BFS와 DFS의 차이점을 살펴보기 전에 먼저 BFS와 DFS에 대해 별도로 알아야 합니다.
BFS란 무엇입니까?
BFS 약자 너비 우선 검색 . 그것은 또한로 알려져 있습니다 레벨 순서 순회 . Queue 데이터 구조는 너비 우선 검색 순회에 사용됩니다. 그래프의 순회에 BFS 알고리즘을 사용하면 모든 노드를 루트 노드로 간주할 수 있습니다.
너비 우선 검색 순회에 대한 아래 그래프를 고려해 보겠습니다.
아나콘다 대 파이썬 뱀
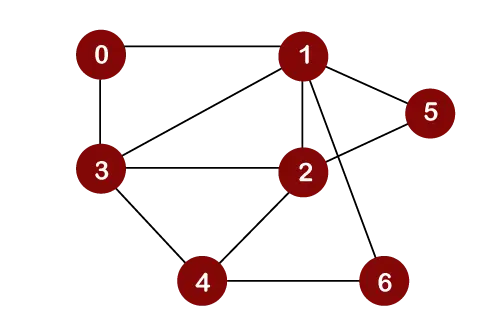
노드 0을 루트 노드로 간주한다고 가정합니다. 따라서 횡단은 노드 0부터 시작됩니다.

노드 0이 대기열에서 제거되면 인쇄되어 다음으로 표시됩니다. 노드를 방문했습니다.
노드 0이 대기열에서 제거되면 노드 0의 인접한 노드가 아래와 같이 대기열에 삽입됩니다.

이제 노드 1이 대기열에서 제거됩니다. 인쇄되어 방문한 노드로 표시됩니다.
노드 1이 대기열에서 제거되면 노드 1의 모든 인접한 노드가 대기열에 추가됩니다. 노드 1의 인접 노드는 0, 3, 2, 6, 5입니다. 하지만 Queue에는 방문하지 않은 노드만 삽입해야 합니다. 노드 3, 2, 6, 5는 방문되지 않았으므로; 따라서 이러한 노드는 아래와 같이 대기열에 추가됩니다.

다음 노드는 대기열의 3입니다. 따라서 노드 3은 대기열에서 제거되고 아래와 같이 인쇄되고 방문한 것으로 표시됩니다.

노드 3이 대기열에서 제거되면 방문한 노드를 제외한 노드 3의 모든 인접 노드가 대기열에 추가됩니다. 노드 3의 인접 노드는 0, 1, 2, 4입니다. 노드 0, 1은 이미 방문되었고 노드 2는 대기열에 존재하므로; 따라서 대기열에 노드 4만 삽입해야 합니다.
HTML 태그

이제 대기열의 다음 노드는 2입니다. 따라서 대기열에서 2가 삭제됩니다. 아래와 같이 인쇄되어 방문한 것으로 표시됩니다.

노드 2가 대기열에서 제거되면 방문한 노드를 제외한 노드 2의 모든 인접 노드가 대기열에 추가됩니다. 노드 2의 인접 노드는 1, 3, 5, 6, 4이다. 노드 1과 3은 이미 방문한 적이 있고, 4, 5, 6은 이미 큐에 추가되어 있으므로; 따라서 대기열에 노드를 삽입할 필요가 없습니다.
다음 요소는 5입니다. 따라서 대기열에서 5가 삭제됩니다. 아래와 같이 인쇄되어 방문한 것으로 표시됩니다.

노드 5가 대기열에서 제거되면 방문한 노드를 제외한 노드 5의 모든 인접 노드가 대기열에 추가됩니다. 노드 5의 인접 노드는 1과 2입니다. 두 노드 모두 이미 방문되었으므로; 따라서 대기열에 삽입할 정점이 없습니다.
다음 노드는 6입니다. 따라서 대기열에서 6이 삭제됩니다. 아래와 같이 인쇄되어 방문한 것으로 표시됩니다.

