표준 편차 통계의 분산을 측정하는 것입니다. 표준 편차 공식은 평균값에서 데이터 값의 편차를 찾는 데 사용됩니다. 즉, 데이터 세트의 모든 값이 평균값으로 분산되는 것을 찾는 데 사용됩니다. 랜덤 변수의 표준 편차를 계산하는 다양한 표준 편차 공식이 있습니다.
이 기사에서는 다음에 대해 알아볼 것입니다. 표준편차란 무엇인지, 표준편차 공식은 무엇인지, 표준편차는 어떻게 계산하는지, 표준편차의 예는 무엇인지 자세히 알아보세요.
내용의 테이블
- 표준편차란 무엇입니까?
- 표준편차 공식
- 표준편차를 계산하는 방법은 무엇입니까?
- 분산이란 무엇입니까?
- 분산 공식
- 차이를 계산하는 방법?
- 그룹화되지 않은 데이터의 표준 편차
- 이산 그룹화된 데이터의 표준 편차
- 연속적으로 그룹화된 데이터의 표준편차
- 확률분포의 표준편차
- 무작위 변수의 표준편차
- 표준편차 공식 엑셀
- 표준편차 공식 통계
표준편차란 무엇입니까?
표준편차는 데이터 포인트의 평균값에 대한 데이터 포인트의 분산 정도로 정의됩니다. 이는 데이터 포인트의 값이 데이터 포인트의 평균값에 따라 어떻게 변하는지 알려주고 데이터 샘플에서 데이터 포인트의 변화에 대해 알려줍니다.
주어진 데이터 세트 샘플의 표준 편차는 다음의 제곱근으로도 정의됩니다. 변화 데이터 세트의. 평균 편차 n개의 값 중(예: x1, x2, x삼, …, 엑스N)는 평균과 각 값의 차이의 제곱의 합을 취하여 계산됩니다.
평균 편차 = 1/n∑ 나 N (엑스 나 – x̄) 2
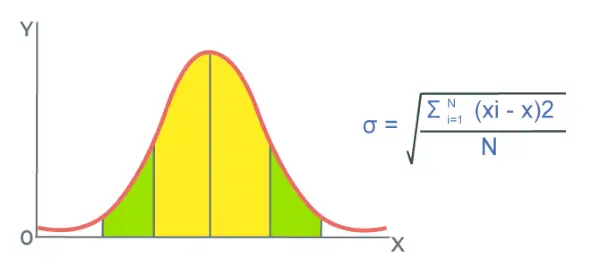
평균 편차는 데이터의 분산을 알려주는 데 사용됩니다. 편차의 정도가 낮을수록 관측치 xi가 평균값에 가깝고 우울증이 낮다는 것을 알 수 있으며, 편차의 정도가 높을수록 관측치 xi가 평균값에서 멀고 분산이 높다는 것을 알 수 있습니다.
문자열 찾기 C++
표준편차 정의
표준편차는 세트의 데이터 포인트가 전체에서 어떻게 분산되어 있는지 이해하기 위해 통계에서 사용되는 척도입니다. 평균 값. 이는 데이터의 변동 정도를 나타내며 개별 데이터 포인트가 평균에서 얼마나 벗어나는지를 보여줍니다.
확인하다: 통계에서 표준편차를 찾는 방법은 무엇입니까?
표준편차 공식
표준편차는 통계 데이터의 확산을 측정하는 데 사용됩니다. 통계 데이터가 어떻게 퍼져 있는지 알려줍니다. 표준편차를 계산하는 공식 평균 위치에서 모든 데이터 세트의 편차를 찾는 데 사용됩니다. 표준편차를 계산하는 방법이나 방법에 대해 질문이 있을 수 있습니다. 표준편차를 계산하는 방법 . 주어진 데이터 세트의 표준 편차를 찾는 데 사용되는 두 가지 표준 편차 공식이 있습니다. 그들은,
- 모집단 표준편차 공식
- 표준편차 공식 샘플
어디,
- s는 인구 표준 편차입니다.
- 엑스 나 나는인가? 일 관찰
- x̄는 표본 평균입니다.
- N은 관찰 횟수입니다.
