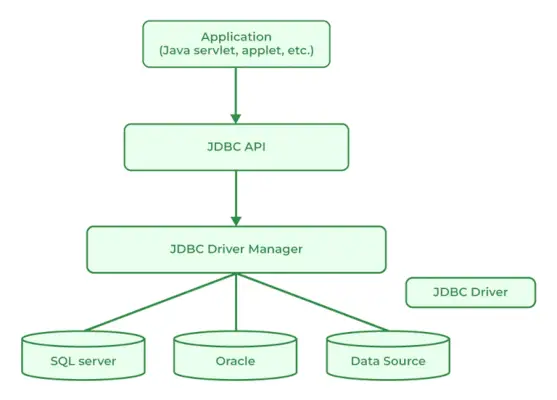
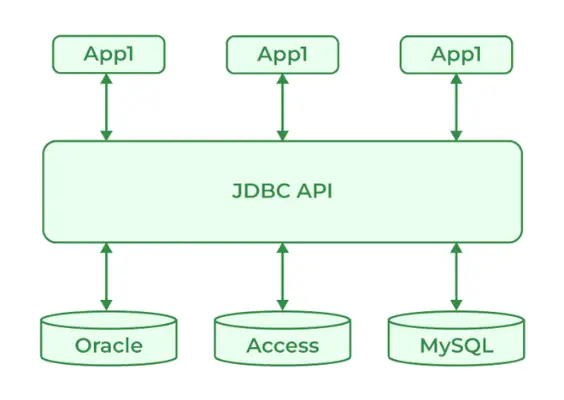
JDBC 표준 API는 Java 애플리케이션과 관계형 데이터베이스를 연결하는 데 사용됩니다. 프로그래머가 Java 프로그래밍 언어를 사용하여 데이터베이스와 통신할 수 있도록 하는 클래스 및 인터페이스 컬렉션을 제공합니다. JDBC의 클래스와 인터페이스를 통해 애플리케이션은 사용자가 지정한 데이터베이스에 요청을 보낼 수 있습니다. 일반적으로 데이터베이스와 상호 작용하는 JDBC 구성 요소는 네 가지입니다.
- JDBC API
- JDBC 드라이버 관리자
- JDBC 테스트 스위트
- JDBC-ODBC 브리지 드라이버
190. JDBC 드라이버란?
JDBC 드라이버 Java 애플리케이션이 데이터베이스와 상호 작용할 수 있도록 하는 데 사용되는 소프트웨어 구성 요소입니다. JDBC는 특정 데이터베이스 관리 시스템에 대한 JDBC API 구현을 제공하여 데이터베이스 연결, SQL 문 실행 및 데이터 검색을 허용합니다. JDBC 드라이버에는 네 가지 유형이 있습니다.
- JDBC-ODBC 브리지 드라이버
- 네이티브 API 드라이버
- 네트워크 프로토콜 드라이버
- 얇은 드라이버
191. Java에서 데이터베이스에 연결하는 단계는 무엇입니까?
아래에 언급된 대로 데이터베이스와 Java 프로그램을 연결하는 특정 단계가 있습니다.
- 패키지 가져오기
- forName() 메서드를 사용하여 드라이버 로드
- DriverManager를 사용하여 드라이버 등록
- Connection 클래스 객체를 사용하여 연결 설정
- 명세서 작성
- 쿼리 실행
- 연결을 닫으세요
192. JDBC API 구성 요소는 무엇입니까?
JDBC API 구성 요소는 데이터베이스와의 쉬운 통신을 위한 다양한 방법과 인터페이스를 제공하며 WORA(Write Once Run Anywhere) 기능을 제공하는 Java Se 및 Java EE와 같은 패키지도 제공합니다.
통사론:
java.sql.*;>
193. JDBC 연결 인터페이스란 무엇입니까?
JDBC(Java 데이터베이스 연결 인터페이스)는 Java 애플리케이션이 데이터베이스와 상호 작용할 수 있도록 하는 소프트웨어 구성 요소입니다. 연결을 향상시키기 위해 JDBC에는 각 데이터베이스에 대한 드라이버가 필요합니다.
