우선순위 큐는 각 요소에 우선순위가 있다는 점을 제외하면 일반 큐와 유사하게 동작하는 추상 데이터 유형입니다. 즉, 우선순위가 가장 높은 요소가 우선순위 큐에서 첫 번째로 옵니다. 우선순위 큐에 있는 요소의 우선순위에 따라 우선순위 큐에서 요소가 제거되는 순서가 결정됩니다.
우선순위 큐는 비교 가능한 요소만 지원합니다. 즉, 요소가 오름차순 또는 내림차순으로 정렬됩니다.
자바 업데이트
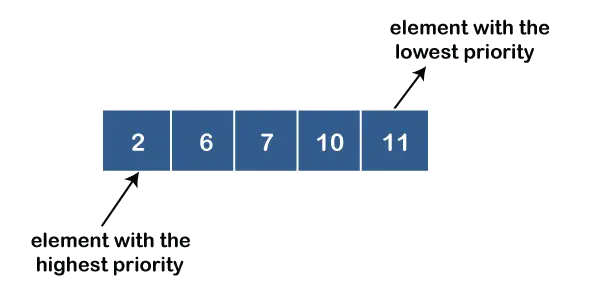
예를 들어, 1, 3, 4, 8, 14, 22와 같은 값이 우선순위 대기열에 삽입되어 있고 값에 순서가 적용되어 있다고 가정해 보겠습니다. 따라서 숫자 1이 가장 높은 우선순위를 갖고 22가 가장 낮은 우선순위를 갖습니다.
우선순위 큐의 특징
우선순위 큐는 다음 특성을 포함하는 큐의 확장입니다.
- 우선순위 큐의 모든 요소에는 이와 관련된 우선순위가 있습니다.
- 우선순위가 높은 요소는 낮은 우선순위를 삭제하기 전에 삭제됩니다.
- 우선순위 큐의 두 요소가 동일한 우선순위를 갖는 경우 FIFO 원칙을 사용하여 정렬됩니다.
예를 통해 우선순위 큐를 이해해보자.
다음 값을 포함하는 우선순위 대기열이 있습니다.
1, 3, 4, 8, 14, 22
모든 값은 오름차순으로 정렬됩니다. 이제 다음 작업을 수행한 후 우선순위 큐가 어떻게 보이는지 살펴보겠습니다.
우선순위 대기열의 유형
우선순위 큐에는 두 가지 유형이 있습니다.

우선순위 큐의 표현
이제 단방향 목록을 통해 우선순위 큐를 표현하는 방법을 살펴보겠습니다.
아래에 주어진 목록을 사용하여 우선순위 큐를 생성하겠습니다. 정보 목록에는 데이터 요소가 포함되어 있습니다. PRN 목록에는 사용 가능한 각 데이터 요소의 우선 순위 번호가 포함되어 있습니다. 정보 목록이며 LINK에는 기본적으로 다음 노드의 주소가 포함됩니다.

우선순위 큐를 단계별로 만들어 보겠습니다.
문자열 자바
우선순위 큐의 경우, 낮은 우선순위 번호가 더 높은 우선순위로 간주됩니다. 즉, 낮은 우선순위 번호 = 높은 우선순위.
1 단계: 목록에서 우선순위가 낮은 번호는 1이고 데이터 값은 333이므로 아래 그림과 같이 목록에 삽입됩니다.
2 단계: 333을 삽입한 후에는 우선순위 번호 2가 더 높은 우선순위를 가지며 이 우선순위와 관련된 데이터 값은 222와 111입니다. 따라서 이 데이터는 FIFO 원칙에 따라 삽입됩니다. 따라서 222가 먼저 추가된 다음 111이 추가됩니다.
3단계: 우선순위 2의 요소를 삽입한 후 다음으로 높은 우선순위 번호는 4이고 4개의 우선순위 번호와 연관된 데이터 요소는 444, 555, 777입니다. 이 경우 요소는 FIFO 원칙에 따라 삽입됩니다. 따라서 444가 먼저 추가되고 그 다음 555, 777이 추가됩니다.
4단계: 우선순위 4의 요소를 삽입한 후, 다음으로 높은 우선순위 번호는 5이고, 우선순위 5와 연관된 값은 666이므로 큐의 끝에 삽입됩니다.

우선순위 대기열 구현
우선순위 큐는 배열, 연결 리스트, 힙 데이터 구조, 이진 검색 트리 등 4가지 방식으로 구현될 수 있습니다. 힙 데이터 구조는 우선순위 큐를 구현하는 가장 효율적인 방법이므로 이 주제에서는 힙 데이터 구조를 사용하여 우선순위 큐를 구현하겠습니다. 이제 먼저 우리는 다른 모든 데이터 구조 중에서 힙이 가장 효율적인 방법인 이유를 이해합니다.
다양한 구현을 사용한 복잡성 분석
| 구현 | 추가하다 | 제거하다 | 몰래 엿보다 |
| 연결리스트 | 오(1) | 에) | 에) |
| 바이너리 힙 | 오(로그인) | 오(로그인) | 오(1) |
| 이진 검색 트리 | 오(로그인) | 오(로그인) | 오(1) |
힙이란 무엇입니까?
힙은 완전한 이진 트리를 형성하는 트리 기반 데이터 구조이며 힙 속성을 만족합니다. A가 B의 상위 노드인 경우 A는 힙의 모든 노드 A와 B에 대해 노드 B를 기준으로 정렬됩니다. 이는 상위 노드의 값이 하위 노드의 값보다 크거나 같을 수 있고, 상위 노드의 값이 하위 노드의 값보다 작거나 같을 수 있음을 의미합니다. 따라서 힙에는 두 가지 유형이 있다고 말할 수 있습니다.
배열 C 문자열