노드 6이 대기열에서 제거되면 방문한 노드를 제외한 노드 6의 모든 인접 노드가 대기열에 추가됩니다. 노드 6의 인접 노드는 1과 4입니다. 노드 1은 이미 방문한 적이 있고 노드 4는 이미 대기열에 추가되어 있으므로; 따라서 대기열에 삽입할 정점이 없습니다.
CSS 테두리
대기열의 다음 요소는 4입니다. 따라서 대기열에서 4가 삭제됩니다. 인쇄되어 방문한 것으로 표시됩니다.
노드 4가 대기열에서 제거되면 방문한 노드를 제외한 노드 4의 모든 인접 노드가 대기열에 추가됩니다. 노드 4의 인접 노드는 3, 2, 6입니다. 모든 인접 노드는 이미 방문되었으므로; 따라서 대기열에 삽입할 정점이 없습니다.
DFS란 무엇입니까?
DFS 깊이 우선 탐색을 의미합니다. DFS 탐색에서는 LIFO(Last In First Out) 원칙에 따라 작동하는 스택 데이터 구조가 사용됩니다. DFS에서는 모든 노드에서 순회가 시작될 수 있으며, 문제에서 루트 노드가 언급되지 않을 때까지 모든 노드가 루트 노드로 간주될 수 있다고 말할 수 있습니다.
BFS의 경우 Queue에서 삭제된 요소, 삭제된 노드의 인접 노드가 Queue에 추가됩니다. 반면, DFS에서는 스택에서 제거된 요소가 삭제된 노드의 인접한 노드 하나만 스택에 추가됩니다.
깊이 우선 검색 순회에 대한 아래 그래프를 고려해 보겠습니다.

노드 0을 루트 노드로 간주합니다.
먼저 아래와 같이 스택에 요소 0을 삽입합니다.

노드 0에는 두 개의 인접한 노드, 즉 1과 3이 있습니다. 이제 순회를 위해 하나의 인접한 노드(1 또는 3)만 사용할 수 있습니다. 노드 1을 고려한다고 가정합니다. 따라서 1이 스택에 삽입되고 아래와 같이 인쇄됩니다.

이제 노드 1의 인접 정점을 살펴보겠습니다. 노드 1의 방문하지 않은 인접 정점은 3, 2, 5, 6입니다. 우리는 이 4개의 정점 중 하나를 고려할 수 있습니다. 아래와 같이 노드 3을 가져와 스택에 삽입한다고 가정합니다.

노드 3의 방문하지 않은 인접 정점을 고려하십시오. 노드 3의 방문하지 않은 인접 정점은 2와 4입니다. 정점, 즉 2 또는 4 중 하나를 사용할 수 있습니다. 정점 2를 가져와 아래와 같이 스택에 삽입한다고 가정합니다.
스프링 부트

노드 2의 방문하지 않은 인접 정점은 5와 4입니다. 정점 중 하나, 즉 5 또는 4를 선택할 수 있습니다. 정점 4를 가져와 아래와 같이 스택에 삽입한다고 가정합니다.

이제 우리는 노드 4의 방문하지 않은 인접 정점을 고려할 것입니다. 노드 4의 방문하지 않은 인접 정점은 노드 6입니다. 따라서 요소 6은 아래와 같이 스택에 삽입됩니다.

스택에 요소 6을 삽입한 후 노드 6의 방문하지 않은 인접 정점을 살펴보겠습니다. 노드 6에는 방문하지 않은 인접 정점이 없으므로 노드 6을 넘어 이동할 수 없습니다. 이 경우 다음을 수행합니다. 역추적 . 최상위 요소, 즉 6은 아래와 같이 스택에서 팝아웃됩니다.


스택의 최상위 요소는 4입니다. 노드 4의 왼쪽에는 방문하지 않은 인접 정점이 없기 때문에; 따라서 노드 4는 아래와 같이 스택에서 팝아웃됩니다.


스택의 다음 최상위 요소는 2입니다. 이제 노드 2의 방문하지 않은 인접 정점을 살펴보겠습니다. 방문하지 않은 노드, 즉 5가 하나만 남아 있으므로 노드 5는 2 위의 스택에 푸시되고 인쇄됩니다. 아래 그림과 같이:

이제 아직 방문하지 않은 노드 5의 인접 정점을 확인하겠습니다. 방문할 정점이 남아 있지 않으므로 아래와 같이 스택에서 요소 5를 팝합니다.