194. JDBC ResultSet 인터페이스는 무엇입니까?
JDBC ResultSet 인터페이스는 데이터베이스의 데이터를 저장하고 이를 Java 프로그램에서 사용하는 데 사용됩니다. updateXXX() 메소드를 사용하여 데이터를 업데이트하기 위해 ResultSet을 사용할 수도 있습니다. ResultSet 객체는 결과 데이터의 첫 번째 행 앞에 커서를 가리킵니다. next() 메소드를 사용하여 ResultSet을 반복할 수 있습니다.
195. JDBC 행 집합이란 무엇입니까?
JDBC RowSet은 데이터를 표 형식으로 저장하는 방법을 제공합니다. RowSet은 java.sql 패키지 내에서 사용할 수 있는 Java의 인터페이스입니다. RowSet 객체와 데이터 소스 사이의 연결은 수명 주기 내내 유지됩니다. RowSet는 아래에 언급된 구현을 기반으로 다섯 가지 범주로 분류됩니다.
- JdbcRowSet
- 캐시된 행 집합
- 웹 행 집합
- 필터링된 행 집합
- JoinRowSet
196. JDBC DriverManager 클래스의 역할은 무엇입니까?
JDBC DriverManager 클래스는 사용자와 드라이버를 위한 인터페이스 역할을 합니다. 아래와 같이 다양하게 사용됩니다.
- Java 애플리케이션과 데이터베이스 간의 연결을 생성하는 데 사용됩니다.
- 사용 가능한 드라이버를 추적하는 데 도움이 됩니다.
- 데이터베이스와 해당 드라이버 간의 연결을 설정하는 데 도움이 될 수 있습니다.
- 여기에는 데이터베이스 드라이버 클래스를 등록 및 등록 취소할 수 있는 모든 메서드가 포함되어 있습니다.
- DriverManager.registerDriver() 메서드는 자신을 등록한 드라이버 클래스 목록을 유지할 수 있습니다.
Java 차이점 인터뷰 질문
197. Iterable과 Iterator를 구별하세요.
반복 가능 | 반복자 |
|---|---|
Iterable은 일련의 요소를 반복하는 방법을 제공합니다. | Iterator는 요소 컬렉션을 순차적으로 반복하는 데 도움이 됩니다. |
| 반복자() 메소드는 Iterator를 반환합니다. | 해즈다음() 그리고 다음() 방법이 필요합니다. |
| 제거하다() 방법은 선택 사항입니다. | 제거하다() 반복자에는 메서드가 필요합니다. |
예는 다음과 같습니다 목록, 대기열 및 설정. | 예는 다음과 같습니다 ListIterator, 열거형 및 ArrayIterator. |
198. 목록과 집합을 구별하세요.
목록 | 세트 |
|---|---|
주문하다 | 정렬되지 않은 |
목록은 중복을 허용합니다. | 세트는 중복된 값을 허용하지 않습니다. |
목록은 인덱스로 액세스됩니다. | 세트는 해시코드로 액세스됩니다. |
여러 개의 null 요소를 저장할 수 있습니다. | Null 요소는 한 번만 저장할 수 있습니다. |
예를 들면 ArrayList, LinkedList 등이 있습니다. | 예를 들면 HashSet 및 TreeSet이 있습니다. LinkedHashSet 등 |
199. 리스트와 맵을 구별하라.
목록 | 지도 |
|---|---|
목록 인터페이스는 중복 요소를 허용합니다. | 지도는 중복 요소를 허용하지 않습니다. |
목록은 삽입 순서를 유지합니다. | 지도는 삽입 순서를 유지하지 않습니다. |
여러 개의 null 요소를 저장할 수 있습니다. | 맵에서는 최대 단일 Null 키와 임의 개수의 Null 값을 허용합니다. |
목록은 지정된 인덱스에 있는 요소를 가져오는 get() 메서드를 제공합니다. | 맵은 지정된 인덱스의 요소를 가져오는 get 메소드를 제공하지 않습니다. |
List는 ArrayList 등으로 구현됩니다. | 지도는 HashMap, TreeMap, LinkedHashMap으로 구현됩니다. |
200. 큐와 스택을 구별하세요.
