분위수-분위수(q-q 플롯) 플롯은 데이터 세트가 특정 확률 분포를 따르는지 또는 두 데이터 샘플이 동일한 확률 분포를 따르는지 여부를 확인하기 위한 그래픽 방법입니다. 인구 아니면. Q-Q 플롯은 데이터 세트가 다음과 같은지 평가하는 데 특히 유용합니다. 정규 분포 또는 다른 알려진 분포를 따르는 경우. 통계, 데이터 분석 및 품질 관리에 일반적으로 사용되어 가정을 확인하고 예상 분포에서 벗어난 부분을 식별합니다.
분위수 및 백분위수
분위수는 데이터를 전체 분포의 동일한 확률 또는 비율을 포함하는 간격으로 나누는 데이터세트의 지점입니다. 데이터세트의 확산이나 분포를 설명하는 데 자주 사용됩니다. 가장 일반적인 분위수는 다음과 같습니다.
- 중앙값 (50번째 백분위수) : 중앙값은 데이터 세트를 가장 작은 것부터 큰 것 순으로 정렬했을 때 중간 값입니다. 데이터 세트를 두 개의 동일한 절반으로 나눕니다.
- 사분위수 (25번째, 50번째, 75번째 백분위수) : 사분위수는 데이터 세트를 4개의 동일한 부분으로 나눕니다. 첫 번째 사분위수(Q1)는 데이터의 25%가 아래에 속하는 값이고, 두 번째 사분위수(Q2)는 중앙값이며, 세 번째 사분위수(Q3)는 데이터의 75%가 아래에 속하는 값입니다.
- 백분위수 : 백분위수는 사분위수와 유사하지만 데이터 세트를 100개의 동일한 부분으로 나눕니다. 예를 들어, 90번째 백분위수는 데이터의 90%가 그 아래에 속하는 값입니다.
메모:
- q-q 플롯은 두 번째 데이터 세트의 분위수에 대한 첫 번째 데이터 세트의 분위수의 플롯입니다.
- 참고용으로 45% 선도 그려져 있습니다. 을 위한 표본이 동일한 모집단에서 나온 경우 점은 이 선을 따릅니다.
정규 분포:
정규 분포(일명 가우스 분포 벨 곡선)는 무작위로 생성된 실제 값에서 얻은 분포를 나타내는 연속 확률 분포입니다.
. 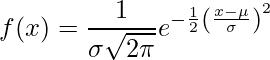

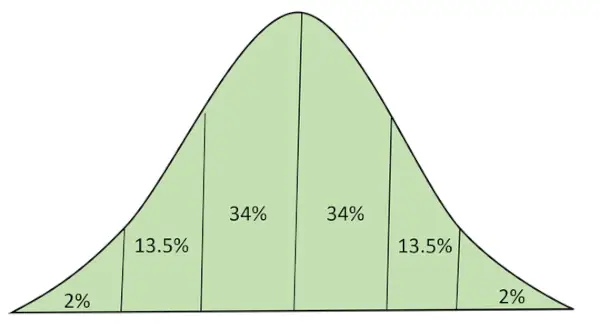
곡선 아래 면적이 있는 정규 분포
Q-Q 플롯을 그리는 방법은 무엇입니까?
Quantile-Quantile(Q-Q) 도표를 그리려면 다음 단계를 따르세요.
- 데이터 수집 : Q-Q 플롯을 생성하려는 데이터 세트를 수집합니다. 데이터가 숫자인지 확인하고 관심 모집단의 무작위 표본을 나타내십시오.
- 데이터 정렬 : 데이터를 오름차순 또는 내림차순으로 정렬합니다. 이 단계는 분위수를 정확하게 계산하는 데 필수적입니다.
- 이론적 분포 선택 : 데이터세트를 비교할 이론적 분포를 결정합니다. 일반적인 선택에는 정규 분포, 지수 분포 또는 데이터에 잘 맞는 기타 분포가 포함됩니다.
- 이론적 분위수 계산 : 선택한 이론적 분포에 대한 분위수를 계산합니다. 예를 들어, 정규 분포와 비교하는 경우 정규 분포의 역누적 분포 함수(CDF)를 사용하여 예상 분위수를 찾습니다.
- 플로팅 :
- X축에 정렬된 데이터세트 값을 표시합니다.
- 해당 이론적 분위수를 y축에 표시합니다.
- 각 데이터 포인트(x, y)는 관찰된 값과 예상된 값의 쌍을 나타냅니다.
- 데이터 포인트를 연결하여 데이터 세트와 이론적 분포 간의 관계를 시각적으로 검사합니다.
Q-Q 플롯의 해석
- 도표의 점들이 대략 직선을 따르는 경우 데이터세트가 가정된 분포를 따른다는 의미입니다.