어디,
- σ는 모집단 표준편차
- 엑스나나는인가?일관찰
- μ는 모집단 평균입니다.
- N은 관찰 횟수입니다.
두 수식 모두 동일하게 보이고 분모에 슬라이드 변경 사항만 있다는 점은 분명합니다. 표본의 경우 분모는 다음과 같습니다. n-1 하지만 다음의 경우 인구는 N이다. 처음에 분모는 표본 표준편차 공식에는 N 분모에 있지만 이 공식의 결과는 적절하지 않습니다. 그래서 수정을 했고, n을 n-1로 대체하는 보정을 베셀 보정(Bessel’s Correction)이라고 합니다. 결과적으로 가장 적절한 결과가 나왔습니다.
더 읽어보기: 분산과 표준편차의 차이
표준편차 계산 공식
표준편차를 계산하는 데 사용되는 공식은 아래 이미지에서 설명합니다.

표준편차를 계산하는 방법은 무엇입니까?
일반적으로 표준편차에 관해 이야기할 때 모집단 표준편차 . 주어진 값 세트의 표준 편차를 계산하는 단계는 다음과 같습니다.
1 단계: 공식을 사용하여 관찰 평균을 계산합니다.
(평균 = 관측치 합계/관찰치 수)
2 단계: 평균과 데이터 값의 차이 제곱을 계산합니다.
(데이터 값 - 평균)2
3단계: 제곱 차이의 평균을 계산합니다.
(분산 = 차이 제곱의 합 / 관측치 수)
4단계: 분산의 제곱근을 계산하여 표준 편차를 얻습니다.
(표준편차 = √분산)
분산이란 무엇입니까?
분산은 기본적으로 데이터 세트가 얼마나 퍼져 있는지 알려줍니다. 모든 데이터 포인트가 동일하면 분산은 0입니다. 0이 아닌 분산은 양수로 간주됩니다. . 낮은 분산은 데이터 포인트가 평균(또는 평균)에 가깝고 서로 가깝다는 것을 의미합니다. 높은 분산은 데이터 포인트가 평균과 서로 분산되어 있음을 의미합니다. 간단히 말해서, 분산은 각 데이터 포인트가 평균에서 얼마나 떨어져 있는지를 제곱한 평균입니다.
분산과 편차의 차이점
| 측면 | 변화 | 편차(표준편차) |
|---|---|---|
| 정의 | 데이터세트의 확산 정도를 측정합니다. | 평균으로부터의 평균 거리를 측정합니다. |
| 계산 | 평균과의 차이 제곱의 평균입니다. | 분산의 제곱근입니다. |
| 상징 | σ^2(시그마 제곱) | σ(시그마) |
| 해석 | 평균에서 데이터 포인트의 평균 제곱 편차를 나타냅니다. | 평균으로부터 데이터 포인트의 평균 거리를 나타냅니다. |
확인하다:
- 분산과 표준편차의 차이
- 평균, 분산, 표준편차
분산 공식
데이터 세트의 분산을 계산하는 공식은 다음과 같습니다.
분산(σ^2) = Σ [(x – μ)^2] / N
어디:
- Σ는 합계(합산)를 나타냅니다.
- x는 각 개별 데이터 포인트를 나타냅니다.
- μ(mu)는 데이터 세트의 평균(평균)입니다.
- N은 총 데이터 포인트 수입니다.
차이를 계산하는 방법?
데이터 세트의 분산을 계산하는 단계:
1 단계: 평균(평균)을 계산합니다.
데이터 세트의 모든 값을 더하고 총 값 수로 나눕니다. 이는 평균(μ)을 제공합니다.
평균(μ) = (모든 값의 합) / (총 값 수)
2단계: 평균과의 차이 제곱 구하기:
데이터 세트의 각 값에 대해 해당 값에서 첫 번째 단계에서 계산된 평균을 뺀 다음 결과를 제곱합니다. 이렇게 하면 각 값의 차이 제곱이 제공됩니다.
각 값의 차이 제곱 = (값 – 평균)^2
3단계: 차이 제곱의 평균 계산:
이전 단계에서 계산된 차이의 제곱을 모두 더한 다음 데이터 세트의 총 값 수로 나눕니다. 이는 분산(σ^2)을 제공합니다.