대기줄 | 스택 |
|---|---|
큐 데이터 구조는 요소를 저장하는 데 사용되며 큐의 뒤 또는 끝에서 큐에 넣기, 큐에서 빼기와 같은 작업을 수행하는 데 사용됩니다. | 스택 데이터 구조는 요소를 저장하는 데 사용되며 스택 상단에서 푸시, 팝과 같은 작업을 수행하는 데 사용됩니다. |
대기열 데이터 구조 FIFO 순서를 구현합니다. | 스택 데이터 구조 LIFO 순서를 구현합니다. |
대기열의 삽입과 삭제는 목록의 반대쪽 끝에서 발생합니다. 삭제는 목록의 앞부분에서 이루어지며, 삽입은 목록의 뒷부분에서 발생합니다. | 스택의 삽입과 삭제는 목록의 맨 위 끝에서만 발생합니다. |
삽입 작업을 대기열에 넣기 작업이라고 합니다. | 삽입 연산을 푸시 연산이라고 합니다. |
큐는 일반적으로 순차 처리와 관련된 문제를 해결하는 데 사용됩니다. | 스택은 일반적으로 재귀와 관련된 문제를 해결하는 데 사용됩니다. |
201. PriorityQueue와 TreeSet을 구별하세요.
우선순위 대기열 | 트리세트 |
|---|---|
Queue를 기본 데이터 구조로 사용합니다. | Set을 기본 데이터 구조로 사용합니다. |
이 데이터 구조는 중복 요소를 허용합니다. | 이 데이터 구조는 중복 요소를 허용하지 않습니다. |
우선순위 큐는 PriorityQueue 클래스에 의해 구현됩니다. | TreeSet은 TreeSet 클래스에 의해 구현됩니다. |
PriorityQueue는 JDK 1.5에 제공됩니다. | TreeSet은 JDK 1.4에 제공됩니다. |
PriorityQueue pq = new PriorityQueue(); | reeSet ts = new TreeSet(); |
202. 단일 연결 목록과 이중 연결 목록을 구별하세요.
단일 연결 목록 | 이중 연결리스트 |
|---|---|
단일 연결 목록에는 데이터와 링크라는 두 개의 세그먼트만 포함됩니다. | 이중 연결 목록에는 데이터라는 세 개의 세그먼트와 두 개의 포인터가 포함됩니다. |
단일 연결 리스트의 탐색은 순방향으로만 가능합니다. | 이중 연결 리스트의 순회는 순방향과 역방향 양방향으로만 가능합니다. |
모든 단일 노드에는 포인터가 하나만 있으므로 메모리를 덜 사용합니다. | 각 노드에 두 개의 포인터가 있으므로 단일 연결 목록보다 더 많은 메모리가 필요합니다. |
사용하기 쉽고 목록 시작 부분에 노드를 삽입합니다. | 사용하기가 약간 더 복잡하고 목록 끝에 삽입하기 쉽습니다. |
삽입과 삭제의 시간 복잡도는 O(n)입니다. | 삽입과 삭제의 시간복잡도는 O(1)이다. |
| | |


203. Failfast와 Failsafe를 구별하세요.
FailFast | 페일세이프 |
|---|---|
Failsfast는 반복 중에 동시 수정이 감지되면 즉시 실패합니다. | Failsafe는 계속해서 원본 컬렉션을 반복하고 수정할 복사본을 생성합니다. |
Failfast는 일반적으로 단일 스레드 환경에서 사용됩니다. | Failsafe는 다중 스레드 환경에서 사용됩니다. |
Failfast는 반복하는 동안 어떠한 수정도 허용하지 않습니다. | Failsafe는 반복 중에 수정을 허용합니다. |
Failfast는 컬렉션 복사를 포함하지 않으므로 안전 장치에 비해 빠릅니다. | Failsafe는 일반적으로 Failfast에 비해 속도가 느립니다. |
FailFast 던지기 ConcurrentModificationException 반복 중에 컬렉션이 수정된 경우. | FailSafe는 예외를 발생시키지 않지만 대신 반복할 컬렉션의 복사본을 만듭니다. |