두 힙은 각각 정확히 두 개의 하위 노드를 갖기 때문에 이진 힙입니다.
우선순위 대기열 작업
우선순위 큐에서 수행할 수 있는 일반적인 작업은 삽입, 삭제 및 엿보기입니다. 힙 데이터 구조를 어떻게 유지 관리할 수 있는지 살펴보겠습니다.
우선순위 큐에 요소를 삽입하면 위에서 아래로, 왼쪽에서 오른쪽으로 살펴보며 빈 슬롯으로 이동합니다.
요소가 올바른 위치에 있지 않으면 상위 노드와 비교됩니다. 순서가 잘못된 것이 발견되면 요소가 교체됩니다. 이 과정은 요소가 올바른 위치에 배치될 때까지 계속됩니다.


우리가 알고 있듯이 최대 힙에서 최대 요소는 루트 노드입니다. 루트 노드를 제거하면 빈 슬롯이 생성됩니다. 마지막으로 삽입된 요소가 이 빈 슬롯에 추가됩니다. 그런 다음 이 요소는 자식 노드, 즉 왼쪽 자식 및 오른쪽 자식과 비교되어 둘 중 더 작은 노드와 교환됩니다. 힙 속성이 복원될 때까지 트리 아래로 계속 이동합니다.
우선순위 큐의 응용
우선순위 큐의 적용은 다음과 같습니다.
- Dijkstra의 최단 경로 알고리즘에 사용됩니다.
- prim의 알고리즘에 사용됩니다.
- 허프만 코드와 같은 데이터 압축 기술에 사용됩니다.
- 힙 정렬에 사용됩니다.
- 또한 우선순위 스케줄링, 로드 밸런싱, 인터럽트 처리와 같은 운영 체제에서도 사용됩니다.
바이너리 최대 힙을 사용하여 우선순위 큐를 생성하는 프로그램입니다.
#include #include int heap[40]; int size=-1; // retrieving the parent node of the child node int parent(int i) { return (i - 1) / 2; } // retrieving the left child of the parent node. int left_child(int i) { return i+1; } // retrieving the right child of the parent int right_child(int i) { return i+2; } // Returning the element having the highest priority int get_Max() { return heap[0]; } //Returning the element having the minimum priority int get_Min() { return heap[size]; } // function to move the node up the tree in order to restore the heap property. void moveUp(int i) { while (i > 0) { // swapping parent node with a child node if(heap[parent(i)] <heap[i]) 2 { int temp; temp="heap[parent(i)];" heap[parent(i)]="heap[i];" heap[i]="temp;" } updating the value of i to function move node down tree in order restore heap property. void movedown(int k) index="k;" getting location left child if (left heap[index]) right (right k is not equal (k !="index)" heap[index]="heap[k];" heap[k]="temp;" movedown(index); removing element maximum priority removemax() r="heap[0];" heap[0]="heap[size];" size="size-1;" movedown(0); inserting a queue insert(int p) + 1; heap[size]="p;" up maintain property moveup(size); from at given i. delete(int i) stored ith shifted root moveup(i); having removemax(); main() elements insert(20); insert(19); insert(21); insert(18); insert(12); insert(17); insert(15); insert(16); insert(14); printf('elements are : '); for(int printf('%d ',heap[i]); delete(2); deleting whose 2. printf('
elements after max="get_Max();" printf('
the which highest %d: ',max); min="get_Min();" minimum %d',min); return 0; < pre> <p> <strong>In the above program, we have created the following functions:</strong> </p> <ul> <tr><td>int parent(int i):</td> This function returns the index of the parent node of a child node, i.e., i. </tr><tr><td>int left_child(int i):</td> This function returns the index of the left child of a given index, i.e., i. </tr><tr><td>int right_child(int i):</td> This function returns the index of the right child of a given index, i.e., i. </tr><tr><td>void moveUp(int i):</td> This function will keep moving the node up the tree until the heap property is restored. </tr><tr><td>void moveDown(int i):</td> This function will keep moving the node down the tree until the heap property is restored. </tr><tr><td>void removeMax():</td> This function removes the element which is having the highest priority. </tr><tr><td>void insert(int p):</td> It inserts the element in a priority queue which is passed as an argument in a function <strong>.</strong> </tr><tr><td>void delete(int i):</td> It deletes the element from a priority queue at a given index. </tr><tr><td>int get_Max():</td> It returns the element which is having the highest priority, and we know that in max heap, the root node contains the element which has the largest value, and highest priority. </tr><tr><td>int get_Min():</td> It returns the element which is having the minimum priority, and we know that in max heap, the last node contains the element which has the smallest value, and lowest priority. </tr></ul> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/03/what-is-priority-queue-9.webp" alt="Priority Queue"> <hr></heap[i])>