분산(σ^2) = (모든 제곱 차이의 합) / (총 값 수)
확인하다: 분산 및 표준편차
그룹화되지 않은 데이터의 표준 편차
가정된 평균 방법
실제 평균 방법에 따른 표준 편차
실제 평균 방법에 의한 표준 편차는 기본 평균 공식을 사용하여 주어진 데이터의 평균을 계산합니다. 그리고 이 평균값을 사용하여 주어진 데이터 값의 표준편차를 알아냅니다. 이 방법의 평균은 다음 공식을 사용하여 계산됩니다.
μ = (관찰의 합)/(관찰의 수)
그리고 그런 다음 표준 편차 공식을 사용하여 표준 편차를 계산합니다.
σ = √(∑ 나 N (엑스 나 – x̄) 2 /N)
예: 데이터 세트의 표준편차를 찾습니다. 엑스 = {2, 3, 4, 5, 6}
해결책:
주어진,
- n = 5
- 엑스나= {2, 3, 4, 5, 6}
우린 알아,
평균(μ) = (관측치의 합)/(관찰치 수)
⇒ μ = (2 + 3 + 4 + 5 + 6)/ 5
⇒ μ = 4
피2= ∑나N(엑스나– x̄)2/N
⇒ 피2= 1/n[(2 – 4)2+ (3 – 4)2+ (4 – 4)2+ (5 – 4)2+ (6 – 4)2]
⇒ 피2= 10/5 = 2
따라서 σ = √(2) = 1.414
가정 평균 방법에 따른 표준 편차
매우 큰 x 값의 경우 그룹화된 데이터의 평균을 찾는 것은 지루한 작업이므로 임의의 값(A)을 평균값으로 가정한 다음 정규 방법을 사용하여 표준 편차를 계산했습니다. n개의 데이터 값 그룹( x1, x2, x삼, …, 엑스N), 가정된 평균은 A이고 편차는 다음과 같습니다.
디 나 = x 나 - ㅏ
지금, 가정된 평균 공식은 다음과 같습니다.
σ = √(∑ 나 N (디 나 ) 2 /N)
단계편차법에 의한 표준편차
단계편차법을 사용하여 그룹화된 데이터의 표준편차를 계산할 수도 있습니다. 이 방법의 위 방법과 마찬가지로 임의의 데이터 값을 가정된 평균(예: A)으로 선택합니다. 그런 다음 모든 데이터 값의 편차를 계산합니다(x 1 , x 2 , x 삼 , …, 엑스 N ), 디 나 = x 나 - ㅏ
다음 단계에서는 다음을 사용하여 단계 편차(d')를 계산합니다.
d' = d/i
어디 ' 나 '는 모든 'd' 값의 공통 인수입니다.
그 다음에, 표준편차 공식은,
σ = √[(∑(d') 2 /n) – (∑d'n) 2 ] × 나는
어디 ' N '는 데이터 값의 총 개수입니다.
이산 그룹화된 데이터의 표준 편차
먼저 그룹화된 데이터에서 빈도표를 만든 다음 추가 계산을 수행했습니다. 이산 그룹화된 데이터의 경우 표준 편차는 다음 세 가지 방법을 사용하여 계산할 수도 있습니다.
- 실제 평균 방법
- 가정된 평균 방법
- 단계 편차 방법
이산 주파수 분포를 기반으로 한 표준 편차 공식
주어진 데이터 세트에 n개의 값이 있는 경우(x1, x2, x삼, …, 엑스N) 그리고 이에 해당하는 주파수는 (f1, 에프2, 에프삼, ..., 에프N) 표준 편차는 공식을 사용하여 계산됩니다.