204. HashMap과 TreeMap을 구별하세요.
해시맵 | 트리맵 |
|---|---|
Hasmap은 키-값 쌍을 저장하기 위해 해시 테이블을 사용합니다. | 트리맵은 레드-블랙 트리를 사용하여 키-값 쌍을 저장합니다. 문자열 토크나이저 자바 |
해시맵은 키-값 쌍의 특정 순서를 유지하지 않습니다. | 트리맵은 키를 기반으로 자연스러운 순서를 유지합니다. |
해시맵에서는 반복 순서가 보장되지 않습니다. | 반복은 키를 기준으로 정렬된 순서로 이루어집니다. |
해시맵은 트리맵에 비해 검색 속도가 더 빠릅니다. | 트리 맵 검색은 트리 순회를 사용하여 키를 찾기 때문에 속도가 느립니다. |
해시맵은 연결리스트 배열을 사용하여 구현됩니다. | TreeMap은 Red-black Tree를 사용하여 구현됩니다. |
Hashmap은 Object 클래스의 equals() 메서드를 사용하여 키를 비교합니다. | TreeMap은 CompareTo() 메서드를 사용하여 키를 비교합니다. |
205. 큐(Queue)와 데크(Deque)를 구별하세요.
대기줄 | 무엇에 대해서 |
|---|---|
큐는 요소 컬렉션을 저장하는 데 사용되는 선형 데이터 구조입니다. | Double-ended 큐라고도 알려진 Deque는 양쪽 끝에서 제거 및 추가하는 작업이 포함된 요소 컬렉션을 저장하는 선형 데이터 구조이기도 합니다. |
큐의 요소는 데이터 구조의 끝에만 삽입될 수 있습니다. | 데이터 구조의 양쪽 끝에서 요소를 삽입할 수 있습니다. |
Queue는 Array나 Linked List를 사용하여 구현할 수 있습니다. | 대기열 제거는 순환 배열 또는 이중 연결 목록을 사용하여 구현할 수 있습니다. |
대기열은 일반적으로 대기 목록 또는 작업 대기열을 구현하는 데 사용됩니다. | Deque는 양쪽 끝에서 스택을 구현하거나 요소를 큐에서 제거하는 데 사용됩니다. |
| | |
206. HashSet과 TreeSet을 구별하세요.
해시세트 | 트리세트 |
|---|---|
HashSet은 순서가 없습니다. | TreeSet은 자연 순서를 기반으로 합니다. |
HashSet은 null 요소를 허용합니다. | TreeSet은 null 요소를 허용하지 않습니다. |
HashSet은 HashSet 클래스에 의해 구현됩니다. | TreeSet은 TreeSet 클래스에 의해 구현됩니다. |
HashSet hs = 새로운 HashSet(); | TreeSet ts = 새로운 TreeSet(); |
Java 면접 질문 – FAQ
Q1. 인도에서 Java 개발자의 급여는 얼마입니까?
다양한 자료에 따르면 Java 백엔드 개발자의 평균 급여는 다른 개발자 역할보다 30% 높은 연간 14 lakhs . 여기에서 최신 강좌도 확인할 수 있습니다. GeekforGeeks 연습 포털 도움이 될 수도 있습니다.
Q5. Java 인터뷰에서 어떻게 눈에 띄나요?
Java 인터뷰에서 눈에 띄려면 Java 개념과 실제 애플리케이션에 대한 깊은 이해를 보여주세요. 복잡한 시나리오에 대한 접근 방식을 설명하고 효율적인 솔루션을 제공하여 문제 해결 능력을 보여주세요. 또한 관련 프로젝트나 Java 커뮤니티에 기여한 내용을 강조하세요. 열정, 원활한 의사소통, 배우려는 의지를 보여주는 것도 긍정적인 인상을 남길 수 있습니다.