- 직선으로부터의 편차는 가정된 분포에서 벗어났음을 의미하므로 추가 조사가 필요합니다.
Q-Q 플롯으로 분포 유사성 탐색
Q-Q 플롯을 사용하여 분포 유사성을 탐색하는 것은 통계의 기본 작업입니다. 두 데이터 세트를 비교하여 동일한 분포에서 유래했는지 확인하는 것은 다양한 분석 목적에 필수적입니다. 공통 분포 가정이 유지되는 경우 데이터 세트를 병합하면 위치 및 규모와 같은 매개변수 추정 정확도가 향상될 수 있습니다. 분위수-분위수 플롯의 약자인 Q-Q 플롯은 분포 유사성을 평가하기 위한 시각적 방법을 제공합니다. 이 도표에서는 한 데이터세트의 분위수가 다른 데이터세트의 분위수에 대해 표시됩니다. 점들이 대각선을 따라 밀접하게 정렬되어 있으면 분포 간의 유사성을 나타냅니다. 이 대각선으로부터의 편차는 분포 특성의 차이를 나타냅니다.
다음과 같은 테스트를 하는 동안 카이제곱 그리고 콜모고로프-스미르노프 테스트는 전반적인 분포 차이를 평가할 수 있으며, Q-Q 플롯은 분위수를 직접 비교하여 미묘한 관점을 제공합니다. 이를 통해 분석가는 공식적인 통계 테스트만으로는 명확하지 않을 수 있는 위치 이동이나 규모 변화와 같은 구체적인 차이점을 식별할 수 있습니다.
Q-Q 플롯의 Python 구현
파이썬3
import> numpy as np> import> matplotlib.pyplot as plt> import> scipy.stats as stats> # Generate example data> np.random.seed(>0>)> data>=> np.random.normal(loc>=>0>, scale>=>1>, size>=>1000>)> # Create Q-Q plot> stats.probplot(data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Normal Q-Q plot'>)> plt.xlabel(>'Theoretical quantiles'>)> plt.ylabel(>'Ordered Values'>)> plt.grid(>True>)> plt.show()> |
>
>
산출:
Q-Q 플롯
여기서 데이터 포인트는 Q-Q 플롯에서 대략 직선을 따르므로 데이터 세트가 가정된 이론적 분포(이 경우 정규 분포라고 가정)와 일치함을 나타냅니다.
Q-Q 플롯의 장점
- 유연한 비교 : Q-Q 플롯은 다양한 크기의 데이터세트를 별도의 데이터 없이 비교할 수 있습니다. 동일한 표본 크기가 필요합니다.
- 무차원 분석 : 차원이 없으므로 데이터 세트를 비교하는 데 적합합니다. 단위나 척도가 다릅니다.
- 시각적 해석 : 이론적 분포와 비교하여 데이터 분포를 명확하게 시각적으로 표현합니다.
- 편차에 민감 : 가정된 분포로부터의 이탈을 쉽게 감지하여 데이터 불일치를 식별하는 데 도움이 됩니다.
- 진단 도구 : 분포 가정 평가, 이상값 식별, 데이터 패턴 이해에 도움이 됩니다.
분위수-분위수 도표의 응용
Quantile-Quantile 도표는 다음 목적으로 사용됩니다.
- 분포 가정 평가 : Q-Q 플롯은 데이터 세트가 정규 분포와 같은 특정 확률 분포를 따르는지 여부를 시각적으로 검사하는 데 자주 사용됩니다. 관측된 데이터의 분위수를 가정된 분포의 분위수와 비교함으로써 가정된 분포와의 편차를 감지할 수 있습니다. 이는 분포 가정의 타당성이 통계적 추론의 정확성에 영향을 미치는 많은 통계 분석에서 매우 중요합니다.
- 이상값 감지 : 이상값은 데이터 세트의 나머지 부분에서 크게 벗어나는 데이터 포인트입니다. Q-Q 플롯은 예상되는 분포 패턴에서 멀리 떨어진 데이터 포인트를 밝혀 이상값을 식별하는 데 도움이 될 수 있습니다. 이상값은 플롯의 예상 직선에서 벗어나는 점으로 나타날 수 있습니다.
- 분포 비교 : Q-Q 플롯을 사용하면 두 데이터 세트를 비교하여 동일한 분포에서 나온 것인지 확인할 수 있습니다. 이는 한 데이터세트의 분위수를 다른 데이터세트의 분위수와 비교하여 표시함으로써 달성됩니다. 점이 대략 직선을 따라 있으면 두 데이터 세트가 동일한 분포에서 추출되었음을 의미합니다.