σ = √(∑ 나 N 에프 나 (엑스 나 – x̄) 2 /N)
어디,
- N 총 빈도(n = f1+ 에프2+ 에프삼+...+ 에프N)
- 엑스 데이터의 평균입니다
예: 주어진 데이터에 대한 표준 편차 계산
엑스나 | 에프나 |
|---|---|
| 10 | 1 |
| 4 | 삼 |
| 6 | 5 |
| 8 | 1 |
해결책:
평균(x̄) = ∑(f나엑스나)/∑(f나)
⇒ 평균(μ) = (10×1 + 4×3 + 6×5 + 8×1)/(1+3+5+1)
⇒ 평균(μ) = 60/10 = 6
n = ∑(f나) = 1+3+5+1 = 10
| 엑스나 | 에프나 | 에프나엑스나 | (엑스나– x̄) | (엑스나– x̄)2 | 에프나(엑스나– x̄)2 |
|---|---|---|---|---|---|
| 10 | 1 | 10 | 4 | 16 | 16 |
| 4 | 삼 | 12 | -2 | 4 | 12 |
| 6 | 5 | 30 | 0 | 0 | 0 |
| 8 | 1 | 8 | 2 | 4 | 8 |
지금,
σ = √(∑ 나 N 에프 나 (엑스 나 – x̄) 2 /N)
⇒ σ = √[(16 + 12 + 0 +8)/10]
⇒ σ = √(3.6) = 1.897
표준유도(σ) = 1.897
디 나 = x 나 - ㅏ
이제 가정된 평균 방법에 의한 표준 편차 공식은 다음과 같습니다.
σ = √[(∑(f 나 디 나 ) 2 /n) – (∑f 나 디 나 /N) 2 ]
어디,
- ' 에프 '는 데이터 값의 빈도 x입니다.
- ' N '는 총 빈도입니다 [n = ∑(f 나 )]
다음 단계에서는 다음을 사용하여 단계 편차(d')를 계산합니다.
d' = d/i
어디 ' 나 '는 모든 '의 공통인수입니다. 디 ' 가치
그 다음에, 표준편차 공식은,
σ = √[(∑(fd') 2 /n) - (�'/n) 2 ] × 나
어디 ' N '는 데이터 값의 총 개수입니다.
연속적으로 그룹화된 데이터의 표준편차
연속적으로 그룹화된 데이터의 경우 각 클래스를 중간점(x와 같이)으로 대체하여 이산 데이터 공식을 사용하여 표준 편차를 쉽게 계산할 수 있습니다.나) 그런 다음 일반적으로 수식을 계산합니다.
각 클래스의 중간점은 다음 공식을 사용하여 계산됩니다.
엑스 나 (중간점) = (상한 + 하한)/2
예를 들어, 표에 주어진 연속 그룹 데이터의 표준편차를 계산합니다.
| 수업 | 0-10 | 10-20 | 20-30 | 30-40 |
|---|---|---|---|---|
주파수(f나) | 2 | 4 | 2 | 2 |
실제 평균 방법
- 가정된 평균 방법
- 단계 편차 방법
위의 방법 중 하나를 사용하여 표준 편차를 찾을 수 있습니다. 여기서는 실제 평균 방법을 사용하여 표준 편차를 찾습니다.
위 질문에 대한 해결책은,
| 수업 | 5-15 | 15-25 | 25-35 | 35-45 |
|---|---|---|---|---|
| 엑스나 | 10 | 이십 | 30 | 40 |
주파수(f나) | 2 | 4 | 2 | 2 |
평균(x̄) = ∑(f나엑스나)/∑(f나)
⇒ 평균(μ) = (10×2 + 20×4 + 30×2 + 40×2)/(2+4+2+2)
⇒ 평균(μ) = 240/10 = 24
n = ∑(f나) = 2+4+2+2 = 10
| 엑스나 | 에프나 | 에프나엑스나 | (엑스나– x̄) | (엑스나– x̄)2 | 에프나(엑스나– x̄)2 |
|---|---|---|---|---|---|
| 10 | 2 | 이십 | 14 | 196 | 392 |
| 이십 | 4 | 80 | -4 | 16 | 64 |
| 30 | 2 | 60 | 6 | 36 | 72 |
| 40 | 2 | 80 | 16 | 256 | 512 |
지금,
σ = √(∑ 나 N 에프 나 (엑스 나 – x̄) 2 /N)
⇒ σ = √[(392 + 64 + 72 +512)/10]
⇒ σ = √(104) = 10,198
표준유도(σ) = 10,198
마찬가지로, 연속적으로 그룹화된 데이터의 표준 편차를 찾는 데 다른 방법을 사용할 수도 있습니다.