5개 더 이상 이동할 수 없으므로 역추적을 수행해야 합니다. 역추적에서는 최상위 요소가 스택에서 팝아웃됩니다. 최상위 요소는 스택에서 튀어나오는 5이며, 아래와 같이 노드 2로 다시 이동합니다.

이제 노드 2의 방문하지 않은 인접 정점을 확인하겠습니다. 방문해야 할 인접 정점이 남아 있지 않으므로 역추적을 수행합니다. 역추적에서는 최상위 요소, 즉 2가 스택에서 튀어나오고 아래와 같이 노드 3으로 다시 이동합니다.


이제 노드 3의 방문하지 않은 인접 정점을 확인하겠습니다. 방문할 인접 정점이 남아 있지 않으므로 역추적을 수행합니다. 역추적에서는 최상위 요소, 즉 3이 스택에서 튀어나오고 아래와 같이 노드 1로 다시 이동합니다.
이진 트리와 이진 검색 트리의 차이점


요소 3을 팝아웃한 후 노드 1의 방문하지 않은 인접 정점을 확인합니다. 방문할 정점이 남아 있지 않기 때문에; 따라서 역추적이 수행됩니다. 역추적에서는 최상위 요소, 즉 1이 스택에서 튀어나오고 아래와 같이 노드 0으로 다시 이동합니다.


아직 방문하지 않은 노드 0의 인접 정점을 확인하겠습니다. 방문할 인접한 정점이 남아 있지 않으므로 역추적을 수행합니다. 여기서는 스택에 0이라는 하나의 요소만 아래와 같이 스택에서 팝아웃됩니다.

위 그림에서 알 수 있듯이 스택이 비어 있습니다. 따라서 여기서 DFS 탐색을 중지해야 하며 인쇄되는 요소는 DFS 탐색의 결과입니다.
BFS와 DFS의 차이점
BFS와 DFS의 차이점은 다음과 같습니다.
| BFS | DFS | |
|---|---|---|
| 전체 형태 | BFS는 너비 우선 검색을 나타냅니다. | DFS는 깊이 우선 탐색을 의미합니다. |
| 기술 | 그래프에서 최단 경로를 찾는 정점 기반 기술입니다. | 에지를 따라 있는 정점을 시작 노드부터 끝 노드까지 먼저 탐색하므로 에지 기반 기술입니다. |
| 정의 | BFS는 동일한 레벨의 모든 노드를 먼저 탐색한 후 다음 레벨로 이동하는 순회 기술입니다. | DFS는 루트 노드부터 순회를 시작하여 방문하지 않은 인접 노드가 없는 노드에 도달할 때까지 가능한 한 멀리 노드를 탐색하는 순회 기술이기도 합니다. |
| 데이터 구조 | 큐 데이터 구조는 BFS 순회에 사용됩니다. | 스택 데이터 구조는 BFS 탐색에 사용됩니다. |
| 역추적 | BFS는 역추적 개념을 사용하지 않습니다. | DFS는 역추적을 사용하여 방문하지 않은 모든 노드를 탐색합니다. |
| 모서리 수 | BFS는 소스에서 대상 정점까지 통과할 최소 개수의 간선을 갖는 최단 경로를 찾습니다. | DFS에서는 원본 정점에서 대상 정점으로 이동하는 데 더 많은 수의 간선이 필요합니다. |
| 최적성 | BFS 순회는 소스 정점에 더 가까운 정점을 검색하는 데 최적입니다. | DFS 순회는 솔루션이 소스 정점에서 멀리 떨어져 있는 그래프에 가장 적합합니다. |
| 속도 | BFS는 DFS보다 느립니다. | DFS는 BFS보다 빠릅니다. |
| 의사결정나무에 대한 적합성 | 모든 인접 노드를 먼저 탐색해야 하기 때문에 의사결정 트리에는 적합하지 않습니다. | 의사결정나무에 적합합니다. 결정에 따라 모든 경로를 탐색합니다. 목표가 발견되면 순회가 중지됩니다. |
| 메모리 효율성 | DFS보다 더 많은 메모리가 필요하므로 메모리 효율적이지 않습니다. | BFS보다 적은 메모리를 필요로 하므로 메모리 효율적입니다. |