- 정규성 평가 : Q-Q 플롯은 데이터 세트의 정규성을 평가하는 데 특히 유용합니다. 플롯의 데이터 포인트가 직선을 밀접하게 따르는 경우 데이터세트가 대략적으로 정규 분포를 따른다는 것을 나타냅니다. 선의 편차는 정규성에서 벗어났음을 의미하며, 이를 위해서는 추가 조사나 비모수적 통계 기법이 필요할 수 있습니다.
- 모델 검증 : 계량경제학 및 기계 학습과 같은 분야에서는 Q-Q 플롯이 예측 모델을 검증하는 데 사용됩니다. 관찰된 반응의 분위수를 모델에서 예측한 분위수와 비교함으로써 모델이 데이터에 얼마나 잘 맞는지 평가할 수 있습니다. 예상 패턴과의 편차는 모델 개선이 필요한 영역을 나타낼 수 있습니다.
- 품질 관리 : Q-Q 플롯은 시간 경과에 따라 또는 여러 배치에 걸쳐 측정되거나 관찰된 값의 분포를 모니터링하기 위해 품질 관리 프로세스에 사용됩니다. 플롯의 예상 패턴에서 벗어나면 기본 프로세스의 변화를 알리고 추가 조사가 필요할 수 있습니다.
Q-Q 플롯의 유형
통계 및 데이터 분석에 일반적으로 사용되는 여러 유형의 Q-Q 플롯이 있으며 각각 다른 시나리오 또는 목적에 적합합니다.
- 정규 분포 : 데이터가 정규 분포를 따르는 경우 Q-Q 플롯이 대략 대각선을 따라 점을 표시하는 대칭 분포입니다.
- 오른쪽으로 치우친 분포 : Q-Q 플롯이 관측된 분위수가 직선에서 위쪽 끝으로 벗어나는 패턴을 표시하는 분포로, 오른쪽에 더 긴 꼬리가 있음을 나타냅니다.
- 왼쪽으로 치우친 분포 : Q-Q 플롯이 관찰된 분위수가 직선에서 아래쪽 끝으로 벗어나는 패턴을 나타내는 분포로, 이는 왼쪽에 더 긴 꼬리가 있음을 나타냅니다.
- 과소분산 분포 : Q-Q 플롯이 관측된 분위수를 이론적 분위수에 비해 대각선 주위에 더 촘촘하게 모여 표시하는 분포로, 이는 더 낮은 분산을 나타냅니다.
- 과분산된 분포 : Q-Q 플롯에서 관측된 분위수가 대각선에서 더 많이 퍼지거나 벗어나는 것으로 표시되는 분포로, 이는 이론적인 분포에 비해 더 높은 분산 또는 분산을 나타냅니다.
파이썬3
import> numpy as np> import> matplotlib.pyplot as plt> import> scipy.stats as stats> # Generate a random sample from a normal distribution> normal_data>=> np.random.normal(loc>=>0>, scale>=>1>, size>=>1000>)> # Generate a random sample from a right-skewed distribution (exponential distribution)> right_skewed_data>=> np.random.exponential(scale>=>1>, size>=>1000>)> # Generate a random sample from a left-skewed distribution (negative exponential distribution)> left_skewed_data>=> ->np.random.exponential(scale>=>1>, size>=>1000>)> # Generate a random sample from an under-dispersed distribution (truncated normal distribution)> under_dispersed_data>=> np.random.normal(loc>=>0>, scale>=>0.5>, size>=>1000>)> under_dispersed_data>=> under_dispersed_data[(under_dispersed_data>>->1>) & (under_dispersed_data <>1>)]># Truncate> # Generate a random sample from an over-dispersed distribution (mixture of normals)> over_dispersed_data>=> np.concatenate((np.random.normal(loc>=>->2>, scale>=>1>, size>=>500>),> >np.random.normal(loc>=>2>, scale>=>1>, size>=>500>)))> # Create Q-Q plots> plt.figure(figsize>=>(>15>,>10>))> plt.subplot(>2>,>3>,>1>)> stats.probplot(normal_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Normal Distribution'>)> plt.subplot(>2>,>3>,>2>)> stats.probplot(right_skewed_data, dist>=>'expon'>, plot>=>plt)> plt.title(>'Q-Q Plot - Right-skewed Distribution'>)> plt.subplot(>2>,>3>,>3>)> stats.probplot(left_skewed_data, dist>=>'expon'>, plot>=>plt)> plt.title(>'Q-Q Plot - Left-skewed Distribution'>)> plt.subplot(>2>,>3>,>4>)> stats.probplot(under_dispersed_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Under-dispersed Distribution'>)> plt.subplot(>2>,>3>,>5>)> stats.probplot(over_dispersed_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Over-dispersed Distribution'>)> plt.tight_layout()> plt.show()> |
>
>
산출:
다양한 분포에 대한 Q-Q 플롯
자바 프로그래밍 소수