확인하다: 개별 계열의 표준 편차
확률분포의 표준편차
가능한 모든 결과의 확률은 일반적으로 동일하며 주어진 실험의 실험 확률을 찾기 위해 많은 시도를 합니다.
- 정규 분포의 경우 평균 예상 평균은 0이고 표준 편차는 1입니다.
- 이항 분포의 경우 표준 편차는 다음 공식으로 제공됩니다.
σ = √(npq)
어디,
- N 시도 횟수입니다
- 피 재판의 성공 확률이다
- 큐 시행 실패 확률(q = 1 – p)
- 포아송 분포의 경우 표준편차는 다음과 같이 계산됩니다.
σ = √λt
어디,
- 엘 평균 성공 횟수
- 티 주어진 시간 간격
무작위 변수의 표준편차
무작위 변수 는 표본 공간에서 무작위 실험의 가능한 결과를 나타내는 숫자 값입니다. 확률변수의 표준편차를 계산하면 확률변수의 확률분포와 기대값과의 차이 정도를 알 수 있습니다.
우리는 사용 X, Y, Z는 확률 변수를 나타내는 함수입니다. 확률변수의 확률은 P(X)로 표시되고 기대값은 μ 기호로 표시됩니다.
그런 다음 확률 분포의 표준 편차는 공식을 사용하여 제공됩니다.
σ = √(∑ (x 나 - 중) 2 ×P(X)/n)
Java에서 문자열을 int로 변환하는 방법
더 읽어보기,
- 평균
- 방법
- 평균 편차
표준편차 공식 예
예시 1: 다음 데이터의 표준편차를 구합니다.
엑스나 | 5 | 12 | 열 다섯 |
|---|---|---|---|
에프나 | 2 | 4 | 삼 |
해결책:
먼저 다음과 같이 표를 작성하면 추가 값을 쉽게 계산할 수 있습니다.
엑스나 | 에프나 | 엑스나×f나 | 엑스나- 중 | (시-μ)2 | f×(엑스나-중)2 |
|---|---|---|---|---|---|
5 | 2 | 10 | -6,375 | 40.64 | 81.28 |
12 | 삼 | 36 | 0.625 | 0.39 | 1.17 |
열 다섯 | 삼 | 넷 다섯 | 3,625 | 13.14 | 39.42 |
총 | 8 | 91 |
|
| 121.87 |
평균(μ) = ∑(f 나 엑스 나 )/∑(f 나 )
⇒ 평균(μ) = 91/8 = 11.375
σ = √(∑ 나 N 에프 나 (엑스 나 - 중) 2 /N)
⇒ σ = √[(121.87)/(8)]
⇒ σ = √(15.234)
⇒ σ = 3.90
표준유도(σ) = 3.90
해결책:
수업 | 시 | 에프나 | 에프×시 | 사이 – μ | (사이 – μ)2 | f×(엑스나- 중)2 |
|---|---|---|---|---|---|---|
0-10 | 5 | 삼 | 열 다섯 | -열 다섯 | 225 단어 빠른 액세스 도구 모음 | 675 |
10-20 | 열 다섯 | 6 | 90 | -5 | 25 | 150 |
20-30 | 25 | 4 | 100 | 5 | 25 | 100 |
30-40 | 35 | 2 | 70 | 열 다섯 | 225 | 450 |
40-50 | 넷 다섯 | 1 | 넷 다섯 | 25 | 625 | 625 |
총 |
| 16 | 320 |
|
| 2000 |
평균(μ) = ∑(fi xi)/∑(fi)
⇒ 평균(μ) = 320/16 = 20
σ = √(∑ 나 N 에프 나 (엑스 나 - 중) 2 /N)
⇒ σ = √[(2000)/(16)]
⇒ σ = √(125)
⇒ σ = 11.18
표준유도(σ) = 11.18
확인하다: 이산 계열의 표준 편차 계산 방법
포괄적인 컬렉션을 위해서는 수학 공식 다양한 학년 수준과 개념에 걸쳐 techcodeview.com를 계속 따르세요.
또한 다음을 확인하세요.
- 평균, 중앙값, 모드
- 중심 경향
표준편차 공식 엑셀
- 간편한 계산: Excel에 내장된 기능을 사용하세요.
STDEV.P>전체 인구에 대해 또는STDEV.S>샘플을 위해. - 단계별 가이드: 단일 열에 데이터 세트를 입력한 다음 다음을 입력하세요.
=STDEV.S(A1:A10)>(A1:A10을 데이터 범위로 대체)을 새 셀에 추가하여 샘플의 표준 편차를 구합니다. - 시각 자료: Excel의 차트 도구를 활용하여 표준 편차와 함께 데이터 변동성을 시각적으로 표현합니다.
확인하다: 도수분포 계열의 표준편차 계산 방법
표준편차 공식 통계
- 핵심 개념: 표준 편차는 일련의 값의 변동 또는 분산 정도를 측정합니다.
- 주요 통찰력: 낮은 표준 편차는 값이 평균에 가까운 경향이 있음을 나타내고, 높은 표준 편차는 값이 더 넓은 범위에 분산되어 있음을 나타냅니다.
- 통계적 유의성: 특히 가설 검정 및 실험 데이터 분석에서 그룹 간의 차이가 우연에 의한 것인지 확인하는 데 사용됩니다.
결론 - 표준편차
표준 편차는 데이터 세트 내의 변동성 또는 일관성에 대한 귀중한 정보를 제공합니다. 이는 통계, 금융, 과학 등 다양한 분야에서 데이터의 분포를 이해하고 존재하는 변동성 수준에 따라 정보에 입각한 결정을 내리는 데 널리 사용됩니다.
표준편차에 대한 FAQ
통계의 표준편차란 무엇입니까?
표준 편차는 주어진 데이터 세트의 평균값과 관련하여 데이터 값의 변동성을 정의합니다. 이는 편차 평균의 제곱의 제곱근으로 정의됩니다.
표준편차를 계산하는 방법은 무엇입니까?
표준편차는 공식을 사용하여 계산됩니다.
σ =
표준편차가 사용되는 이유는 무엇입니까? 표준편차는 다양한 목적으로 사용됩니다. 중요한 용도 중 일부는 다음과 같습니다.
- 평균값에 대한 데이터 값의 변동성을 찾는 데 사용됩니다.
- 데이터의 편차 범위를 찾는 데 사용됩니다.
- 이는 데이터 세트의 주어진 값에서 최대 변동성을 예측합니다.
표준편차와 분산의 차이점은 무엇입니까?
분산은 평균에서 제곱된 편차의 평균을 취하여 계산되는 반면, 표준편차는 분산의 제곱근입니다. 그들 사이의 다른 차이점은 단위에 있습니다. 표준편차는 원래 값과 같은 단위로 표현되고, 분산은 단위로 표현됩니다.2.
실제 평균 방법
가정된 평균 방법 단계 편차 방법 표준편차가 음수가 될 수 있나요?
아니요, 표준편차는 결코 음수가 될 수 없습니다. 공식에서 음수가 될 수 있는 모든 항은 제곱된 것을 볼 수 있습니다.
예제를 통해 표준편차를 설명하면 무엇인가요?
표준 편차는 데이터 세트의 주어진 값의 변동 또는 분산을 측정한 것입니다.
예: 1, 2, 3, 4의 평균을 구하려면
데이터 평균 = 13/4 = 3.25
표준편차 = √[(3.25-1)2 + (3-3.25)2 + (4-3.25)2 + (5-3.25)2]/4 = √2.06 = 1.43
표준편차 공식은 무엇입니까?
표준편차 공식은,
표준편차(σ) = √[ Σ(x – μ) 2 / N]
표준편차가 1일 때?
1과 평균 0을 갖는 표준편차를 표준정규분포라고 합니다.
처음 10개 자연수의 표준편차란 무엇입니까?
처음 10개 자연수의 표준편차는 2.87입니다.
40, 42, 48의 표준편차란 무엇입니까?
40, 42, 48의 표준편차는 3.399입니다.
표준편차는 무엇을 말해주는가?
표준편차는 정규분포의 확산 정도를 측정한 것입니다. 표준편차는 데이터 세트의 평균값을 중심으로 데이터 세트가 퍼져 있음을 나타냅니다.